
Weaviate 1.15 release

We are happy to announce the release of Weaviate 1.15, which is packed with great features, significant performance improvements, new distance metrics and modules, and many smaller improvements and fixes.
The brief
If you like your content brief and to the point, here is the TL;DR of this release:
- ☁️Cloud-native backups - allows you to configure your environment to create backups - of selected classes or the whole database - straight into AWS S3, GCS or local filesystem
- Reduced memory usage - we found new ways to optimize memory usage, reducing RAM usage by 10-30%.
- Better control over Garbage Collector - with the introduction of GOMEMLIMIT we gained more control over the garbage collector, which significantly reduced the chances of OOM kills for your Weaviate setups.
- Faster imports for ordered data - by extending the Binary Search Tree structure with a self-balancing Red-black tree, we were able to speed up imports from O(n) to O(log n)
- More efficient filtered aggregations - thanks to optimization to a library reading binary data, filtered aggregations are now 10-20 faster and require a lot less memory.
- Two new distance metrics - with the addition of Hamming and Manhattan distance metrics, you can choose the metric (or a combination of) to best suit your data and use case.
- Two new Weaviate modules - with the Summarization module, you can summarize any text on the fly, while with the HuggingFace module, you can use compatible transformers from the HuggingFace
- Other improvements and bug fixes - it goes without saying that with every Weaviate release, we strive to make Weaviate more stable - through bug fixes - and more efficient - through many optimizations.
Read below to learn more about each of these points in more detail.
Patch 1.15.1 note
We have published a patch release v1.15.1.
To learn more check the Weaviate 1.15.1 patch release blog.
Community effort��

😀We are extremely happy about this release, as it includes two big community contributions from Aakash Thatte and Dasith Edirisinghe. Over the last few weeks, they collaborated with our engineers to make their contributions.
🚀Aakash implemented the two new distance metrics, while Dasith contributed by implementing the two new Weaviate modules.
👕We will send some Weaviate t-shirts to Aakash and Dasith soon.
🤗We hope to see many more big and small contributions in the coming months and years. #CommunityRocks
Cloud-native backups
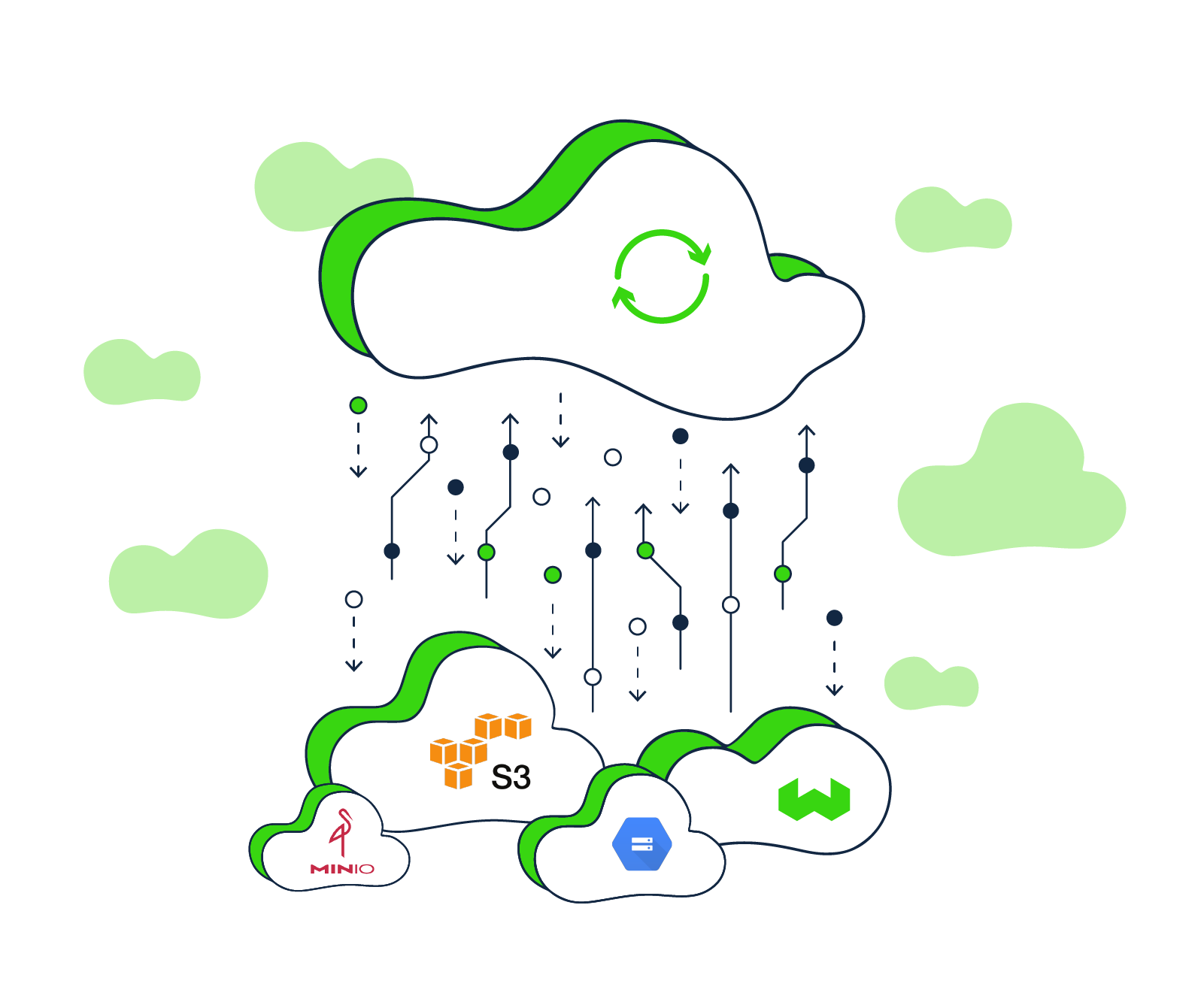
Creating and restoring database backups in Weaviate was one of the most requested features from the Weaviate community and customers.
And, of course, database backups are not just about disaster recovery. Sometimes we need to migrate our data to a different environment. Maybe because our database grew and now we need more resources, or perhaps we need to set up a new developer environment.
We listened to your feedback, suggestions and use cases! So we made it our mission for the 1.15 release to design and implement an elegant solution with a great Developer Experience (DX), which you will love 😍 to use for years to come.
Announcement
Introducing Weaviate Cloud-native backups. 🎉
It allows you to make full database backups (or selected classes) straight to S3, GCS or the local filesystem with a single API call 🤩; and restore the data to a Weaviate instance of your choice with another API call.
What is really great about this implementation is that you can create a backup without downtime on a running instance. The database stays fully operational (including receiving writes) while the backup is transferred to the remote storage.
The database backups include data objects, plus their vectors and indexes. This way, restoring a backup is a straight copy of all the required elements without the need to re-create vectors or rebuild the indexes. (Read, this is going to be fast)
Backup modules
Cloud-native backups in Weaviate are handled with the addition of the new backup modules:
backup-s3- for S3backup-gcs- for GCSbackup-fs- for local filesystem
Without getting into too many details (see the docs for more precise instructions), each module requires a different set of settings.
For S3 and GCS, you need your cloud bucket name, authentication details and some extra details like a project name or the cloud region.
For S3 authentication you can use access keys or IAM with role ARN's.
For GCS you can use a Google Application Credentials json file.
Alternatively, you can configure backups with the local filesystem. All you need here is to provide the path to the backup folder.
Note, you can have multiple storage configurations - one for each S3, GCS and the local filesystem.
Creating backups - API
Once you have the backup module up and running, you can create backups with a single POST command:
POST /v1/backups/{storage}/
{
"id": "backup_id"
}
The storage values are s3, gcs, and filesystem.
For example, you can create a backup called first_backup and push it to GCS, like this:
POST /v1/backups/gcs/
{
"id": "first_backup"
}
Then, you can check the backup status by calling:
GET /v1/backups/gcs/first_backup
Restore
To restore a backup, you can call:
POST /v1/backups/{store}/{backup_id}/restore
So, using our previous example, you can restore the first_backup, like this:
POST /v1/backups/gcs/first_backup/restore
You can also, check the status of an ongoing restoration by calling:
GET /v1/backups/gcs/first_backup/restore
Cross-cloud
Here is one interesting thing that you might not have noticed. You can use this setup to run Weaviate with one cloud provider but then store and restore backups to/from another cloud provider. So, for example, you can run Weaviate on AWS and use GCS for your backup needs. How cool is that?
Class backups
You can also create backups for specific classes or select which classes you want to restore. Just add one of the following properties to the POST payload:
include- an array class names we want to backup or restoreexclude- an array class names we don't want to backup or restore
For example, you can create a backup that includes Cats, Dogs and Meerkats.
POST /v1/backups/gcs
{
"id": "first_backup",
"include": ["Cats", "Dogs", "Meerkats"]
}
Then restore all classes, excluding Cats:
POST /v1/backups/gcs/first_backup/restore
{
"exclude": ["Cats"]
}
Other use cases
It might not be immediately obvious, but you can use the above workflow to migrate your data to other environments.
So, if one day you find yourself with an environment that is not set up for what you need (i.e. not enough resources). Then create a backup, and restore it in the new environment. 😉
Follow up
Are you ready to set up backups for your environment? Head to the documentation for a more in-depth overview and instructions.
Reduced memory usage
As part of the continuous effort to make Weaviate faster, leaner and more powerful, we introduced new optimizations to use less RAM without sacrificing performance.
Thread pooling optimization
First, we set our sights on parallel imports, where we introduced thread pooling to reduce memory spikes while importing data.
Previously if you had, e.g., 8 CPUs and would import from 4 client threads, each client request would run with a parallelization factor of 8 (one per CPU core). So, in the worst case, you could end up with 32 parallel imports (on a machine with "only" 8 CPUs). There is no performance gain if we have more parallelization than there are available CPUs. However, each thread needs additional memory. So with 32 parallel imports, we had the worst of both worlds: High memory usage and no performance gains beyond 8.
With the fix, even if you import from multiple clients, Weaviate automatically handles the parallelization to ensure that it does not exceed the number of CPU cores. As a result, you get the maximum performance without "unnecessary" memory usage.
HNSW optimization
Next, we optimized memory allocations for the HNSW (vector) index.
We found that the data structures relied on dynamic allocations. So, even if we knew that an array would never be longer than 64 elements, the Go runtime could still decide to allocate an array[100] in the background when the array reaches 51 elements.
To fix that, we switched to static allocations, and Weaviate instructs the Go runtime to allocate the exact number of elements. This reduced static memory usage even when idle.
Results
🎉 Between these two major updates, plus some smaller ones, we saw a **significant reduction in memory usage of 10-30%**🚀.
🤔 With this, you can get more out of your existing setups and push your Weaviate instances to do more, or you could save on the resources.
Better control over Garbage Collector

Weaviate is built from the ground up in Go, which allows for building very performant and memory-safe applications. Go is a garbage-collected language.
A quick refresher:
In a garbage-collected language, such as Go, C#, or Java, the programmer doesn't have to deallocate objects manually after using them. Instead, a GC cycle runs periodically to collect memory no longer needed and ensure it can be assigned again.
The problem
Working with a garbage collector is very safe, and the resource cost of running GC cycles is a fairly small tradeoff. We just need to ensure that we have the right balance of frequency of GC cycles and the buffer of available memory (on top of what we have estimated for our application setup).
Now, increasing each of those comes with a price:
- Increasing the frequency of GC cycles will use more CPU, which we could make better use of elsewhere.
- Increasing RAM costs money - and for memory demanding setups, that can be a big 💰sum.
And if we get that balance wrong, we might end up with an Out Of Memory crash.
The solution
At the beginning of August, the Go team released Go 1.19, which introduced GOMEMLIMIT. GOMEMLIMIT turned out to be a game changer for high-memory applications.
With GOMEMLIMIT we can provide a soft memory cap, which tells Go how much memory we expect the application to need. This makes the GC more relaxed when RAM is plentiful and more aggressive when memory is scarce.
To learn more about memory management, GC and GOMEMLIMIT, check out this article, which explains it all in more depth.
Announcement
🎉We are happy to share that all Weaviate v1.15 binaries and distributions have been compiled with Go 1.19 which comes with GOMEMLIMIT.
Now, you can set your soft memory cap by setting the GOMEMLIMIT environment variable like this:
GOMEMLIMIT=120GiB
For more information, see the Docker Compose environment variables in the docs.
Faster imports for ordered data

Weaviate v1.5 introduced an LSM store (Log-Structured Merge Trees) to increase write-throughput. The high-level idea is that writes are batched up in logs, sorted into a Binary Search Tree (BST) structure, and then these batched-up trees are merged into the tree on disk.
The Problem
When importing objects with an inherent order, such as timestamps or row numbers that increase monotonously, the BST becomes unbalanced: New objects are always inserted at the "greater than" pointer / right node of the BST. This collapses the binary tree into a linked list with O(n) insertion rather than the O(log n) promise of the BST.
The Fix
To address that in Weaviate v1.15, we've extended the BST with a self-balancing Red-black tree.
Through rotations of the tree at insert, Red-black trees ensure that no path from the root to leaf is more than twice as long as any other path. This achieves O(log n) insert times for ordered inserts.
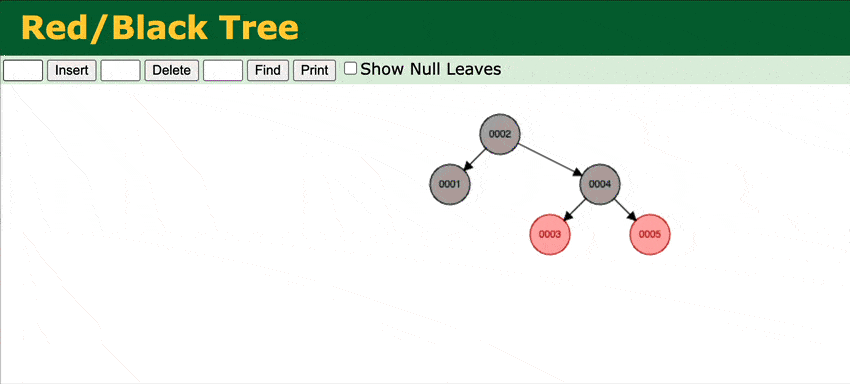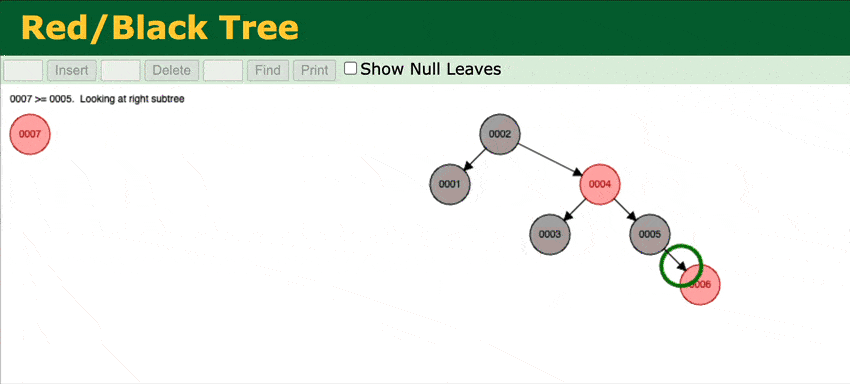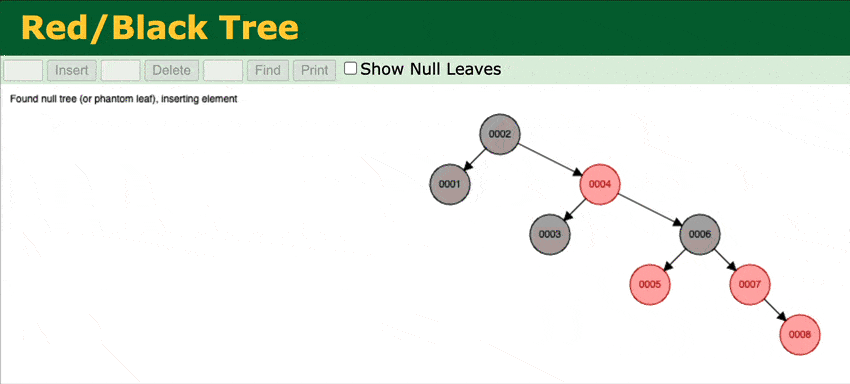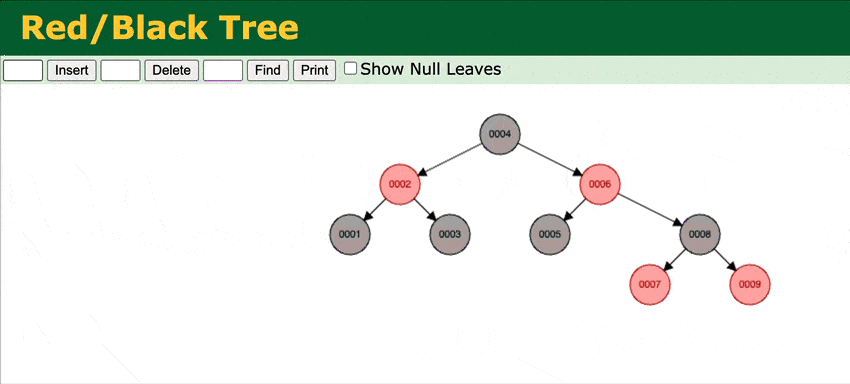 A visual representation of how the RBT works.
A visual representation of how the RBT works.
You can try it yourself here. Add any ordered input, for example, 1, 2, 3, 4 and see how the tree stays balanced.
Results
We've run a few local tests to paint a better picture of what you could expect.
First, we saw that the RB-Tree is a factor of 20 faster than the binary tree when adding objects with sequential keys (just the tree, without anything else).
With a full import test, we saw a 3x performance improvement 🚀.
- Weaviate
1.14.1- import time ~38 minutes - Weaviate
1.15.0- import time ~13 minutes 🔥
More efficient filtered aggregations
Recently we've been working with a customer who was running multiple filtered aggregations on a large dataset. Unfortunately, the queries were slow, resulting in Out Of Memory kills in some cases. This was not good enough for what we expected of Weaviate.
Investigation
To investigate the issue, we've set up a database with 1M objects and a profiler to watch memory consumption.
We used that setup to run ten parallel filtered aggregations. Upon reviewing the memory consumption, we noted that some of the filtered aggregations were taking up to 200GB of RAM (note, this was not the total allocated memory on the heap, as a big part of it was waiting to be collected by GC).
The issue
Fast forward, we identified two key issues. First, the Go library that we used for reading binary data (binary.read) isn't optimized for how we use it in Weaviate, as it makes many temporary memory allocations. Second, for every object in the aggregation, we would allocate new memory on the heap, process the read, and release the memory.
This is a bit like, if we want to eat a cake, we need to put it on a plate, eat the cake and then put the plate in the sink to wash. Now, if we want to eat a million cakes, we will be either very busy washing dishes or have a million plates in the sink (or even run out of plates).
I am sure you would rather spend more time eating cakes than dealing with plates.
This is bad for three reasons:
- Grabbing a new plate for each cake and then washing it takes time - higher CPU use with many GC cycles.
- We would pile up many plates between each wash - high memory consumption between each GC cycle.
- We might run out of clean plates - OOM crash if we run out of RAM.
The solution
To solve the problem, we implemented two solutions:
- We created our own library for reading binary data optimized for the Weaviate-specific needs. It makes fewer temporary memory allocations.
- We made sure to reuse the same memory where possible.
In the world of cakes, we optimized our eating technique to consume more cakes, and we only need one plate to eat all the cakes.
On top of that, we've introduced other minor optimizations. So if you are curious about that, drop us a message on our Forum, and we can chat some more.
Results
As a result, the filtered aggregations are to 10-20x faster and require less memory.
When we rerun the original test (with ten parallel aggregations), we saw the memory consumption drop to 30GB (vs 200GB).
New distance metrics
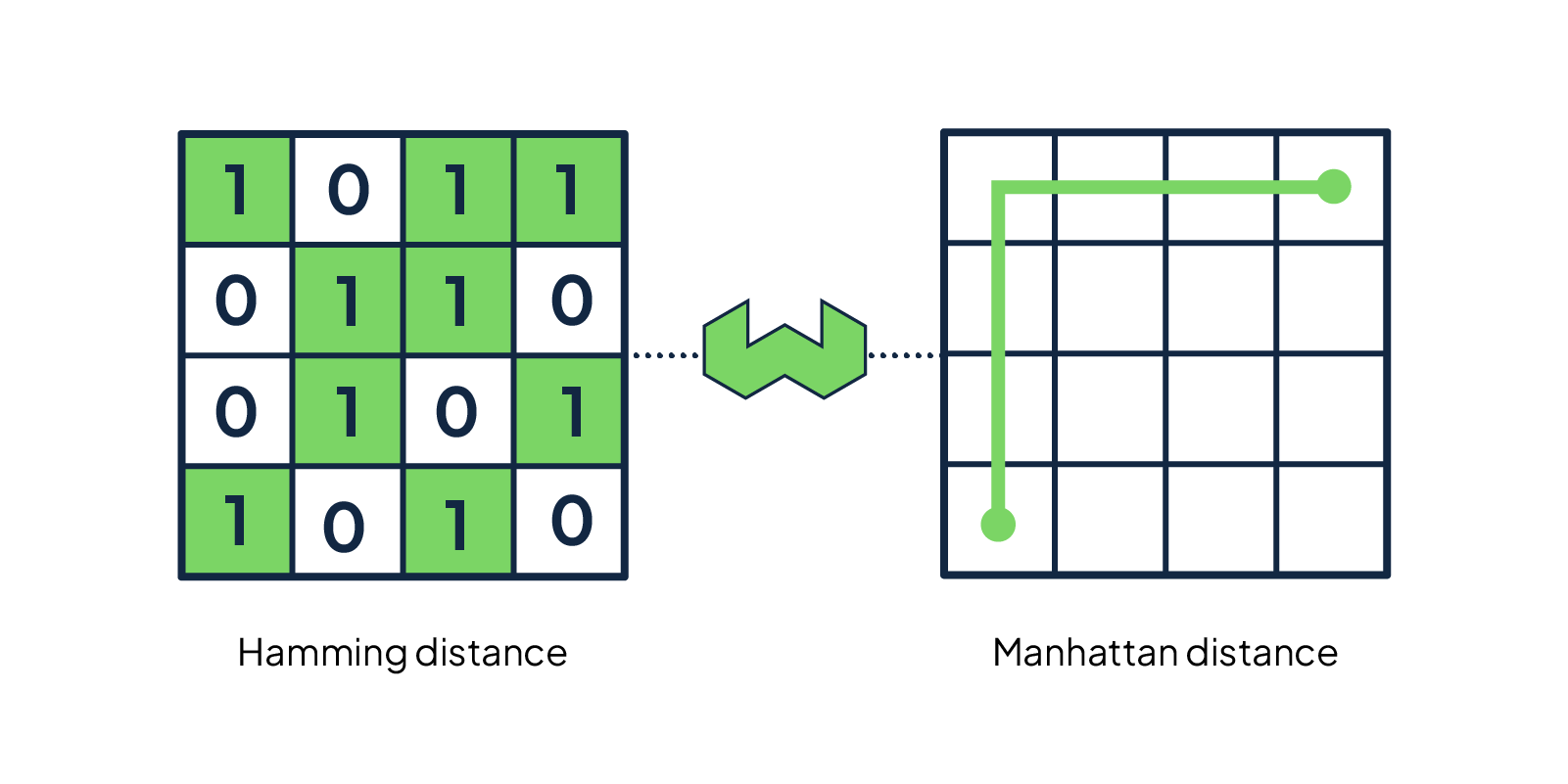
Thanks to the community contributions from Aakash Thatte, Weaviate v1.15 adds two new distance metrics: Hamming distance and Manhattan distance. In total, you can now choose between five various distance metrics to support your datasets.
Check out the metrics documentation page for a complete overview of all available metrics in Weaviate.
Hamming distance
The Hamming distance is a metric for comparing two numerical vectors.
It compares the vector values dimension by dimension and returns a total count of differing values. The fewer differences, the closer the vectors.
For example, the Hamming distance for the below vectors is 2, which is the count of differing values.
- A
[1, 9, 3, 4, 5] - B
[1, 2, 3, 9, 5]
Manhattan distance
The Manhattan distance (also known as L1 norm and Taxicab Distance) - calculates the distance between a pair of vectors, as if simulating a route for a Manhattan taxi driver driving from point A to point B - who is navigating the streets of Manhattan with the grid layout and one-way streets. For each difference in the compared vectors, the taxi driver needs to make a turn, thus making the ride this much longer.
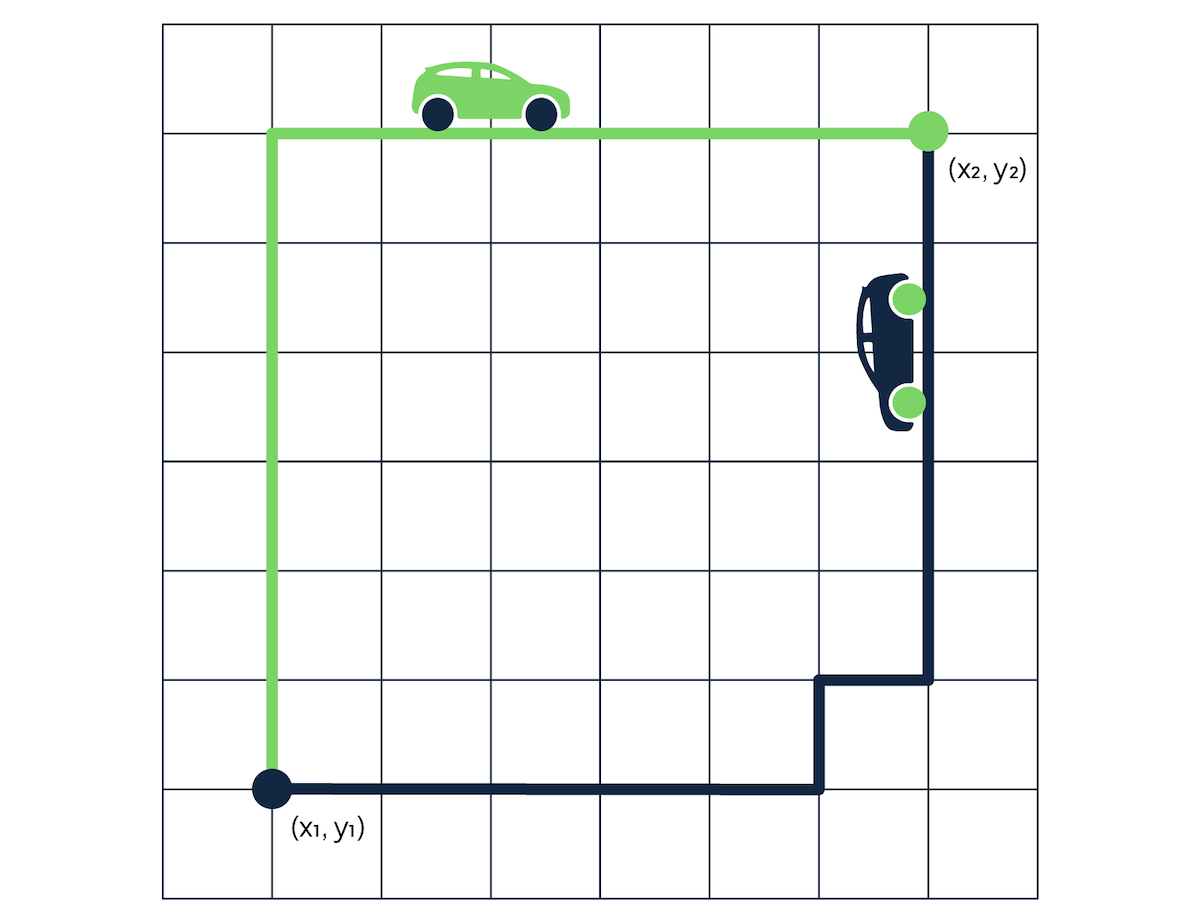
The Manhattan distance is calculated by adding up the differences between vector values.
Following our previous example:
- A
[1, 9, 3, 4, 5] - B
[1, 2, 3, 9, 5]
We can calculate the Manhattan distance in these steps:
- distance =
|1-1| + |9-2| + |3-3| + |4-9| + |5-5| - distance =
0 + 7 + 0 + 5 + 0 - distance =
12
For a deeper dive into the Hamming and Manhattan distances, check out our blog post on distance metrics. There you will learn how each of the distances works in more detail, when to use each, and how they compare to other metrics.
New Weaviate modules

The list of the new goodies included with Weaviate v1.15 goes on. Courtesy of a fantastic community contribution from Dasith Edirisinghe, we have two new Weaviate modules for you: Summarization and Hugging Face modules.
Summarization Module
The Summarization module allows you to summarize text data at query time.
The module adds a summary filter under the _additional field, which lets you list the properties that should be summarized.
For example, if we broke down this blog post into chapters in Weaviate, with title and content properties.
We could run a query to summarize the "New distance metrics" chapter like this:
{
Get {
Chapter(
where: {
operator: Equal
path: "title"
valueText: "New distance metrics"
}
) {
title
_additional{
summary(
properties: ["content"],
) {
property
result
}
}
}
}
}
Which would return the following result:
{
"data": {
"Get": {
"Chapters": [
{
"_additional": {
"summary": [
{
"property": "content",
"result": "Weaviate 1.15 adds two new distance metrics - Hamming
distance and Manhattan distance. In total, you can now choose
between five various distance metrics to support your datasets.
Check out the metrics documentation page, for the full overview
of all the available metrics in Weaviate."
}
]
},
"title": "New distance metrics"
}
]
}
},
"errors": null
}
Head to the Summarization Module docs page to learn more.
Hugging Face Module
The Hugging Face module (text2vec-huggingface) opens up doors to over 600 Hugging Face sentence similarity models, ready to be used in Weaviate as a vectorization module.
Now, that's a lot of new models. 😉
How this works
The way the module works, Weaviate coordinates the efforts around data imports, data updates, queries, etc. and delegates requests to the Hugging Face Inference API.
You need a Hugging Face API Token to use the Hugging Face module. You can request it here.
Note. Hugging Face Inference uses a pay-per-use pricing model.
Make sure to study it well before you run a big job.
To learn more, head to the HuggingFace Module docs page.
Other improvements and bug fixes
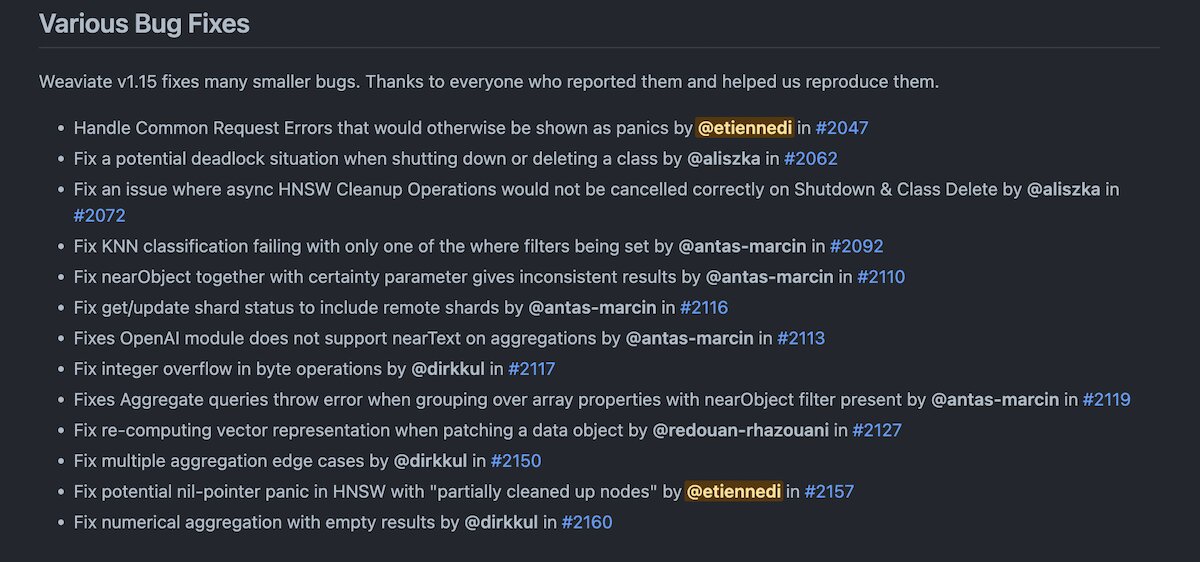
And, of course, there are many other improvements and bug fixes that went into this release.
You can find the complete list and the relevant links in the release notes.
Enjoy
We hope you enjoy all the new features, performance improvements, memory savings and bug fixes that made this the best Weaviate release yet!🔥
Ready to start building?
Check out the Quickstart tutorial, or build amazing apps with a free trial of Weaviate Cloud (WCD).
Don't want to miss another blog post?
Sign up for our bi-weekly newsletter to stay updated!
By submitting, I agree to the Terms of Service and Privacy Policy.