
Introducing Weaviate Embeddings
If you’re building AI applications and have struggled with embedding provider rate limits, being locked in with a single provider or model, or the overhead of self-hosting models, you’re in good company. So many developers face unnecessary friction when it comes to creating and managing vector embeddings, a critical function of their AI pipelines.
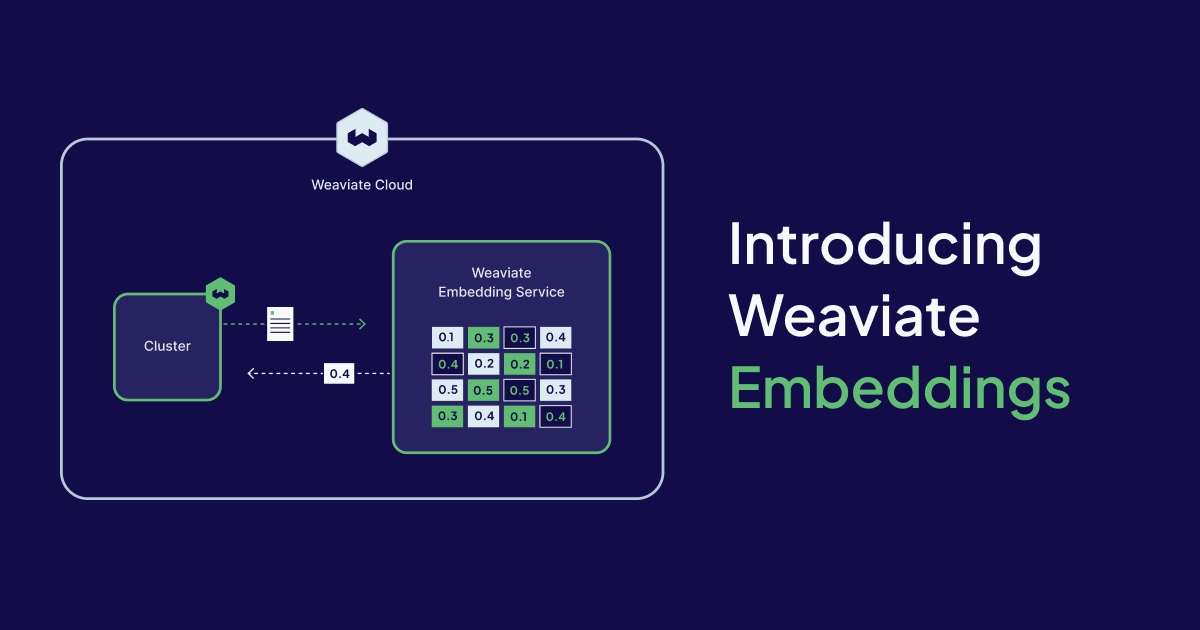
We’re excited to announce that Weaviate Embeddings, a new embedding service in Weaviate Cloud that makes creating vector embeddings as easy as possible for AI developers, is now available in preview.
The need for model flexibility
The landscape of Gen AI and machine learning models is evolving at a crazy pace, with new models being released almost daily. From large language models (LLMs), to vertical-specific, multimodal, open-source, and commercial models—developers are faced with an overwhelming amount of options. When you’re locked in with a single provider, it’s difficult to swap models and try new ones. Open-source models are becoming increasingly popular, but the complexity of self-hosting is one many teams don’t have the time or inclination to do, they simply want to focus on building new application capabilities and creating new business outcomes.
Weaviate has always prioritized model flexibility in our architecture, and we’ll continue to offer easy ways to integrate with external model providers via pre-built APIs. Weaviate Embeddings introduces the ability to run embedding models directly within Weaviate Cloud, without the need to connect to an external provider.
In preview, Weaviate Embeddings offers Snowflake’s Arctic-Embed open-source text embedding model which has scored impressively in industry benchmarks (although we’re fans of you running your own benchmarks). You can learn more about it here. We’ll soon add support for class-leading commercial multilingual and multimodal models. Users will be able to create vector embeddings for a variety of models, and compare the results and recall accuracy for their use case. This simplifies selecting the right model for the problem you are trying to solve.
Freedom from rate limits
Most external embedding APIs impose strict rate limits or batch processing with lengthy turnaround times, which slows down your entire pipeline, or even worse creates unnecessary latency for the search experience you are building. One of our customers recently told us that they’ve had to rebuild their entire document syncing pipeline around the fact that they were constantly running into rate limits with their commercial provider. Other customers struggle with throughput, stability, cost, and recall quality using existing services.
With Weaviate Embeddings, there are no artificial constraints. Our infrastructure is built to handle high-throughput use cases, efficiently processing large volumes of embeddings per second without compromising performance. Whether you’re importing billions of documents or performing real-time vector searches, Weaviate Embeddings scales with you, without slowing you down. Pricing is based on tokens consumed.
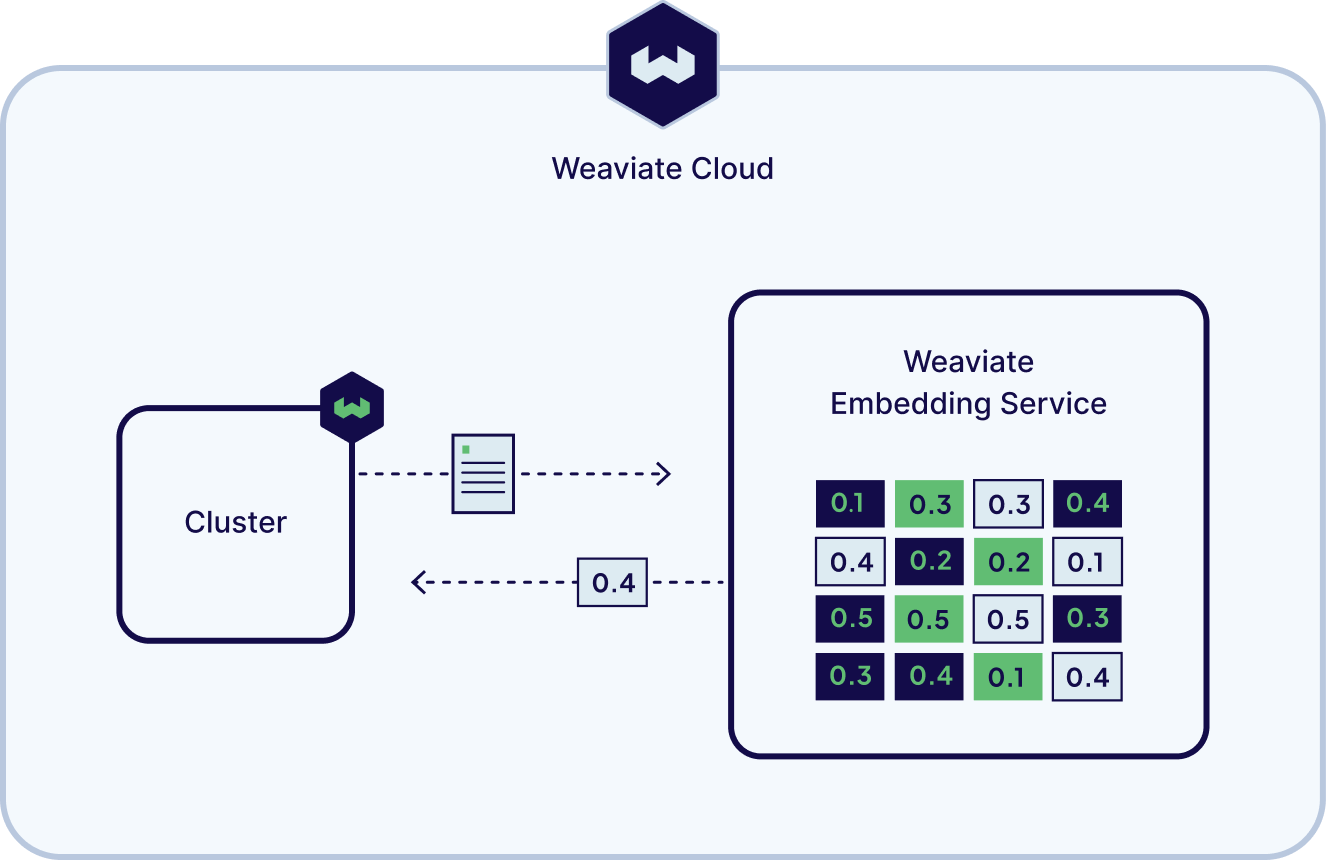
AI-ready data, with less friction
Our goal is to give developers flexibility of choice, while providing levers to make building AI applications easier and more efficient. With Weaviate Embeddings, you get:
- Leading OSS and proprietary models: Access cutting-edge open source and proprietary models. At preview, we will offer Snowflake Arctic-Embed (open-source) with commercial models coming early next year.
- Co-located models and data: Reduce latency and improve performance by hosting both your data and your models in Weaviate Cloud.
- Cost efficient and GPU-powered: Leverage GPU-powered inference and cost-efficient performance. Pay-as-you-go pricing based on tokens consumed means you only pay for what you use. You get full control, including the ability to optimize embedding dimensions based on your specific use case.
- Secure, enterprise-ready deployment: Weaviate is SOC2-certified, with security features like role-based access controls and strict data isolation.
A foundation for the future
Weaviate Embeddings is the bedrock of our future hosted model offerings. Upcoming advancements and releases will include multimodal models, dedicated hosting, and fine-tuned, optimized models tailored to your collection—laying the groundwork for exceptional retrieval quality across any domain. And this is just the beginning—stay tuned for exciting updates in the months ahead!
Give it a try
To learn more about Weaviate Embeddings, check out the docs, sign up for our upcoming webinar, or request preview access and we’ll get in touch.
Ready to start building?
Check out the Quickstart tutorial, or build amazing apps with a free trial of Weaviate Cloud (WCD).
Don't want to miss another blog post?
Sign up for our bi-weekly newsletter to stay updated!
By submitting, I agree to the Terms of Service and Privacy Policy.