
Wikipedia and Weaviate

To conduct semantic search queries on a large scale, one needs a vector database to search through the large number of vector representations that represent the data. To show you how this can be done, we have open-sourced the complete English language Wikipedia corpus backup in Weaviate. In this article, I will outline how we've created the dataset, show you how you can run the dataset yourself, and present search strategies on how to implement similar vector and semantic search solutions in your own projects and how to bring them to production.
The Wikipedia dataset used is the "truthy" version of October 9th, 2021. After processing it contains 11.348.257 articles, 27.377.159 paragraphs, and 125.447.595 graph cross-references. Although a bigger machine (see below) is needed for importing the data, the serving is done on a 12 CPU, 100 GB RAM, 250Gb SSD Google Cloud VM with 1 x NVIDIA Tesla P4. The ML-models used are multi-qa-MiniLM-L6-cos-v1 and bert-large-uncased-whole-word-masking-finetuned-squad both are available as pre-built modules in Weaviate.
📄 The complete dataset and code is open-source and available on GitHub.
 Example semantic search queries in Weaviate's GraphQL interface — GIF by Author
Example semantic search queries in Weaviate's GraphQL interface — GIF by Author
Importing the Data In Two Steps
You can also directly import a backup into Weaviate without doing the import your self as outlined here.
To import the data we use two different methods. The first is to clean the data set and the second one is to import the data.
Step 1 – Cleaning the Data
The first step is pretty straightforward, we will clean the data and create a JSON Lines file to iterate over during import. You can run this process yourself or download the proceed file following this link.
Step 2 — Importing the Data
This is where the heavy lifting happens because all paragraphs need to be vectorized we are going to use Weaviate's modular setup to use multiple GPUs that we will stuff with models, but before we do this we need to create a Weaviate schema that represents our use case.
Step 2.1 — Create a Weaviate Schema
Within Weaviate we will be using a schema that determines how we want to query the data in GraphQL and which parts we want to vectorize. Within a schema, you can set different vectorizers and vectorize instructions on a class level.
First, because our use case is semantic search over Wikipedia, we will be dividing the dataset into paragraphs and use Weaviate's graph schema to link them back to the articles. Therefore we need two classes; Article and Paragraph.
{
classes: [
{
class: "Article",
description: "A wikipedia article with a title",
properties: {...},
vectorIndexType: "hnsw",
vectorizer: "none"
},
{
class: "Paragraph",
description: "A wiki paragraph",
properties: {...},
vectorIndexType: "hnsw",
vectorizer: "text2vec-transformers"
},
]
}
Weaviate class structure
Next, we want to make sure that the content of the paragraphs gets vectorized properly, the vector representations that the SentenceBERT transformers will generate are used for all our semantic search queries.
{
name: "content",
datatype: [
"text"
],
description: "The content of the paragraph",
invertedIndex: false,
moduleConfig: {
text2vec-transformers: {
skip: false,
vectorizePropertyName: false
}
}
}
A single data type that gets vectorized
Last, we want to make graph relations, in the dataset from step one we will distill all the graph relations between articles that we can reference like this:
{
name: "hasParagraphs"
dataType: [
"Paragraph"
],
description: "List of paragraphs this article has",
invertedIndex: true
}
Paragraph cross-references
The complete schema we import using the Python client can be found here.
Step 2.2 — Import the Data
Because we are going to vectorize a lot of data. We will be using the same machine as mentioned in the opening but with 4 instead of 1 GPU.
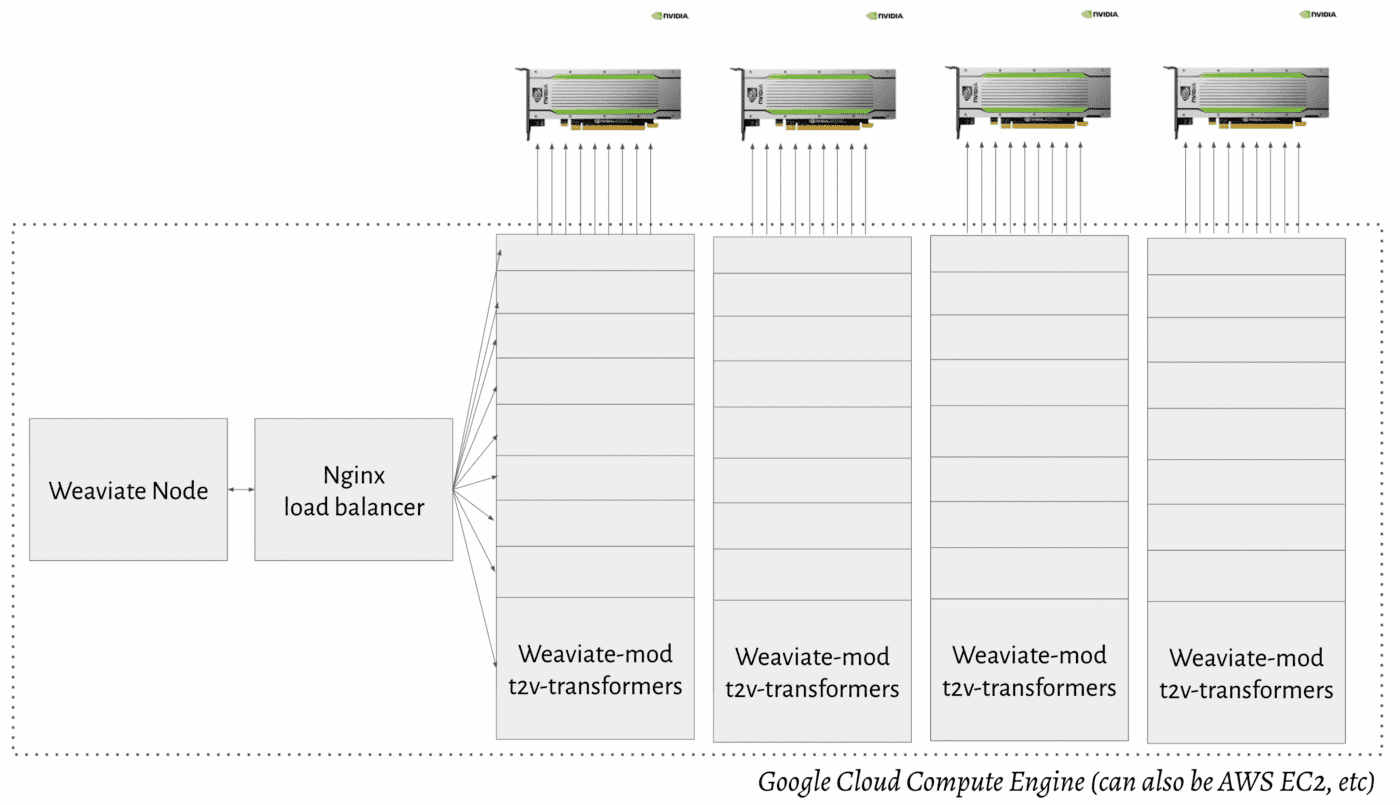 Google Cloud GPU setup with a Weaviate load balancer
Google Cloud GPU setup with a Weaviate load balancer
The load balancer will redirect the traffic to available Weaviate transformer modules so that the import speed significantly increases. In the section: Implementation Strategies — Bringing Semantic Search to Production below you'll find more info about how you can run this in production.
Most critically, we are going to set an external volume in the Docker Compose file to make sure that we store the data outside the container. This will allow us to package the backup and run Weaviate in the last step directly from the backup.
In the environment variables, we set a CLUSTER_HOSTNAME, an arbitrary name you can set to identify a cluster.
environment:
TRANSFORMERS_INFERENCE_API: 'http:loadbalancer:8080'
QUERY_DEFAULTS_LIMIT: 25
AUTHENTICATION_ANONYMOUS_ACCESS_ENABLED: 'true'
PERSISTENCE_DATA_PATH: '/var/lib/weaviate'
DEFAULT_VECTORIZER_MODULE: 'text2vec-transformers'
ENABLE_MODULES: 'text2vec-transformers'
CLUSTER_HOSTNAME: '63e2f234026d'
Docker environment setup
We will also set the location of the volume outside Weaviate, in this case the data will be stored in the /var/weaviate folder
volumes:
- /var/weaviate:/var/lib/weaviate
Volumes for backup
You can find the complete Docker Compose file we've used here.
Query the Data
The current Weaviate setup has two modules enabled: semantic search and Q&A. The modules can be used for different types of queries. The query language used is GraphQL and can be used with a wide variety of client libraries in different programming languages.
To follow along, and try out these examples, create an account in Weaviate Cloud.
Example 1 — natural language questions
In this example, we pose a natural language question, and we will assume that the first result contains the answer (hence the limit is set to 1). The result based on the latest dataset contains a certainty (i.e., the distance from the query to the answer in the vector space) of ≈ 0.68. In your end application, you can set limits to the certainty to determine if you want to present the results to the end-user, in the latest paragraph of this article (Implementation Strategies — Bringing Semantic Search to Production) you'll find more info about this.
{
Get {
Paragraph(
ask: {
question: "Where is the States General of The Netherlands located?"
properties: ["content"]
}
limit: 1
) {
_additional {
answer {
result
certainty
}
}
content
title
}
}
}
Example 2 — generic concept search
One can not only search for natural language questions, but also generic concepts like "Italian food" in the overview below. The nearText filter also allows for more specific filters like moveAwayFrom and MoveTo concepts to manipulate the search through vector space.
{
Get {
Paragraph(
nearText: {
concepts: ["Italian food"]
}
limit: 50
) {
content
order
title
inArticle {
... on Article {
title
}
}
}
}
}
Example 3 — mix natural language questions with scalar search
Within Weaviate you can also mix scalar search filters with vector search filters. In the specific case, we want to conduct a semantic search query through all the paragraphs of articles about the saxophone player Michael Brecker.
{
Get {
Paragraph(
ask: {
question: "What was Michael Brecker's first saxophone?"
properties: ["content"]
}
where: {
operator: Equal
path: ["inArticle", "Article", "title"]
valueText: "Michael Brecker"
}
limit: 1
) {
_additional {
answer {
result
}
}
content
order
title
inArticle {
... on Article {
title
}
}
}
}
}
Example 4 — mix generic concept search with graph relations
With Weaviate you can also use the GraphQL interface to make graph relations like -in the case of Wikipedia- links between different articles. In this overview we connect the paragraphs to the articles and show the linking articles.
{
Get {
Paragraph(
nearText: {
concepts: ["jazz saxophone players"]
}
limit: 25
) {
content
order
title
inArticle {
... on Article { # <== Graph connection I
title
hasParagraphs { # <== Graph connection II
... on Paragraph {
title
}
}
}
}
}
}
}
Implementation Strategies — Bringing Semantic Search to Production
The goal of Weaviate is to allow you to bring large ML-first applications to production. But like with any technology, it is not a silver bullet and success depends on your implementation.
Scalability
The demo dataset runs on a Docker setup on a single machine, you can easily spin up a Kubernetes cluster if you want to use the Weaviate dataset in production. How to do this, is outlined here.
Conclusion
To bring semantic search solutions to production, you need three things:
- Data
- ML-Models
- Vector database
In this article, we have shown how you can bring the complete Wikipedia corpus (data) using open-source ML-models (Sentence-BERT) and a vector database (Weaviate) to production.
Ready to start building?
Check out the Quickstart tutorial, or sign up for a free Weaviate Cloud account.
Don't want to miss another blog post?
Sign up for our bi-weekly newsletter to stay updated!
By submitting, I agree to the Terms of Service and Privacy Policy.