
Ranking Models for Better Search

Whether searching to present information to a human, or a large language model, quality matters. One of the low hanging fruit strategies to improve search quality are ranking models. Broadly speaking, ranking models describe taking the query and each candidate document, one-by-one, as input to predict relevance. This is different from vector and lexical search where representations are computed offline and indexed for speed. Back in August, we published our thoughts on Cross Encoder Ranking.
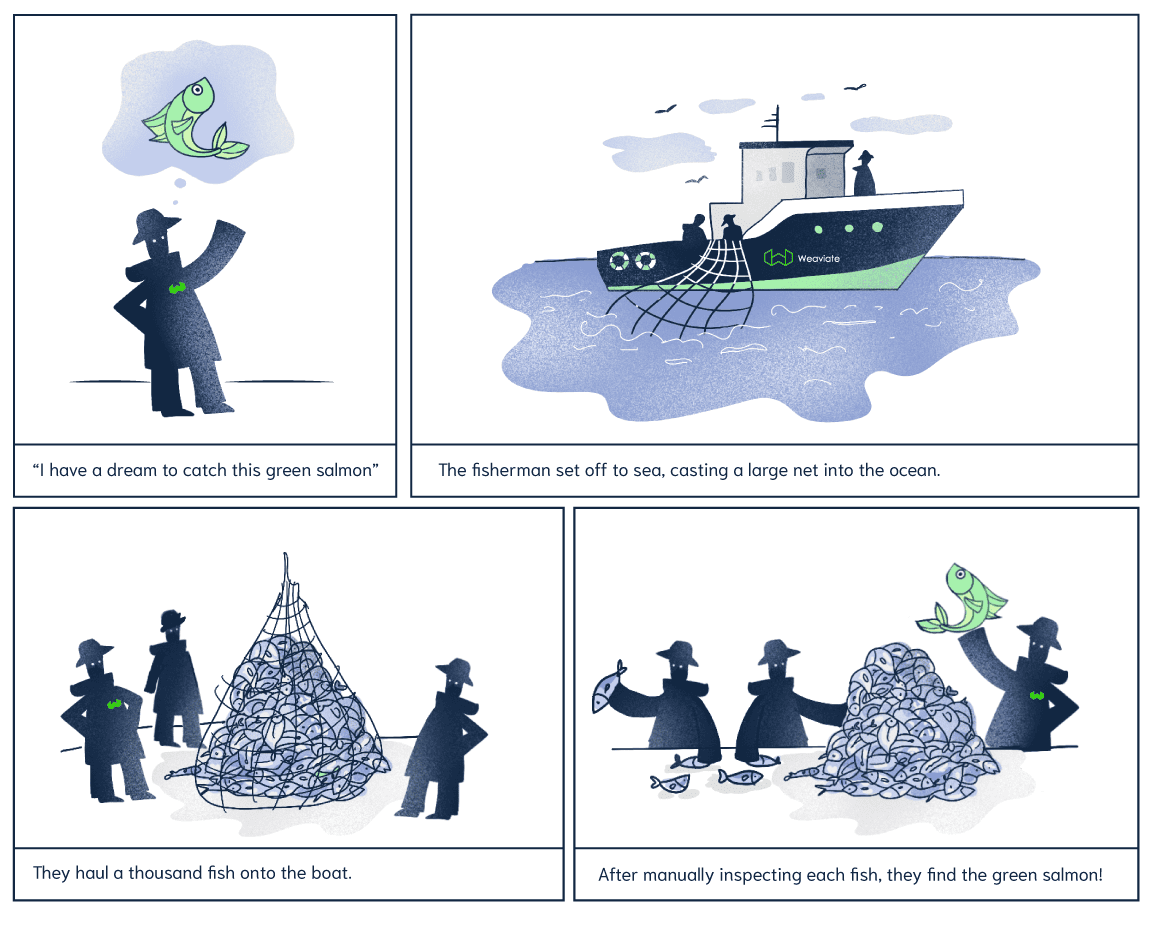
The blog post included this great visual to help with the visualization of combining Bi-Encoders and Cross-Encoders. This fishing example explains the concept of coarse-grained retrieval (fishing net = vector search / bm25) and manual inspection of the fish (fishermen = ranking models). Depicted with manual inspection of fish, the main cost of ranking models is speed.
In March, Bob van Luijt appeared on a Cohere panel to discuss “AI and The Future of Search”. Bob explained the effectiveness of combining zero-shot vector embedding models from providers such as Cohere, OpenAI, or HuggingFace with BM25 sparse search together in Hybrid Search. Developers who want to build AI-powered applications can now skip the tedious process of complex training strategies. Now you can simply take models off-the-shelf and plug them into your apps. Applying a ranking model to hybrid search results is a promising approach to keep pushing the frontier of zero-shot AI.
Imagine we want to retrieve information about the Weaviate Ref2Vec feature. If our application is using the Cohere embedding model, it has never seen this term or concept. Luckily, hybrid search comes to the rescue by combining the contextual semantics from the vector search and the keyword matching from the BM25 scoring. If the query is: How can I use ref2vec to build a home feed? The pairing of vector search and BM25 will return a good set of candidates. Now with the ranking model, it takes the [query, candidate document] pair as input and is able to further reason about the relevance of these results without specialized training.
Let’s begin with categories of ranking models. We see roughly 3 different genres of ranking models with:
- Cross Encoders (collapsing the use of Large Language Models for ranking into this category as well)
- Metadata Rankers
- Score Rankers
Cross Encoders
Cross Encoders are one of the most well known ranking models for content-based re-ranking. There is quite a collection of pre-trained cross encoders available on sentence transformers. We are currently envisioning interfacing cross encoders with Weaviate using the following syntax. This will take the candidates from hybrid search and apply the cross encoder to rank the final results.
This feature is not implemented into Weaviate yet, so the below code is an example of what it will look like.
{
Get {
PodClip(
hybrid: {
query: "How can I use ref2vec to build a home feed?"
alpha: 0.5
}
){
content
_additional {
crossrank(
query: "How can I use ref2vec to build a homefeed?"
property: "content"
){
score
}
}
}
Let’s see an example of this in action using the Weaviate Podcast Search dataset!
Query: Are there any ways to benchmark the performance of self-ask prompting?
| Ranker | Output |
|---|---|
| Cross Encoder | That's a great question. Honestly, you should invite Ofir to chat about that. And it's a great question. I hadn't thought of it that way. I don't know where it is in the data and it may simply be that the model is mashing up all this other data that it has in an interesting way, the same way that you can get stable diffusion to give you like people sitting around a campfire on an airplane, I think I saw go by, or like salmon swimming in a stream where it was literal pieces of salmon. That was never anywhere in the training set, but it managed to mash it up and figure out what to do with it. And I wonder if something similar is happening here. What I love about all this work, like self-ask, chain of thought, we're developing new querying languages. This is like us inventing SQL, except that we didn't design the database. The database came into being and we have to figure out how to interact with it. That example I mentioned about the IPython interaction, like that's a, again, it's a new querying language. And I honestly thought the most potent part of the self-ask wasn't even necessarily the self-ask part. It was that Ofir did such a phenomenal job of figuring out a way to measure the complexity of the knowledge that was extracted from the model. He gave us a benchmark, a ladder to climb, a way to measure whether we could retrieve certain kinds of information from models. And I think that's going to open the door to a ton more benchmarks. And you know what happens when there's a benchmark. We optimize the hell out of that benchmark and it moves science forward… [ truncated for visibility ] |
| Hybrid Only | Or, at least being able to ask follow up questions when it’s unclear about and that’s surprisingly not that difficult to do with these current systems, as long as you’re halfway decent at prompting, you can build up these follow up systems and train them over the course of a couple 1,000 examples to perform really, really well, at least to cove r90, 95% of questions that you might get. |
By re-ranking the results we are able to get the clip where Jonathan Frankle describes the benchmarks created by Ofir Press et al. in the self-ask paper! This result was originally placed at #6 with Hybrid Search only. This is a great opportunity to preview the discussion of how LLMs use search versus humans. When humans search, we are used to scrolling through the results a bit to see the one that makes sense. In contrast, language models are constrained by input length; we can only give so many results to the input of the LLM. Thus, quality at the expense of speed, becomes more interesting.
LLMs as Cross Encoders
So, let’s dive into the LLM hype a little more, how can we use LLMs for re-ranking? There are generally 2 ways to do this. The first strategy is identical to the cross encoder, we give the LLM the [query, document] input and prompt it to output a score of how relevant the document is to the query. The tricky thing with this is bounding the score. One technique is to prompt it with:
please output a relevance score on a scale of 1 to 100.
I think the second strategy is a bit more interesting, in which we put as many documents as we can in the input and ask the LLM to rank them. The key to making this work is the emergence of LLMs to follow instructions, especially with formatting their output. By prompting this ranking with “please output the ranking as a dictionary of IDs with the key equal to the rank and the value equal to the document id”. Also interesting is the question around how many documents we can rank like this and how expensive it is. For example, if we want to re-rank 100 documents, but can only fit 5 in the input at a time, we are going to need to construct some kind of tournament-style decomposition of the ranking task.
Further these approaches are well positioned to generalize to Recommendation. In Recommendation, instead of taking a [query, document] as input to a cross-encoder, we take as input a [user description, document] pair. For example, we can ask users to describe their preferences. Further, we could combine these in trios of [user description, query, item] for LLM, or more lightweight cross-encoder, ranking.
There is a bonus 3rd idea where we use the log probabilities concatenating the query with the document. However, most of the LLM APIs don’t actually give us these probabilities. Further, this is probably pretty slow. We will keep an eye on it, but it doesn’t seem like the next step to take for now.
Metadata Rankers
Whereas I would describe Cross-Encoders as content-based re-ranking, I would say Metadata rankers are context-based re-rankers. Metadata rankers describe using symbolic features to rank relevance. Typically this is in the context of recommendation in which we have metadata about users, as well as the documents or items.
So for example, say we have features that describe a Users looking for Movies such as:
User Features - (Age, Gender, Location, Occupation, Preferences) Movie Features - (Release Year, Genre, Box Office, Duration).
So together, the Metadata ranker takes as input something like: [Age, Gender, Location, Occupation, Preferences, Release year, Genre, Box Office, Duration] and predicts a score of how much this User will like the movie. We can fix the User features and rotate in each Document to get a score for each of the candidate movies (retrieved with something like ref2vec) to rank with.
In addition to vectors, Weaviate also enables storing metadata features about objects such as price, or color. We can send these features to wherever our Metadata Ranker is hosted and get those scores back to Weaviate to sort our search results.
This is also closely related to another category of ranking methods that use models like XGBoost to combine features, as well as say the bm25 score, vector distance, and maybe even the cross encoder score as well. This is a pretty interesting technique when you additionally factor in multiple properties. For example, we could have a bm25, vector, and cross encoders for the title, as well as content properties and use a learned model to combine these into a final ranking score.
I recently came across a paper titled “Injecting the BM25 Score as Text Improves BERT-Based Re-rankers” published in ECIR 2023. Taken directly from the paper, “Our findings indicate that cross-encoder re-rankers can efficiently be improved without additional computational burden and extra steps in the pipeline by explicitly adding the output of the first-stage ranker to the model input, and this effect is robust for different models and query types”. Taking this a bit further, Dinh et al. shows that most tabular machine learning tasks can be translated to text and benefit from transfer learning of text-based models. Many of these metadata rankers may also take in something like a collaborative filtering score that is based on this user’s history, as well as other users on the platform — another interesting feature to think of interfacing this way.
The main point being, maybe we can just add these meta features to our [query, document] representation and keep the Zero-Shot party going. We recently had an interesting discussion about metadata ranking and future directions for ranking models broadly on our latest Weaviate podcast! 👉 Check it out here
Score Rankers
Score rankers describe using either a classifier to detect things, or a regression model to score things, about our candidate documents to rank with. These kinds of models are increasingly being used as guardrails for generative models. For example, a harmful or NSFW content detector can prevent these generations from making it through the search pipeline. An interesting idea I recently heard from Eddie Zhou on Jerry Liu’s Llama Index Fireside Chat is the idea of using Natural Language Inference models to prevent hallucination by predicting the entailment or contradiction taking as the [retrieved context, generated output] as input. Because large language models are stochastic models, we can sample several candidate generations and filter them through score rankers like these.
A Recap of the Ranking Models
-
Cross Encoders are content-based re-ranking models that utilize pre-trained models, such as those available on Sentence Transformers, to rank the relevance of documents. They offer the advantage of further reasoning about the relevance of results without needing specialized training. Cross Encoders can be interfaced with Weaviate to re-rank search results, trading off performance for slower search speed.
-
Metadata Rankers are context-based re-rankers that use symbolic features to rank relevance. They take into account user and document features, such as age, gender, location, preferences, release year, genre, and box office, to predict the relevance of candidate documents. By incorporating metadata features, these rankers offer a more personalized and context-aware search experience.
-
Score Rankers employ classifiers or regression models to score and detect content, acting as guardrails for generative models. These scores can help in filtering harmful or NSFW content and prevent hallucinations with cutting edge ideas such as Natural Language Inference filters.
Each of these ranking models have particular use cases. However, the lines between these models are blurring with new trends such as translating tabular metadata features into text to facilitate transfer learning from transformers pre-trained on text. Of course, the recent successes of LLMs are causing a rethink of most AI workflows and the application of LLMs to rank and score rankers to filter generations are both exciting. To end this article, let’s discuss a little further why ranking is so exciting for the most hyped pairing of LLMs and Search: Retrieval-Augmented Generation.
Ranking for Retrieval-Augmented Generation
A lot of the recent successes of vector search can be attributed to their effectiveness as a tool for Large Language Models. So whereas the speed trade-off with rankers may be a major bottleneck for how humans use search, it might not be as much of a problem for how LLMs use search. Of course fast generation is preferred, but if you are paying for the result, quality may be more important than speed. Shi et al. have published “Large Language Models are easily distracted by irrelevant context”, highlighting how problematic bad precision in search can be for retrieval-augmented generation.
The recent developments in LLM agent tooling such as LangChain, LlamaIndex, and recent projects such as AutoGPT or Microsoft’s Semantic Kernel are paving the way towards letting LLMs run for a while to complete complex tasks. By ranking each handoff from search to prompt, we can achieve better results in each intermediate task. Thus when we leave an LLM running overnight to research the future of ranking models, we can expect a better final result in the morning!
Ready to start building?
Check out the Quickstart tutorial, or sign up for a free Weaviate Cloud account.
Don't want to miss another blog post?
Sign up for our bi-weekly newsletter to stay updated!
By submitting, I agree to the Terms of Service and Privacy Policy.