
Weaviate 1.14 release
What is new
We are excited to announce the release of Weaviate 1.14, the most reliable and observable Weaviate release yet.
Later this week, we will release Weaviate v1.14, possibly the most boring release so far.😱 Yet I'm incredibly excited about it and so should you. Why?
(1/9)
See by @etiennedi
Besides many bug fixes and reliability improvements, we have a few neat features that you might find interesting. In short, this release covers:
- Reliability fixes and improvements
- Monitoring and Observability
- Support for non-cosine distances
- API changes
Reliability fixes and improvements
At Weaviate, Reliability is one of our core values, which means that we will always strive to make our software dependable, bug-free, and behave as expected.
And yes, bug fixing is not always the most exciting topic, as we often get more excited about shiny new features. But for you to truly enjoy working with Weaviate, we need to make sure that no bugs are getting in the way.
Check out the changelog to see the complete list of features and over 25 bug fixes.
Critical bug fix in compaction logic
In this release we fixed a critical bug, which in rare situations could result in data loss.
The bug affected environments with frequent updates and deletes.
This bug fix alone, makes it worth upgrading to Weaviate 1.14.
Background
We found a critical error in the compactioniong logic that could lead to the compaction operation either corrupting or completely losing data elements.
This could be obsereved through a variety of symptoms:
- Retrieving an object by it's ID would lead to a different result than retrieving the object using a filter on the id property
- Filters that should match a specific number of objects matched fewer objects than expected
- Objects missing completely
- Filters with
limit=1would not return any results when there should be exactly one element, but increasing the limit would then include the object - Filters would return results with
nullids
Example
In the first case, if you had an object with id: my-id-123456.
Calling the following GraphQL API with a filter on id would return the expected object.
{
Get {
Article(where: {
path: ["id"],
operator: Equal,
valueText: "my-id-123456"
}) {
title
}
}
}
However, calling the following REST API with the same id wouldn't get the object back.
GET /v1/objects/{my-id-123456}
The problem
So, if your data manipulation logic depended on the above operations to perform as expected, you update and delete operations might have been issued incorrectly.
Improved performance for large scale data imports
Weaviate 1.14 significantly improves the performance of data imports for large datasets.
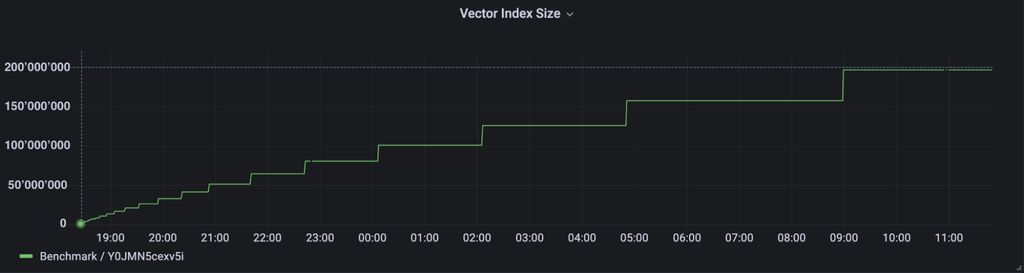
Note that the performance improvements should be noticeable for imports of over 10 million objects. Furthermore, this update enables you to import over 200 million objects into the database.
Problem
Before, the HNSW index would grow in constant intervals of 25,000 objects. This was fine for datasets under 25 million objects. But once the database got to around 25 million objects, adding new objects would be significantly slower. Then from 50–100m, the import process would slow down to a walking pace.
Solution
To address this problem, we changed how the HNSW index grows. We implemented a relative growth pattern, where the HNSW index size increases by either 25% or 25'000 objects (whichever is bigger).
Test
After introducing the relative growth patterns, we've run a few tests. We were able to import 200 million objects and more, while the import performance remained constant throughout the process.
Drastically improved Mean-Time-To-Recovery (MTTR)
Weaviate 1.14 fixes an issue where a crash-recovery could take multiple minutes, or even hours in some extreme cases. It is now a matter of just seconds. So even in the rare event that your instance crashes, it will come back up very quickly.
Problem
If Weaviate encounters an unexpected crash, no data will be lost. To provide this guarantee, a Write-Ahead Log (WAL) is in place. If a crash had occurred, the WAL is parsed at startup, and all previously unfinished operations are recovered, even if they were part of in-memory structures that had not yet been flushed. While this system is very safe, the recovery could be slow for several reasons:
- Unflushed memtables could become very large. This would lead to a lot of data that needs to be recovered after a crash
- The recovery process was single-threaded. If multiple recoveries were required, they would happen in sequence. On a large machine, this could mean that startup would be slow, yet only one of many CPU cores was utilized.
- The data structure used to hold the recovered items was never intended to hold many items. Each additional insertion would degrade its performance. As a result, the larger the WAL to recover, the slower the recovery would become.
Solution
We addressed each of the points above individually and improved the overall MTTR substantially:
- A deduplication process was added, so that large WALs with a lot of updates (i.e. redundant data) could be reduced to only the necessary information.
- The recovery process now runs in parallel. If there are multiple places that require recovery, they can each recover independently, without one recovery having to wait for the other.
- A mechanism was added that flushes any memtable that has been idle (no writes) for 60s or more. In addition to speeding up the recovery, this change also ensures that no recovery is needed at all in many cases.
Test
We designed an extreme stress test that would represent the "worst-case" scenario for recovery. It has multiple very large, independent Write-Ahead Logs that required for recovery. Before, this could take many hours to recover, while now it takes only a few seconds.
Full changelog
These are few of the many improvements and bug fixes that were included in this release.
Check out the changelog to see the complete list.
Monitoring and Observability
One of the biggest challenges of running software in production is to understand what is happening under the hood. That is especially important when something goes wrong, or we need to anticipate in advance when more resources are required.
 Without such insight, we end up looking at the black box, wondering what is going on.
Without such insight, we end up looking at the black box, wondering what is going on.
Announcement
With Weaviate 1.14 you can get a lot more insight into the resources and the performance of different aspects of your Weaviate instance in Production.
Now, you can expose Prometheus-compatible metrics for monitoring. Combine this with a standard Prometheus/Grafana setup to create visual dashboards for metrics around latencies, import speed, time spent on vector vs object storage, memory usage, and more.

Example
In a hypothetical scenario, you might be importing a large dataset. At one point the import process might slow down. You could then check your dashboards, where you might see that the vector indexing process is still running fast, while the object indexing slowed down.
Then you could cross-reference it with another dashboard, to see that the slow down began when the import reached 120 million objects.
In two steps, you could narrow down the issue to a specific area, which would get you a lot closer to finding the solution. Or you could use that data to share it with the Weaviate team to get help.
Try it yourserlf
Here is an example project, it contains:
docker-compose.ymlthat spins up Weaviate (without any modules),- a Prometheus instance,
- and a Grafana instance.
Just spin everything up, run a few queries and navigate to the Grafana instance in the browser to see the dashboard.
Learn more
To learn more, see the documentation.
Support for non-cosine distances
Weaviate v1.14 adds support for L2 and Dot Product distances.
With this, you can now use datasets that support Cosine, L2 or Dot distances. This opens up a whole new world of use cases that were not possible before.
Additionally, this is all pluggable and very easy to add new distance metrics in the future.
Background
In the past Weaviate used a single number that would control the distances between vectors and that was certainty. A certainty is a number between 0 and 1, which works perfectly for cosine distances, as cosine distances are limited to 360° and can be easily converted to a range of 0-1.

However, some machine learning models are trained with other distance metrics, like L2 or Dot Product. If we look at euclidean-based distances, two points can be infinitely far away from each other, so translating that to a bound certainty of 0-1 is not possible.
What is new
For this reason, we introduced a new field called distance, which you can choose to be based on L2 or Dot Product distances.
Raw distance
The distance values provided are raw numbers, which allow you to interpret the results based on your specific use-case scenario.
For example, you can normalize and convert distance values to certainty values that fit the machine learning model you use and the kind of results you expect.
Learn more
For more info, check out the documentation.
Contribute
Adding other distances is surprisingly easy, which could be a great way to contribute to the Weaviate project.
If that is something up your street, check out the distancer code on github, to see the implementation of other metrics.
Just make sure to include plenty of tests. Remember: "reliability, reliability, reliability".
Updated API endpoints to manipulate data objects of specific class

The REST API CRUD operations now require you to use both an object ID and the target class name.
This ensures that the operations are performed on the correct objects.
Background
One of Weaviate's features is full CRUD support. CRUD operations enable the mutability of data objects and their vectors, which is a key difference between a vector database and an ANN library. In Weaviate, every data object has an ID (UUID). This ID is stored with the data object in a key-value store. IDs don't have to be globally unique, because in Weaviate classes act as namespaces. While each class has a different HNSW index, including the store around it, which is isolated on disk.
There was however one point in the API where reusing IDs between classes was causing serious issues. Most noticeable this was for the v1/objects/{id} REST endpoints. If you wanted to retrieve, modify or delete a data object by its ID, you would just need to specify the ID, without specifying the class name. So if the same ID exists for objects in multiple classes (which is fine because of the namespaces per class), Weaviate would not know which object to address and would address all objects with that ID instead. I.e. if you tried to delete an object by ID, this would result in the deletion of all objects with that ID.
Endpoint changes
This issue is now fixed with a change to the API endpoints. To get, modify and delete a data object, you now need to provide both the ID and the class name.
The following object functions are changed: GET, HEAD, PUT, PATCH and DELETE.
Object change
New
/v1/objects/{ClassName}/{id}
Deprecated
/v1/objects/{id}
References change
New
v1/objects/{ClassName}/{id}/references/{propertyName}
Deprecated
v1/objects/{id}/references/{propertyName}
Client changes
There are also updates in the language clients, where you now should provide a class name for data object manipulation. Old functions will continue to work, but are considered deprecated, and you will see a deprecation warning message.
Stronger together
Of course, making Weaviate more reliable would be a lot harder without the great community around Weaviate.
As it is often the case: "You can't fix issues you didn't know you have".
Thank you
Thanks to many active members on Weaviate's Community Forum and through GitHub issues, we were able to identify, prioritize and fix many more issues than if we had to do it alone.
Together, we made Weaviate v1.14
the most stable release yet.
Help us
If at any point during your journey with Weaviate, you discover any bugs or you have feedback to share, please don't hesitate to reach out to us via:
We have a little favour to ask. Often reproducing the issue takes a lot more time than it takes to fix it. When you report a new issue, please include steps on how to reproduce the issue, together with some info about your environment. That will help us tremendously to identify the root cause and fix it.
Guide
Here is a little guide on how to write great bug reports.
Enjoy
We hope you enjoy the most reliable and observable Weaviate release yet!
Ready to start building?
Check out the Quickstart tutorial, or sign up for a free Weaviate Cloud account.
Don't want to miss another blog post?
Sign up for our bi-weekly newsletter to stay updated!
By submitting, I agree to the Terms of Service and Privacy Policy.