
Using Cross-Encoders as reranker in multistage vector search
Semantic search overcomes the shortcomings of keyword-based search. If you search for "programming for data scientists", a keyword search will find "An intro to programming for data scientists", but it won't return "Python for Machine Learning use-cases".
Vector databases can use machine learning to capture the context and semantics of data and search queries. Usually, machine learning models have a tradeoff between high accuracy and speed. The higher the accuracy, the more computationally expensive the model is. If we talk about search or Information Retrieval, we would like to see accurate search results, encompassing wide-range queries, whilst retaining high speed.
In search, or semantic matching of sentences, we can see this tradeoff in Bi-Encoder models compared with Cross-Encoder models. Bi-Encoder models are fast, but less accurate, while Cross-Encoders are more accurate, but slow. Luckily, we can combine them in a search pipeline to benefit from both models!
In this article, you will learn about these two machine learning models, and why combining them could improve the vector search experience.
Bi-Encoder models
Vector databases like Weaviate use Bi-Encoder machine learning models to compute the similarity between search queries and data in a vector space. Those machine learning models are trained to represent data (like text, images, videos, audio, etc) as vectors, which capture the context and semantics of the data. Similarly, search queries can also be represented by a vector embedding. A vector database can then perform a similarity search to retrieve the vectors closest to the query embedding.
The models that compute dense vector embeddings for data (which later can be used for search queries) are so-called Bi-Encoder models. Data vectors and query vectors can be compared by computing the similarity (for example cosine similarity) between vectors. All data items in the database can be represented by a vector embedding using a Bi-Encoder model.
Note. Vector databases compute dense vector embeddings during import. Calculating vectors up-front coupled with ANN algorithms (for faster retrieval) makes working with Bi-Encoder highly efficient.
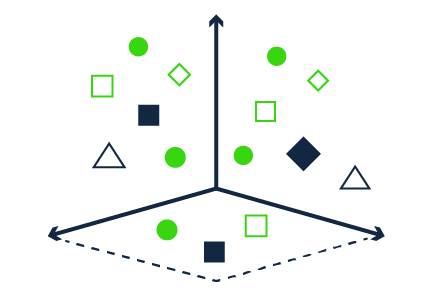
Figure 1 - Representation of a Vector Database
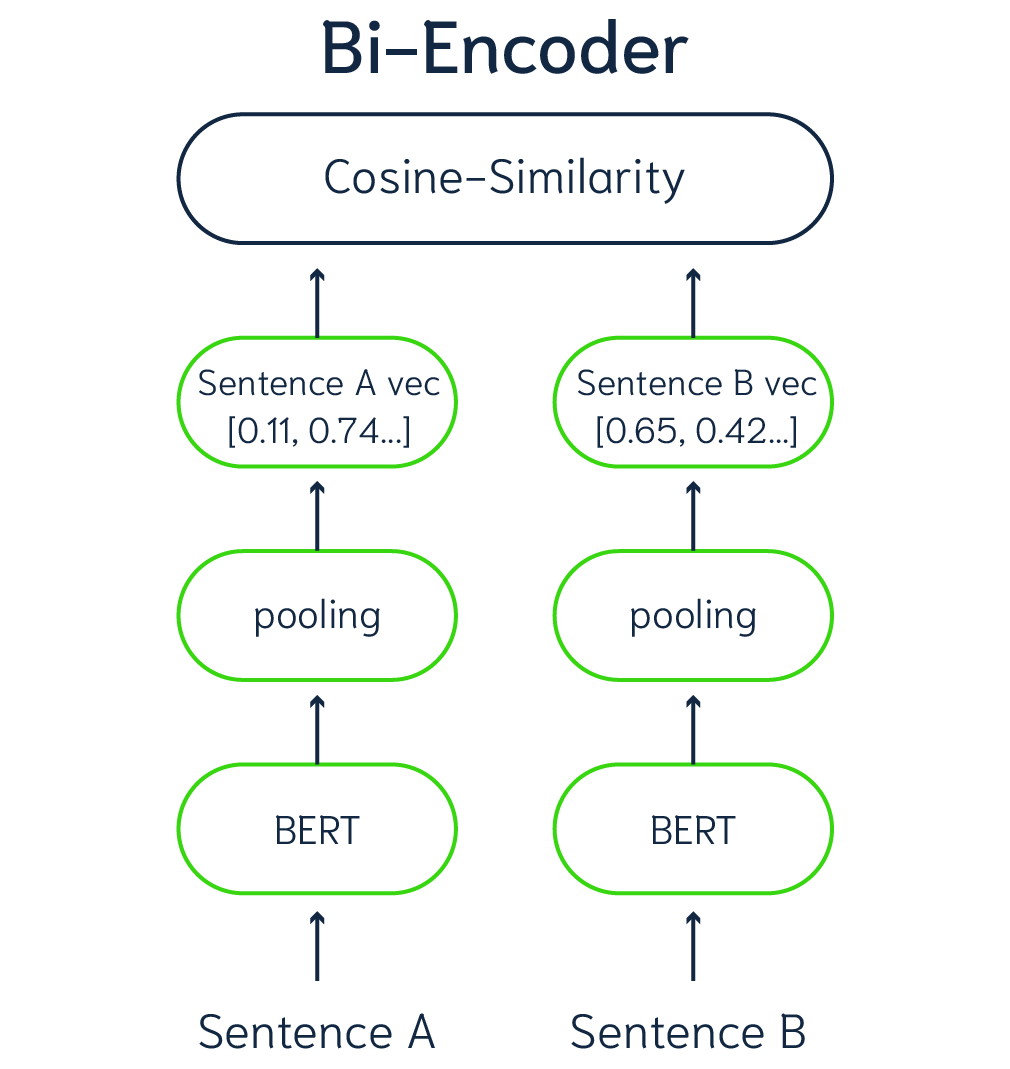
Figure 2 - Representation of a Bi-Encoder model
Cross-Encoder models
Bi-Encoder models are not the only possible way of scoring pairs of data on similarity. A different strategy is using Cross-Encoders. Cross-Encoder models do not produce vector embeddings for data, but use a classification mechanism for data pairs instead. The input of the model always consists of a data pair, for example two sentences, and outputs a value between 0 and 1 indicating the similarity between these two sentences (Figure 3). So, individual sentences cannot be passed to a Cross-Encoder model, it always needs a pair of "items". In terms of search, you need to use the Cross-Encoder with each data item and the search query, to calculate the similarity between the query and data object.
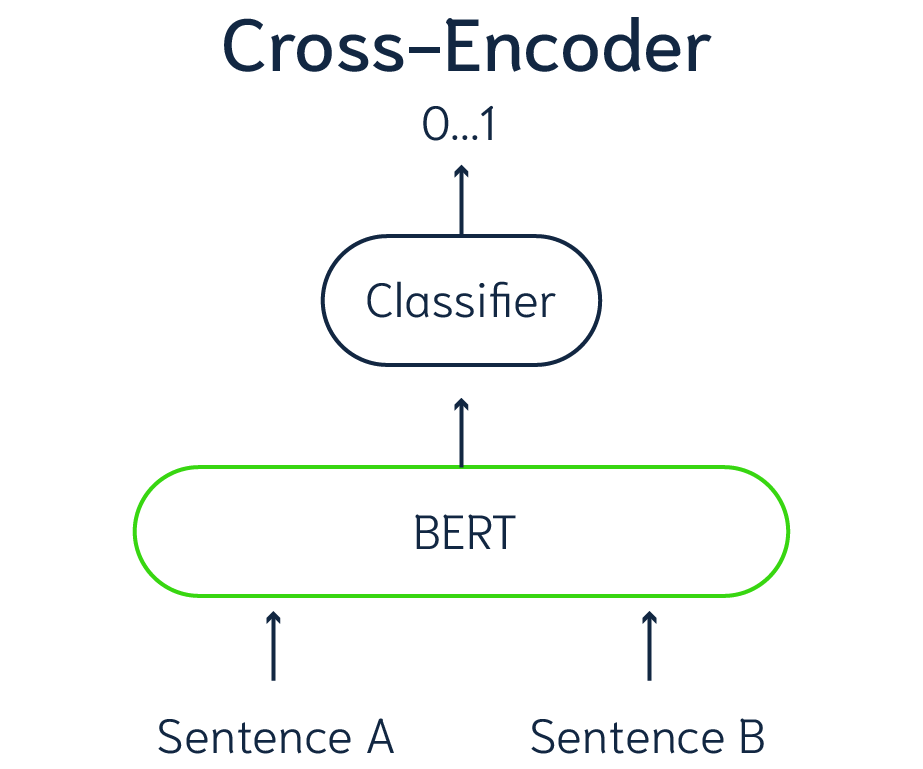
Figure 3 - Representation of a Cross-Encoder model
If a Cross-Encoder model is trained on a representative training set, it achieves higher accuracy than Bi-Encoders. However, since you need to use the Cross-Encoder model during a search for every single data item in combination with the query, this method is very inefficient. For a real-life semantic search application – with thousands or millions of objects – this would be impractical, as it would take "forever" to perform the search.
Combining Bi-Encoders and Cross-Encoders
We can combine the two methods to benefit from the strong points of both models! I'd like to illustrate this idea with an example. Imagine you are a fisherman who is looking for salmon in a sea full of fish of numerous species. First, you sail to the waters rich in fish, and you use a big net with the optimal bait for salmon to catch a lot of fish. You hope to find some salmon, but your net also catches other kinds of fish that you are not interested in. Next, you sort the catch by keeping the salmon and throwing the other fish back into the sea. This sorting step is time-consuming and expensive, but very effective.

Figure 4 - Fisherman as multistage search
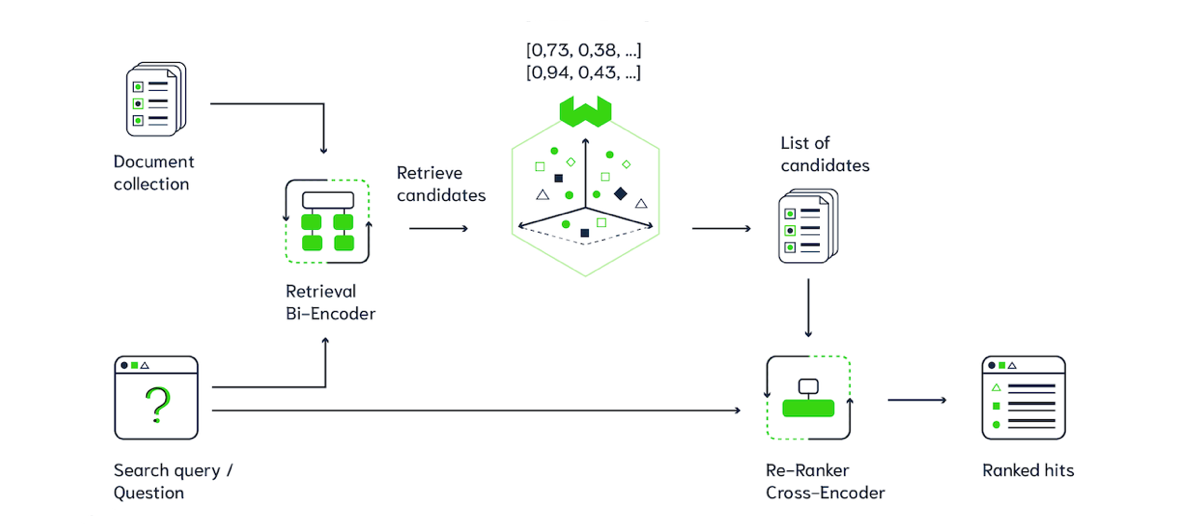
Catching fish with the big net represents how Bi-Encoders work. Bi-Encoders are fast, but are not as accurate as the expensive fisherman aka the Cross-Encoder. Cross-Encoders are time-consuming, like the fisherman who would need to limit the number of fishing rounds they could do. So we can chain those two methods behind each other (see Figure 5). First, you use a Bi-Encoder to retrieve a list of result candidates, then you use a Cross-Encoder on this list of candidates to pick out (or rerank) the most relevant results. This way, you benefit from the efficient retrieval method using Bi-Encoders and the high accuracy of the Cross-Encoder, so you can use this on large scale datasets!
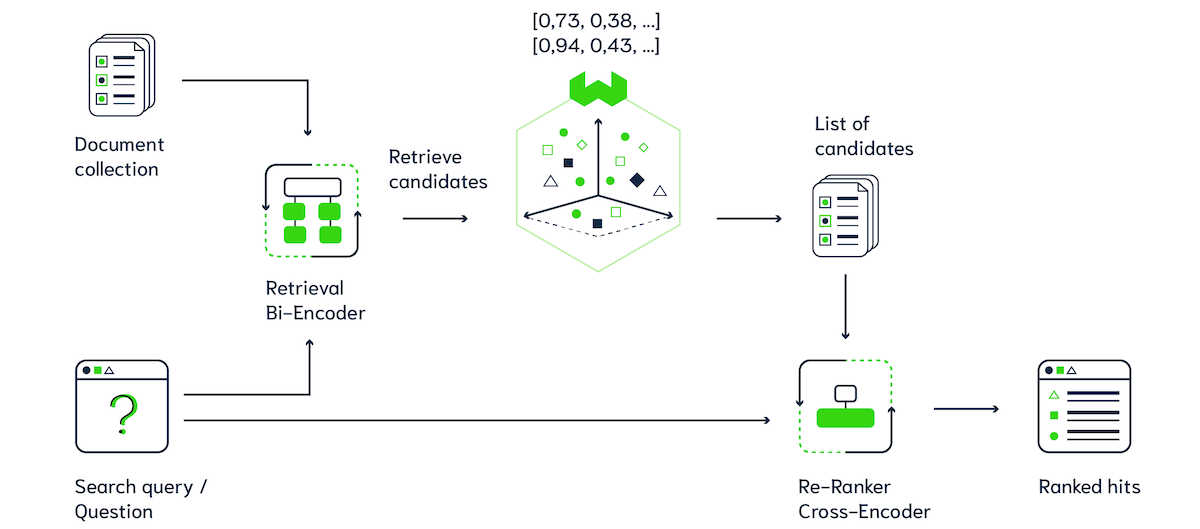
Figure 5 - Multistage search pipeline using Weaviate
Pre-trained Cross-Encoder models
As noted, Cross-Encoders can achieve high in-domain accuracy. To get the most accurate results, we train our models on datasets representative of their specialized use case.
Pretrained Sentence Transformers Cross-Encoder models are available on HuggingFace. There you can find many different models, for example a model trained on MS Marco, which you could use in a search application with general natural language data (the model is trained on Bing search queries). If you have a search task for a dataset that is out-of-domain, you should train or fine-tune a model, see here for examples.
Conclusion
We can combine the fast Bi-Encoders and accurate Cross-Encoders in a search pipeline to improve the search experience. With a vector database like Weaviate, you can store and retrieve vectors and data efficiently using Bi-Encoder models to encode data and queries. A search pipeline can then continue with a Cross-Encoder model which reranks a list of retrieved search result candidates.
This blog post was inspired by Nils Reimer's work on Bi-Encoders and Cross-Encoders.
Ready to start building?
Check out the Quickstart tutorial, or build amazing apps with a free trial of Weaviate Cloud (WCD).
Don't want to miss another blog post?
Sign up for our bi-weekly newsletter to stay updated!
By submitting, I agree to the Terms of Service and Privacy Policy.