
Combining LangChain and Weaviate

Large Language Models (LLMs) have revolutionized the way we interact and communicate with computers. These machines can understand and generate human-like language on a massive scale. LLMs are a versatile tool that is seen in many applications like chatbots, content creation, and much more. Despite being a powerful tool, LLMs have the drawback of being too general. Fortunately, there are emerging technologies that help solve this limitation.
LangChain is one of the most exciting new tools in AI. LangChain helps overcome many limitations of LLMs such as hallucination and limited input lengths. Hallucination refers to where the LLM generates a response that is not supported by the input or context – meaning it will output text that is irrelevant, inconsistent, or misleading. As you can imagine, this is a huge problem in many applications. LLMs have a limited input length when referring to the scale of inputting a book or pages of search results. LangChain has various techniques implemented to solve this problem.
This blog post will begin by explaining some of the key concepts introduced in LangChain and end with a demo. The demo will show you how to combine LangChain and Weaviate to build a custom LLM chatbot powered with semantic search!
Sequential Chains
Chains enable us to combine multiple LLM inferences together. As you can guess from the name, sequential chains execute their links in a sequential order. It takes one input/output and then uses the output for the next step.
Let’s look at an example of sequential chains in a conversation between the bot and me. This visualization shows an example of a step-by-step reasoning to fact check an LLM tasked with question answering:

All credit to jagilley for creating this awesome example
When we ask an LLM, “What type of mammal lays the biggest eggs?”, it initially answers “The biggest eggs laid by any mammal belong to the elephant.” This is a clear example of hallucination, where the response is misleading and incorrect. By adding in a simple chain of asking the LLM to reason about its assumptions, we are able to fix the hallucination problem.
CombineDocuments
LLMs have a limited token length due to various practical and technical constraints. One of the primary reasons is the computational cost associated with processing and storing longer sequences of tokens. The longer the sequence, the more memory and processing power required to operate on it, which can be a significant challenge for even the most powerful computing systems.
The relatively long input window of LLMs is what drives the integration with semantic search. For example, we can use this entire blog post as input in addition to questions if we want the LLM to answer questions such as “What are LLM Chains?” However, when we want to give the LLM an entire book or pages of search results, we need more clever techniques to decompose this task. This is where the CombineDocuments chain comes to play! Note, that one method is not better than another, and the performance is dependent solely on your application.
Stuffing

Stuffing takes the related documents from the database and stuffs them into the prompt. The documents are passed in as context and go into the language model (the robot). This is the simplest method since it doesn’t require multiple calls to the LLM. This can be seen as a disadvantage if the documents are too long and surpass the context length.
Map Reduce

Map Reduce applies an initial prompt to each chunk of data. This is then passed through the language model to generate multiple responses. Another prompt is created to combine all of the initial outputs into one. This technique requires more than one call to the LLM.
Refine

Refine is a unique technique because it has a local memory. An example of this is to ask the language model to summarize the documents one by one. It then takes the summaries generated so far to influence the next output. It repeats this process until all documents have been processed.
Map Rerank
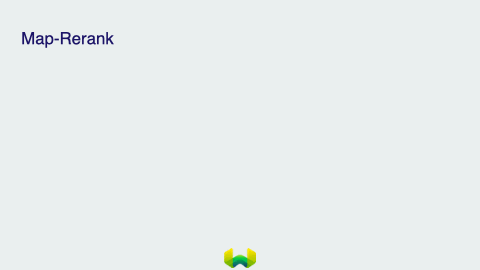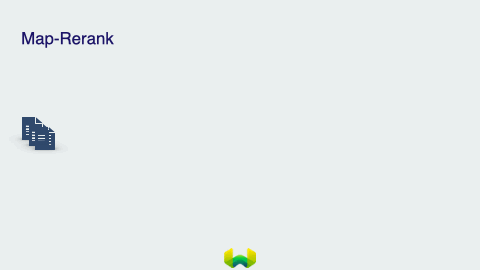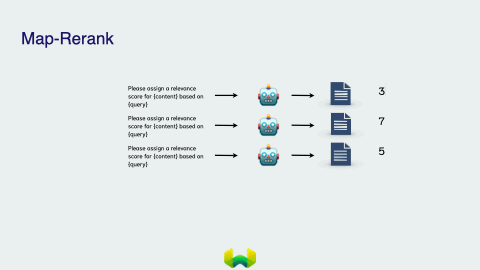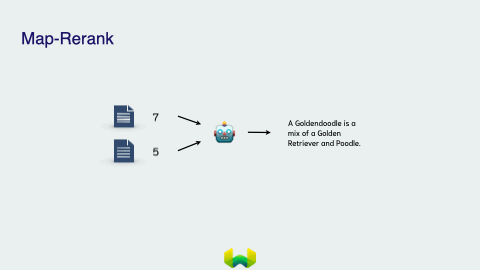
Map Rerank involves running an initial prompt that asks the model to give a relevance score. It is then passed through the language model and assigns a score based on the certainty of the answer. The documents are then ranked and the top two are stuffed to the language model to output a single response.
Tool Use
The last building block we will cover is tool use. Tool use is a way to augment language models to use tools. For example, we can hook up an LLM to vector databases, calculators, or even code executors. Of course we will dive into the vector databases next, but let’s start with an example of the code executor tool use.

The task for the language model is to write python code for the bubble sort algorithm. The code is then passed through the Python REPL. Python REPL is a code executor implemented in LangChain. Once the code is executed, the output of the code is printed. The language model then sees this output and judges if the code is correct.
ChatVectorDB
One of the most exciting features of LangChain is its collection of preconfigured chains. We will look at the ChatVectorDB chain, it lets you build an LLM that stores chat history and retrieves context from Weaviate to help with generation. To begin, the chat history in this chain uses the stuff configuration of CombineDocuments. This means we take as much of the chat history as we can fit in our context window and use it for a query reformulation prompt. The prompt is as follows:
_template = """Given the following conversation and a follow up question, rephrase the follow up question to be a standalone question.
Chat History:
{chat_history}
Follow Up Input: {question}
Standalone question:"""
We put the chat_history and the latest user input in the curly bracket syntax. Then we take this new query and hit the Weaviate vector database to get context to answer the question. The ChatVectorDB chain we use has a default value of k = 4 search results, if we use longer search results we will need another CombineDocuments chain here as well! With the 4 search results, we answer the question with this final prompt:
Prompt_template = """Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer.
{context}
Question: {question}
Helpful Answer:"""
Hopefully this was a nice look under the hood of how the ChatVectorDB chain works. Let’s get into how we can use this with Weaviate!
The Code
If this is your first time using Weaviate, please check out the Quickstart tutorial.
This demo is built off of Connor Shorten’s Podcast Search demo. We are connecting to our Weaviate instance and specifying what we want LangChain to see in the vectorstore. PodClip is our class and we want to use the content property, which contains the transcriptions of the podcasts. Next in qa we will specify the OpenAI model.
from langchain.vectorstores.weaviate import Weaviate
from langchain.llms import OpenAI
from langchain.chains import ChatVectorDBChain
import weaviate
client = weaviate.Client("http://localhost:8080")
vectorstore = Weaviate(client, "PodClip", "content")
MyOpenAI = OpenAI(temperature=0.2,
openai_api_key="sk-key")
qa = ChatVectorDBChain.from_llm(MyOpenAI, vectorstore)
chat_history = []
print("Welcome to the Weaviate ChatVectorDBChain Demo!")
print("Please enter a question or dialogue to get started!")
while True:
query = input("")
result = qa({"question": query, "chat_history": chat_history})
print(result["answer"])
chat_history = [(query, result["answer"])]
And just like that, you have built an application using LangChain and Weaviate. I recommend checking out the GitHub repository to test this out yourself!
Additional Resources
• LangChain Guide by Paul from CommandBar.
Ready to start building?
Check out the Quickstart tutorial, or build amazing apps with a free trial of Weaviate Cloud (WCD).
Don't want to miss another blog post?
Sign up for our bi-weekly newsletter to stay updated!
By submitting, I agree to the Terms of Service and Privacy Policy.