
Fine-Tuning Cohere's Reranker
Introduction
Search engines and retrieval augmented generation (RAG) applications rely heavily on retrieval accuracy. There are many techniques for achieving highly accurate retrieval. One of the most common patterns we’ve seen is multi-stage search. Typically this is in two stages: 1. Gather the relevant objects with the first-stage retriever 2. Send the relevant objects to the reranker to improve the output. Adding reranking to the second-stage is a quick and effective method to boost search relevance.
In version 1.20, Weaviate introduced the ability to run reranking at the second stage. To get started, Weaviate developers simply need to add one line of code to their schema reranker-cohere:
schema = {
"class": "BlogsFineTuned",
"description": "Weaviate blogs",
"vectorizer": "text2vec-cohere",
"moduleConfig": {
"reranker-cohere": {
"model": "rerank-multilingual-v2.0"
}
}
}
Weaviate developers also have the flexibility to choose two reranking models out of the box:
rerank-english-v2.0rerank-multilingual-v2.0
Now you have a third option to pass in your fine-tuned reranker model! In this blog post, I will show you how to fine-tune Cohere’s reranker model.
Cohere Rerank Endpoint
In May 2023, Cohere released their rerank endpoint. It enabled users to build search systems that added reranking at the last stage.
Then in December of 2023, Cohere announced the ability to fine-tune their rerank endpoint. Fine-tuning boosts the model’s performance, especially in unique domains. Here is a screenshot of the pricing page. Both the zero-shot and fine-tuned models are priced at $1 per 1,000 queries (at the time of writing this blog post).
Fine-tuning a reranker on domain specific data can enhance the precision and relevance of search results. It enables the model to better understand and align with the complexities and phrases of specific terminology.
In this demo, we’re fine-tuning the model on the Weaviate blogs dataset. Using the Weaviate blogs to fine-tune the reranker, enables the model to grasp and prioritize the unique terminology. This approach ensures that the reranker becomes skilled at identifying content that is most relevant to queries, like "What is Ref2Vec." This will improve the performance of the search system by narrowing the focus to this particular information.
Demo
You can clone the repository here to follow along!
I’m using the Cohere, DSPy, and Weaviate tech stack for this demo. Please do the following:
- Make sure you have Weaviate, Cohere, and DSPy installed —
pip install weaviate-client dspy-ai cohere - Have a Weaviate cluster — you can create a 14-day free sandbox or run Embedded Weaviate (other installation options)
- Generate a Cohere API key
The total cost for this demo was $0.03 — this includes the vectorization and a few rerank inference.
Connect to your Weaviate Instance and Load your Data
This demo uses the Python v3 client, however, there is a new and improved v4 client! I will migrate this demo to use the v4 client - here is a guide on how to do so.
First we’ll need to connect to our Weaviate cluster:
import weaviate
import json
client = weaviate.Client(
url = "WEAVIATE_URL", # Replace with your cluster url
auth_client_secret=weaviate.AuthApiKey(api_key="WEAVIATE_AUTH_KEY"), # Replace with your Weaviate instance API key
additional_headers = {
"X-Cohere-Api-Key": "API_KEY" # Replace with your inference API key
}
)
Read in each markdown file and chunk the blog after five sentences:
import os
import re
def chunk_list(lst, chunk_size):
"""Break a list into chunks of the specified size."""
return [lst[i:i + chunk_size] for i in range(0, len(lst), chunk_size)]
def split_into_sentences(text):
"""Split text into sentences using regular expressions."""
sentences = re.split(r'(?<!\w\.\w.)(?<![A-Z][a-z]\.)(?<=\.|\?)\s', text)
return [sentence.strip() for sentence in sentences if sentence.strip()]
def read_and_chunk_index_files(main_folder_path):
"""Read index.md files from subfolders, split into sentences, and chunk every 5 sentences."""
blog_chunks = []
for folder_name in os.listdir(main_folder_path):
subfolder_path = os.path.join(main_folder_path, folder_name)
if os.path.isdir(subfolder_path):
index_file_path = os.path.join(subfolder_path, 'index.mdx')
if os.path.isfile(index_file_path):
with open(index_file_path, 'r', encoding='utf-8') as file:
content = file.read()
sentences = split_into_sentences(content)
sentence_chunks = chunk_list(sentences, 5)
sentence_chunks = [' '.join(chunk) for chunk in sentence_chunks]
blog_chunks.extend(sentence_chunks)
return blog_chunks
# Example usage
main_folder_path = './blog'
blogs = read_and_chunk_index_files(main_folder_path)
Generate Synthetic Data with DSPy
To fine-tune a model, we need the proper training dataset. Since I didn’t have a dataset that contains a query + relevant passage pair, I decided to use DSPy to solve this. If you already have a dataset that contains at least 256 query + relevant passages you can skip to the Re-Index Data section!
Define the Schema
To upload data to Weaviate, you will need to define your schema first. We will use the text2vec-cohere module to vectorize our blog chunks. The Blogs collection, will have two properties: content and synthetic_query.
schema = {
"classes": [
{
"class": "Blogs",
"description": "Weaviate blogs",
"vectorizer": "text2vec-cohere",
"properties": [
{
"name": "content",
"dataType": ["text"],
"description": "Content from the blogs.",
},
{
"name": "synthetic_query",
"dataType": ["text"],
"description": "Synthetic query generated from a LM."
}
]
}
]
}
client.schema.create(schema)
If you need to reset your schema and delete objects in a collection, run:
client.schema.delete_all() or client.schema.delete_class("Blogs")
Synthetic Queries
We are using DSPy’s signature and chain-of-thought module to generate synthetic queries using Cohere’s command-nightly model. The signature implements the prompt that: 1. Describes the task, 2. Gives an example of the input and output fields and 3. Prompts the model to reason before answering. As DSPy is generating the synthetic queries, we will upload it to our instance:
import dspy
import cohere
cohere_key = "api-key"
class WriteQuery(dspy.Signature):
"""Write a query that this document would have the answer to."""
document = dspy.InputField(desc="A document containing information.")
query = dspy.OutputField(desc="A short question uniquely answered by the document.")
command_nightly = dspy.Cohere(model="command-nightly",max_tokens=1000, api_key=cohere_key)
for blog_chunk in blogs:
with dspy.context(lm=command_nightly):
llm_query = dspy.ChainOfThought(WriteQuery)(document=blog_chunk)
print(llm_query)
data_properties = {
"content": blog_chunk,
"synthetic_query": llm_query.query
}
print(f"{data_properties}\n")
client.data_object.create(data_properties, "Blogs")
Here is an example of the prompt and generation (produce is the first word sampled from the LLM as it writes the reasoning and then the query):
Input:
with dspy.context(lm=command_nightly):
dspy.ChainOfThought(WriteQuery)(document=blogs[0]).query
command_nightly.inspect_history(n=1)
Output of the first object
Write a query that this document would have the answer to.
---
Follow the following format.
Document: A document containing information.
Reasoning: Let's think step by step in order to ${produce the query}. We ...
Query: A short question uniquely answered by the document.
---
Document: --- title: Combining LangChain and Weaviate slug: combining-langchain-and-weaviate authors: [erika] date: 2023-02-21 tags: ['integrations'] image: ./img/hero.png description: "LangChain is one of the most exciting new tools in AI. It helps overcome many limitations of LLMs, such as hallucination and limited input lengths." ---  Large Language Models (LLMs) have revolutionized the way we interact and communicate with computers. These machines can understand and generate human-like language on a massive scale. LLMs are a versatile tool that is seen in many applications like chatbots, content creation, and much more. Despite being a powerful tool, LLMs have the drawback of being too general.
Reasoning: Let's think step by step in order to **produce the query. We need to identify the unique aspects of the document that would allow us to formulate a question that this document can answer. The document seems to focus on the combination of LangChain and Weaviate, mentioning the benefits of LangChain in overcoming limitations of LLMs such as hallucination and limited input lengths. It also provides a date, author, and tags related to integrations. Given this information, we can create a query that asks about the purpose of combining LangChain with Weaviate, as this is a specific topic that the document addresses.
Query: What are the benefits of combining LangChain with Weaviate in the context of LLMs?
Grab Data out of Weaviate
Now that we have the synthetic query + relevant chunk, we can export the data to fine-tune the model. We’ll grab 80% of the objects for training and 20% for validation.
'''
This example will show you how to get all of your data
out of Weaviate and into a JSON file using the Cursor API!
'''
import time
start = time.time()
# Step 1 - Get the UUID of the first object inserted into Weaviate
get_first_object_weaviate_query = """
{
Get {
Blogs {
_additional {
id
}
}
}
}
"""
results = client.query.raw(get_first_object_weaviate_query)
uuid_cursor = results["data"]["Get"]["Blogs"][0]["_additional"]["id"]
# Step 2 - Get the Total Objects in Weaviate
total_objs_query = """
{
Aggregate {
Blogs {
meta {
count
}
}
}
}
"""
results = client.query.raw(total_objs_query)
total_objects = results["data"]["Aggregate"]["Blogs"][0]["meta"]["count"]
# Step 3 - Iterate through Weaviate with the Cursor
increment = 50
data = []
for i in range(0, total_objects, increment):
results = (
client.query.get("Blogs", ["content", "synthetic_query"])
.with_additional(["id"])
.with_limit(50)
.with_after(uuid_cursor)
.do()
)["data"]["Get"]["Blogs"]
# extract data from result into JSON
for result in results:
if len(result["synthetic_query"]) < 5:
continue
new_obj = {}
for key in result.keys():
if key == "_additional":
continue
if key == "synthetic_query":
new_obj["query"] = result[key]
if key == "content":
new_obj["relevant_passages"] = [result[key]]
data.append(new_obj)
# update uuid cursor to continue the loop
# we have just exited a loop where result holds the last obj
uuid_cursor = result["_additional"]["id"]
# save JSON
file_path = "data.jsonl"
with open(file_path, 'w') as jsonl_file:
for item in data:
jsonl_file.write(json.dumps(item) + '\n')
print("Your data is out of Weaviate!")
print(f"Extracted {total_objects} in {time.time() - start} seconds.")
Separate the data into the 80/20 split:
data = []
with open("data.jsonl", "r") as file:
for line in file:
data.append(json.loads(line))
split_index = int(len(data)*0.8)
train_data = data[:split_index]
validation_data = data[split_index:]
with open("./train.jsonl", "w") as train_file:
for line in train_data:
train_file.write(json.dumps(line) + "\n")
with open("./validation.jsonl", "w") as validation_file:
for line in validation_data:
validation_file.write(json.dumps(line) + "\n")
Fine-Tune the Reranker in Cohere
By now, you should have your training and validation dataset. We can now go to Cohere’s dashboard and navigate to Create a Rerank Model. There are a few requirements to follow before your model is training:
- Have at least 256 unique queries
- At least 1 relevant passage per query
- You can include hard negatives for each query (this is optional)
- Make sure the text in the relevant passages is different from the hard negatives for the same query
- At least 64 unique queries for the validation dataset (can’t have overlap from the training set)
If you followed the previous section, we have satisfied the first, second, and fifth requirements. You can simply upload the training and validation files and click on Review data.
It may take a few hours for the model to be ready — it took 2 hours for me. Keep an eye out for an email stating your model is ready. You will see the model_id under the API section (screenshot below). Cohere provides an amazing dashboard that covers shows your models performance.
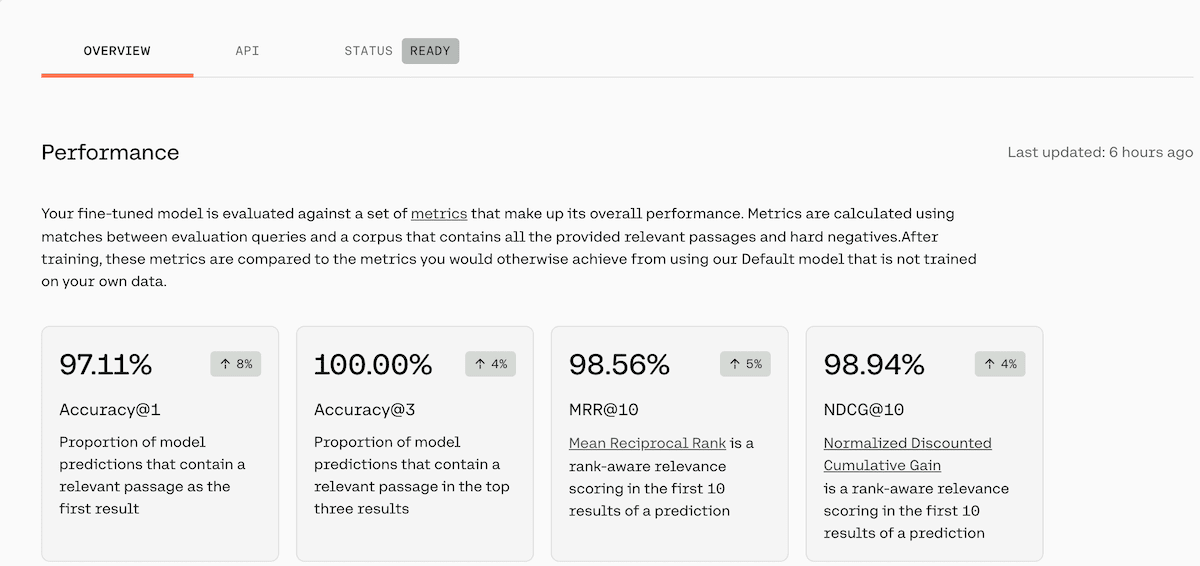
It is reporting four metrics and comparing it to the performance of the default model. In our case, there was an 8% boost in Accuracy@1, 4% boost in Accuracy@3, 5% boost in MRR@10, and 4% boost in NDCG@10.
Re-Index Data
To use our fine-tuned reranker, we will need to upload our data again to a new collection and add the model_id path.
Schema
schema = {
"classes": [
{
"class": "BlogsFineTuned",
"description": "Weaviate blogs",
"vectorizer": "text2vec-cohere",
"moduleConfig": {
"reranker-cohere": {
"model": "model_id" # grab the model_id from Cohere
}
},
"properties": [
{
"name": "content",
"dataType": ["text"],
"description": "Content from the blogs.",
}
]
}
]
}
client.schema.create(schema)
Import
Import the blog chunks to the new collection:
for blog in blogs:
data_properties = {
"content": blog
}
client.data_object.create(
data_object = data_properties,
class_name = "BlogsFineTuned"
)
We are working on a solution to avoid re-indexing your data. You can leave your feedback on this GitHub issue!
Query Time
Now it’s time to query our database and use the reranker! Please confirm you’re referencing the collection that has the fine-tuned model.
Query without Reranking
response = (
client.query
.get("BlogsFineTuned", ["content"])
.with_near_text({
"concepts": ["Ref2Vec in Weaviate"]
})
.with_limit(5)
.do()
)
print(json.dumps(response, indent=2))
Output
{
"data": {
"Get": {
"BlogsFineTuned": [
{
"content": "---\ntitle: What is Ref2Vec and why you need it for your recommendation system\nslug: ref2vec-centroid\nauthors: [connor]\ndate: 2022-11-23\ntags: ['integrations', 'concepts']\nimage: ./img/hero.png\ndescription: \"Weaviate introduces Ref2Vec, a new module that utilises Cross-References for Recommendation!\"\n---\n\n\n<!-- truncate -->\n\nWeaviate 1.16 introduced the [Ref2Vec](https://docs.weaviate.io/weaviate/modules/ref2vec-centroid) module. In this article, we give you an overview of what Ref2Vec is and some examples in which it can add value such as recommendations or representing long objects. ## What is Ref2Vec? The name Ref2Vec is short for reference-to-vector, and it offers the ability to vectorize a data object with its cross-references to other objects. The Ref2Vec module currently holds the name ref2vec-**centroid** because it uses the average, or centroid vector, of the cross-referenced vectors to represent the **referencing** object."
},
{
"content": "In other words, the User vector is being updated in real-time here to take into account their preferences and actions, which helps to produce more relevant results at speed. Another benefit of Ref2Vec is that this calculation is not compute-heavy, leading to low overhead. With Ref2Vec, you can use Weaviate to provide Recommendation with \"user-as-query\". This is a very common and powerful way to build Home Feed style features in apps. This can be done by sending queries like this to Weaviate:\n\n```graphql\n{\n Get {\n Product (\n nearObject: {\n id: \"8abc5-4d5...\" # id for the User object with vector defined by ref2vec-centroid\n }\n ) {\n product_name\n price\n }\n }\n}\n```\n\nThis short query encapsulates the power of Ref2Vec."
},
{
"content": "\n\nRef2Vec gives Weaviate another way to vectorize a class, such as the User class, based on their relationships to other classes. This allows Weaviate to quickly create up-to-date representations of users based on their relationships such as recent interactions. If a user clicks on 3 shoe images on an e-commerce store, it is a safe bet that they want to see more shoes. Ref2Vec captures this intuition by calculating vectors that aggregate each User's interaction with another class. The below animation visualizes a real example of this in e-Commerce images."
},
{
"content": "The following image depicts how Ref2Vec aggregates the representations of 3 Product items to represent a User who has purchased a pair of boots, shorts, and Weaviate t-shirt!\n\n\n\nSuch a representation of the User, by an aggregation of their cross-references, allows Weaviate to conveniently and immediately learn from each User's preferences and actions to provide improved and up-to-date characterizations. Ref2Vec can in other words capture each User's interests and tendencies across multiple axes, such as product categories or even fashion styles! And by doing so, the resulting recommendations can more closely match the User's product and style preferences. We envision Ref2Vec to have great potential in multiple application areas. Let's take a look at a few of them in more detail, starting with recommendation systems. ## Recommendation in Weaviate\nMany of you might primarily know Weaviate as a vector database and search engine, but Weaviate can also power high-quality, lightning-fast recommendations."
},
{
"content": "## More Coming Soon\nWe are very excited about the potential of Ref2Vec, and how it leverages existing symbolic data to augment vector searches in a new way. One of my favorite articles about Weaviate is Bob van Luijt's [\"The AI-First Database Ecosystem\"](/blog/semantic-search-with-wikipedia-and-weaviate). In this article, Bob describes emerging **waves** of database technology; from SQL, to NoSQL, and now, AI-first databases that focus \"on data that is processed by a machine learning model first, where the AI models help in processing, storing and searching through the data as opposed to traditional ways\". Although Weaviate puts Machine Learning data representations first, **this doesn't mean we discard symbolic data and many features of previous systems**. Rather, we are actively searching for how symbolic data can improve neural functionality and vice versa."
}
]
}
}
}
Query with Reranking
response = (
client.query
.get("BlogsFineTuned", ["content"])
.with_near_text({
"concepts": ["Ref2Vec in Weaviate"]
})
.with_additional("rerank(property: \"content\" query: \"Represent users based on their product interactions\") { score }")
.with_limit(5)
.do()
)
print(json.dumps(response, indent=2))
Output
{
"data": {
"Get": {
"BlogsFineTuned": [
{
"_additional": {
"rerank": [
{
"score": 0.9261703
}
]
},
"content": "\n\nRef2Vec gives Weaviate another way to vectorize a class, such as the User class, based on their relationships to other classes. This allows Weaviate to quickly create up-to-date representations of users based on their relationships such as recent interactions. If a user clicks on 3 shoe images on an e-commerce store, it is a safe bet that they want to see more shoes. Ref2Vec captures this intuition by calculating vectors that aggregate each User's interaction with another class. The below animation visualizes a real example of this in e-Commerce images."
},
{
"_additional": {
"rerank": [
{
"score": 0.34444344
}
]
},
"content": "The following image depicts how Ref2Vec aggregates the representations of 3 Product items to represent a User who has purchased a pair of boots, shorts, and Weaviate t-shirt!\n\n\n\nSuch a representation of the User, by an aggregation of their cross-references, allows Weaviate to conveniently and immediately learn from each User's preferences and actions to provide improved and up-to-date characterizations. Ref2Vec can in other words capture each User's interests and tendencies across multiple axes, such as product categories or even fashion styles! And by doing so, the resulting recommendations can more closely match the User's product and style preferences. We envision Ref2Vec to have great potential in multiple application areas. Let's take a look at a few of them in more detail, starting with recommendation systems. ## Recommendation in Weaviate\nMany of you might primarily know Weaviate as a vector database and search engine, but Weaviate can also power high-quality, lightning-fast recommendations."
},
{
"_additional": {
"rerank": [
{
"score": 0.007121429
}
]
},
"content": "In other words, the User vector is being updated in real-time here to take into account their preferences and actions, which helps to produce more relevant results at speed. Another benefit of Ref2Vec is that this calculation is not compute-heavy, leading to low overhead. With Ref2Vec, you can use Weaviate to provide Recommendation with \"user-as-query\". This is a very common and powerful way to build Home Feed style features in apps. This can be done by sending queries like this to Weaviate:\n\n```graphql\n{\n Get {\n Product (\n nearObject: {\n id: \"8abc5-4d5...\" # id for the User object with vector defined by ref2vec-centroid\n }\n ) {\n product_name\n price\n }\n }\n}\n```\n\nThis short query encapsulates the power of Ref2Vec."
},
{
"_additional": {
"rerank": [
{
"score": 5.5508026e-06
}
]
},
"content": "---\ntitle: What is Ref2Vec and why you need it for your recommendation system\nslug: ref2vec-centroid\nauthors: [connor]\ndate: 2022-11-23\ntags: ['integrations', 'concepts']\nimage: ./img/hero.png\ndescription: \"Weaviate introduces Ref2Vec, a new module that utilises Cross-References for Recommendation!\"\n---\n\n\n<!-- truncate -->\n\nWeaviate 1.16 introduced the [Ref2Vec](https://docs.weaviate.io/weaviate/modules/ref2vec-centroid) module. In this article, we give you an overview of what Ref2Vec is and some examples in which it can add value such as recommendations or representing long objects. ## What is Ref2Vec? The name Ref2Vec is short for reference-to-vector, and it offers the ability to vectorize a data object with its cross-references to other objects. The Ref2Vec module currently holds the name ref2vec-**centroid** because it uses the average, or centroid vector, of the cross-referenced vectors to represent the **referencing** object."
},
{
"_additional": {
"rerank": [
{
"score": 4.7478566e-06
}
]
},
"content": "## More Coming Soon\nWe are very excited about the potential of Ref2Vec, and how it leverages existing symbolic data to augment vector searches in a new way. One of my favorite articles about Weaviate is Bob van Luijt's [\"The AI-First Database Ecosystem\"](/blog/semantic-search-with-wikipedia-and-weaviate). In this article, Bob describes emerging **waves** of database technology; from SQL, to NoSQL, and now, AI-first databases that focus \"on data that is processed by a machine learning model first, where the AI models help in processing, storing and searching through the data as opposed to traditional ways\". Although Weaviate puts Machine Learning data representations first, **this doesn't mean we discard symbolic data and many features of previous systems**. Rather, we are actively searching for how symbolic data can improve neural functionality and vice versa."
}
]
}
}
}
My query was about the Ref2Vec feature in Weaviate. Without reranking, the objects were about Ref2Vec, but it wasn’t in detail about the module. In the reranking query, I first searched for concepts about Ref2Vec and then reranked the objects that were about how users are represented by their product interactions.
As you can see, the output is different for each query. The first object from pure vector search outputted the first chunk from the Ref2Vec blog post, which is relevant but doesn’t answer my query. The query with reranking went into depth on how Ref2Vec gives Weaviate another way to vectorize a class.
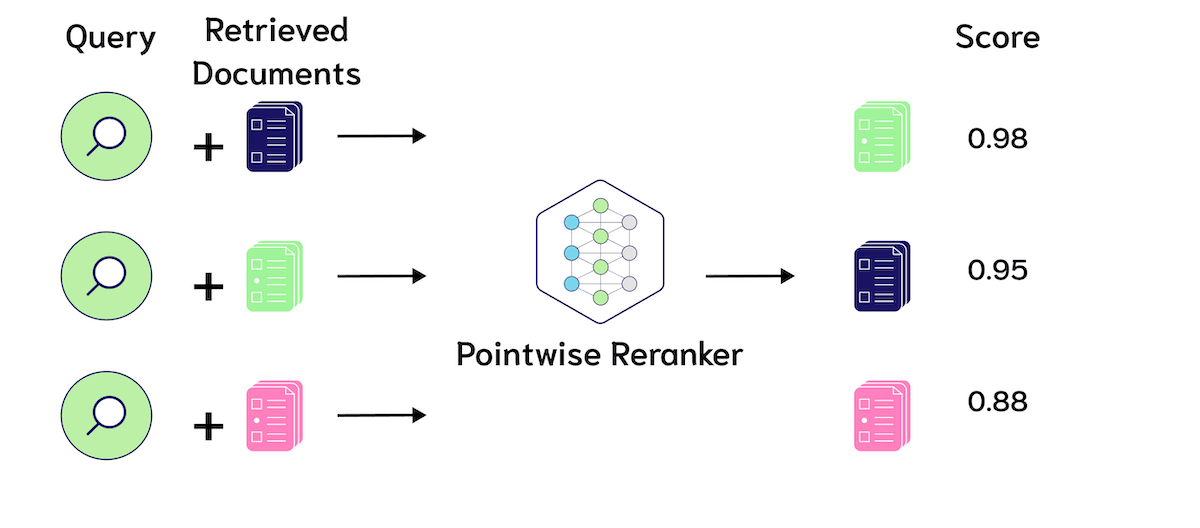
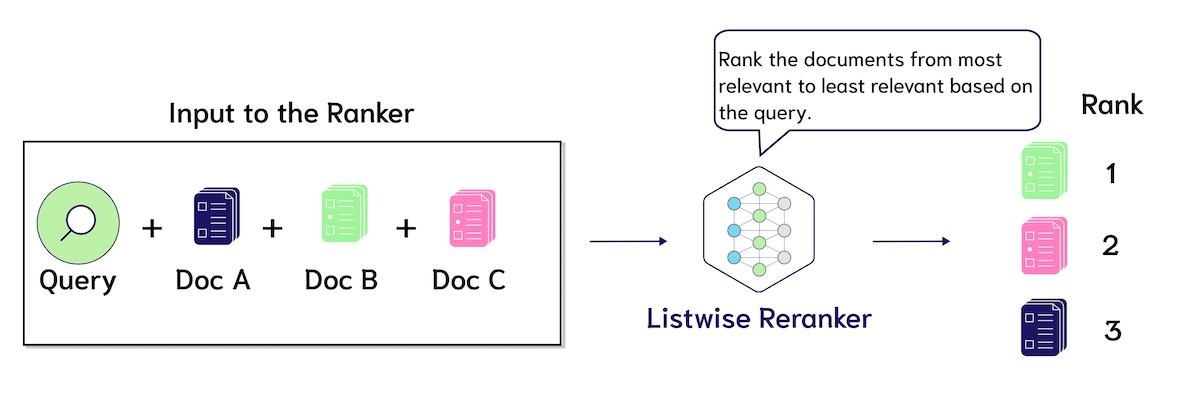
Pointwise versus Listwise Reranking
The reranker model described in this blog post is a pointwise reranker. Pointwise rerankers take as input the query and each candidate document, separately, and output a relevance score. Another interesting opportunity for ranking models are listwise rerankers. Listwise rerankers take as input the query and all the candidate documents at once as input, and output a reranked list!
Here is a quick summary I made on RankZephyr, where Pradeep et al. trained a 7 billion parameter LLM to copy outputs from a two-stage training process with GPT-3.5 and GPT-4.
Stay tuned as we continue to investigate supporting these models in Weaviate and the emerging research landscape!
Conclusion
This blog post walked you through how to generate synthetic data using DSPy, fine-tune Cohere’s reranker, and run a vector search query with reranking in Weaviate!
If you’d like to learn more about DSPy, check out this DSPy Explained(https://www.youtube.com/watch?v=41EfOY0Ldkc) video from Connor Shorten.
Ready to start building?
Check out the Quickstart tutorial, or sign up for a free Weaviate Cloud account.
Don't want to miss another blog post?
Sign up for our bi-weekly newsletter to stay updated!
By submitting, I agree to the Terms of Service and Privacy Policy.