
Weaviate 1.16 release

We are happy to announce the release of Weaviate 1.16, which brings a set of great features, performance and UX improvements, and fixes.
The brief
If you like your content brief and to the point, here is the TL;DR of this release:
- New Filter Operators – that allow you to filter data based on null values or array lengths
- Distributed Backups – an upgrade to the backup functionality, which allows you to backup data distributed across clusters
- Ref2Vec Centroid Module – a new module that calculates a mean vector of referenced objects
- Node Status API – to quickly check on the health of your running clusters
- Support for Azure-issued OIDC tokens – now you can authenticate with Azure, Keycloak, or Dex OIDC tokens
- Patch releases – ready sooner – starting with Weaviate
1.15, we publish new patch releases as soon as new important fixes are available, so that you get access to all updates as soon as possible
Read below to learn more about each of these points in more detail.
New Filter Operators
One of the core functionalities of databases are the index structures that allow us to find data objects quickly. The ability to seamlessly combine an inverted index with a vector index is part of what makes Weaviate so powerful. An inverted index maps the property value to the objects that it appears in. This is important when filtering through your database to find specific data objects.
Filtering Null Values
When dealing with large datasets, it is very common to have objects with missing or null properties. Naturally, you might want to find the objects with missing properties and do a bit of cleaning up. With Weaviate 1.16 we introduced the possibility to query the null state. This applies to both scenarios where a property is set to null, or the property is completely missing.
This new feature introduces changes at three different stages of working with data in Weaviate.
Stage 1: Importing Null Value
When you import data into Weaviate, either with missing properties or with properties set to null - in both cases, Weaviate will do two things: Import the objects and skip the missing/null properties. Set the index (for the missing/null properties) values to null.
For example, imagine you have a dataset containing information about a group of people who might have food allergies. Both Noah and Emma don't have food allergies.
[{
"name": "Noah",
"age": "5"
},
{
"name": "Emma",
"age": "20",
"allergy": null
}]
Although Noah is missing the allergy property, it will still be imported as if it was set to null (similar to Emma's).
Stage 2: Indexing Null Values
Indexing null values is an optional feature since not everyone needs it, and it might add to import costs and space.
To filter by the null state, you need to first configure your schema to handle this. The target class needs the capability to track if a property within a class is null or not. This is done by setting the indexNullState field to True in the invertedIndexConfig object.
class_obj = {
"class": "FoodAllergies",
"description": "Properties include people, their age, and allergy",
"invertedIndexConfig": {
"indexNullState": True,
},
"properties": [ ... ]
}
Stage 3: Filtering for Specific Property State
We've added IsNull, a new operator that checks if a given property is set to null or not. The IsNull operator allows you to perform queries that are filtered by the null state.
With IsNull, you can run queries that filter the results based on the null state.
In other words, you can use IsNull to find all objects that miss a specific property or find only those that have the property populated.
Returning to our example, we can use the below where filter to find all people with information on their allergies.
# matching all non-null values
where: {
operator: IsNull
valueBoolean: false
path: ["allergy"]
}
Or we could find a list of people missing the information on their allergies.
# matching all null values
where: {
operator: IsNull
valueBoolean: true
path: ["allergy"]
}
For more information on how to use the IsNull filter, check out the documentation.
Filtering by Array Length
While designing the solution for filtering null values, we realized that we also needed an elegant solution to filter by array length.
The idea is to allow you to find objects based on the number of items in an array while also handling scenarios where the property is missing, which should count as 0 items.
Note. A zero-length array is equivalent to a null value.
Schema configuration
To filter by the length of an array, you need to configure your schema – with invertedIndexConfig – to handle this.
"invertedIndexConfig": {
"IndexPropertyLength": true
}
len(property)
We've added a new syntax - len(property) – to measure the length of the property.
Let's look at our example again and find people based on the number of allergies they have. George and Victoria both have more than one allergy.
{
"name": "George",
"age": "70",
"allergy": ["Wheat", "Shellfish", "Dairy"]
},
{
"name": "Victoria",
"age": "10",
"allergy": ["Dairy", "Wheat"]
},
You can find all people who have more than one allergy, with the following where filter:
where: {
operator: GreaterThan
valueInt: 1
path: ["len(allergy)"]
}
For more information on how to filter by the property length, check out the documentation.
Distributed Backups
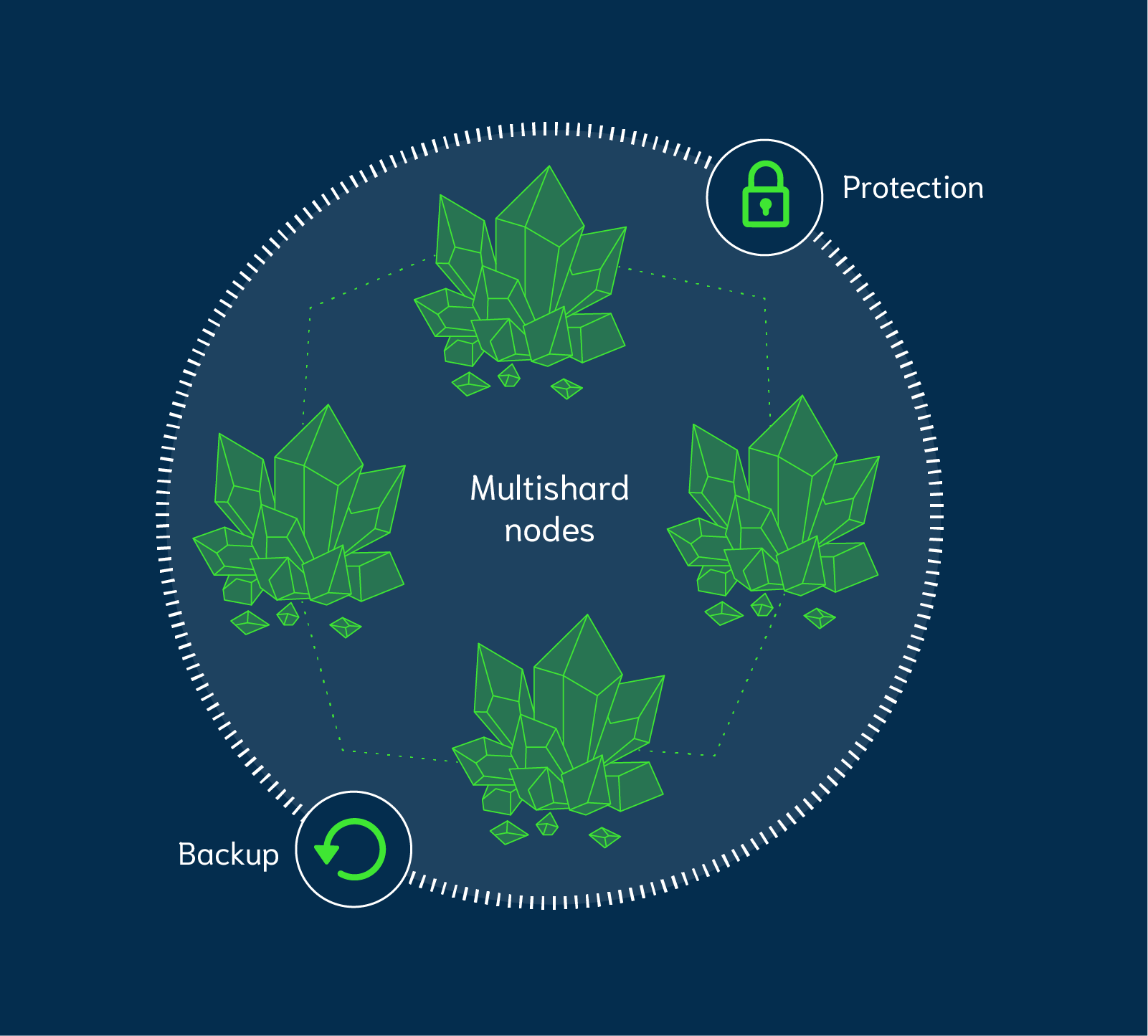
In Weaviate 1.15, we introduced backup functionality, which allows you to back up and restore your Weaviate schema and data (to local storage or a cloud provider, like GCS or AWS S3) with a single command.
This had one limitation though, you couldn't backup objects stored in multi-shard configuration across multiple nodes. This meant that if you wanted to back up your data, you were forced to keep all shards for a class in a single node.
Multi-sharded backups:
Weaviate 1.16 brings a major flagship change that now allows multi-sharded classes stored in a Weaviate cluster to be completely backed up! This is a significant improvement that now allows you to distribute your data across the cluster while ensuring a robust and safe way to restore objects when required.
Where previously, you had to decide between efficiently storing their data vs. being able to restore it. Now you have the flexibility to configure your data in a much more efficient and distributed manner while still maintaining the safety of a robust backup and restore solution.
Backward compatible
Before we give you a peek under the hood of how the new distributed backup and restore feature works, it's important to note that the APIs haven't changed at all, and thus you can keep using the platform exactly as before. To make it even better, the new backup feature is backward compatible, which means you can recover backups from v1.15 into a v1.16 setup.
We believe that this seamless user experience is one of the greatest value generators.
A peek under the hood - The delicate dance of distributed backup and restore:

Every node in Weaviate takes part in the delicate dance that allows for the backup and restore operations to take place across this distributed system.
Individual nodes are responsible for carrying out their own backup and restore operations that allow their shards to be preserved. They are also responsible for maintaining and communicating information about this entire process in the case of failure.
Every great choreographed dance needs a conductor. And the conductor of this whole distributed backup and restore show is a node called the Coordinator - a servant leader that makes sure that all participating nodes and shards carry out their own individual backup and restore operations, and communicate back to it once these tasks are completed.
ref2vec-centroid Module
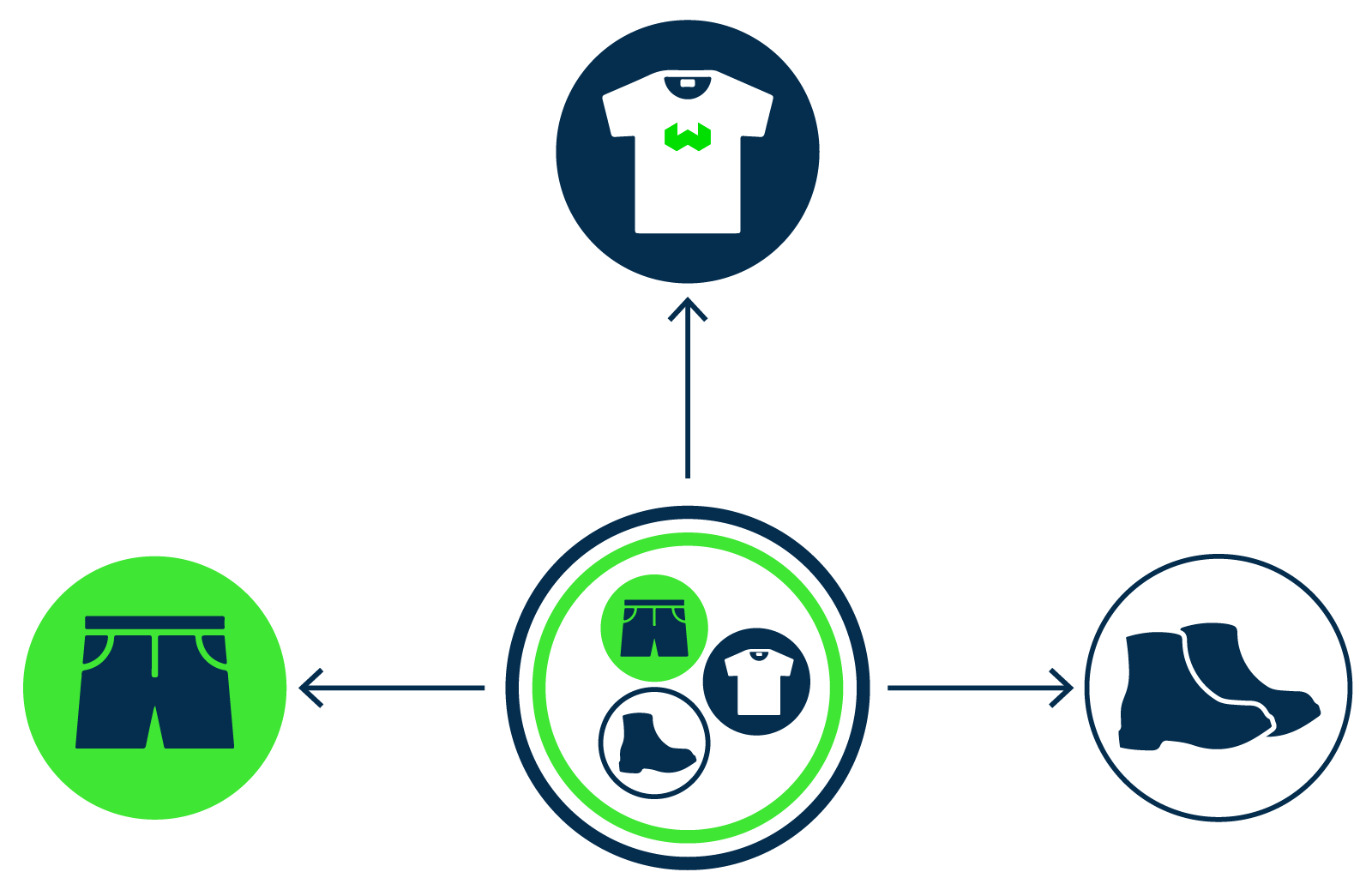
Weaviate 1.16 unveils the ref2vec-centroid module! Ref2Vec is about representing a data object based on the objects it references. The ref2vec-centroid module uses the average, or centroid vector, of the cross-referenced vectors to represent the referencing object.
Or in other words, if you have an object (i.e. a shopping basket) that contains a number of cross-references (i.e. "shorts", "shoes", and a "t-shirt"), Ref2Vec can provide you with a vector that is at the center (i.e. close to all other similar clothing items). This way you can use the references to find more relevant objects.
Applications
This module has applications in recommendation, knowledge graph representation, and representing long or complex multimodal objects.
Demo
The demo above illustrates ref2vec-centroid in action for sports apparel recommendation. You can see how the list of available items changes with every user's click. Ref2Vec aggregates the embeddings of the user's interactions and converts them into a vector to search through.
The images highlighted in green are those previously selected by the user. The number under each image is the "Distance to Centroid".
This example shows how a user may click on two watches or three backpacks and then have their search "personalized" to show more watches or backpacks. Further, we can see how clicking on two school-style backpacks helps clarify that the user isn't looking for a duffel bag, and similarly with digital LED-style watches.
Graph representations in Weaviate
Weaviate combines vector search with the ability to link classes to other classes through cross-references.
This is a big step for Weaviate to combine the power of content-based representations for individual objects with… context-based representations from relational graphs!
We are very excited about the roadmap to continue developing Ref2Vec for personalization and recommendation. We have begun with an average, or single centroid, to combine referenced vectors. In future iterations, we are looking at limiting the referenced vectors used in the calculator to a recent interaction window. We are also exploring how we can cluster the referenced vectors to represent users with multiple centroids to capture diverse interests. We are also developing query designs to leverage Collaborative Filtering in Weaviate through Ref2Vec.
As excited as we are about the applications in personalization and recommendation, we believe we are just scratching the surface of how we leverage semantic graphs in Weaviate for a better search experience.
Learn more
Check the ref2vec-centroid documentation to learn how to work with Ref2Vec.
Node Status API

The cluster doctor is in the house! Weaviate 1.16 introduces the node API endpoint, which allows you to check in on the health of your running clusters quickly. You can do this by sending a GET request to the node endpoint. As a response, you will receive a status check on all your nodes. Like this:
{
"nodes": [
{
"gitHash": "9e74add52",
"name": "node1",
"shards": [
{
"class": "Category",
"name": "XyPjB4rlWSwc",
"objectCount": 13
},
{
"class": "MainCategory",
"name": "LF1XCj88BjHK",
"objectCount": 4
},
{
"class": "Post",
"name": "GAi4O2TQ5oZw",
"objectCount": 221
},
{
"class": "Post",
"name": "bCWGjYHuNkv9",
"objectCount": 256
}
],
"stats": {
"objectCount": 494,
"shardCount": 4
},
"status": "UNHEALTHY",
"version": "1.16.0"
}
]
}
The node status can take one of the following values:
healthy– means all nodes are functional,disconnected– means a node is in the process of going down,unhealthy– means at least one of the nodes had encountered a problem and is now down.
Next steps
While right now this API can only display the current state of your clusters, in the future you'll also be able to manipulate the cluster (e.g. drain a node prior to removing it).
Learn more
Check the /v1/nodes documentation to learn how to use the Node Status API.
More powerful OIDC Auth
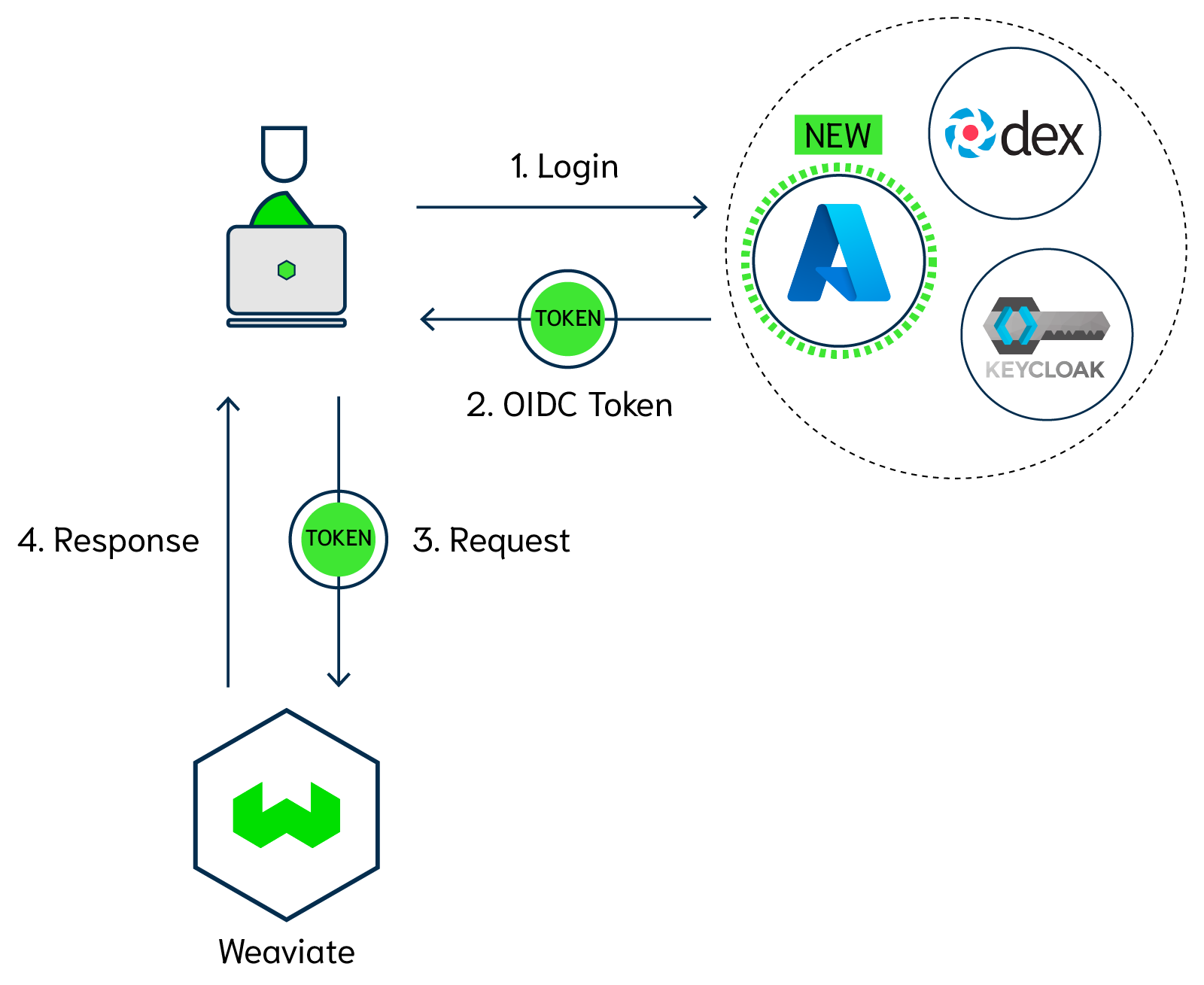
Security is very, very important. And let's face it - nobody wants to deal with yet another password. That's why we support OpenID Connect (OIDC) authentication in Weaviate, which users experience as a convenient and secure single sign-on.
Azure-based OIDC
OIDC implementations can vary across authentication servers, so we are steadily adding support for major providers. From this release onwards, Weaviate works with Microsoft Azure-based OIDC authentication in addition to other popular solutions such as Keycloak or dex. This will allow Weaviate to authenticate users based on their Azure Active Directory (AD) credentials. Support for scopes, and group claims have been added in this release, which also means that you can apply group-based authorizations.
OIDC adds resiliency to the authentication workflow, as it is robust to authentication server downtime outside of the short windows required for the client to obtain the ID token or for Weaviate to obtain the public key. While Weaviate runs without authentication by default, you can configure OIDC-based authentication schemes to provide differentiated access permissions. You can even configure Weaviate with multiple authentication schemes and allow tiered authorizations.
For example, your Weaviate instance could be set up so that anonymous users can read some resources, all authenticated users can read all resources, and a subset of authenticated users can write or delete resources.
We are pleased to add Azure-based OIDC authentication support. It will make managing your authentication and authorization needs even easier, especially for organizations already using Azure.
You can read more about each aspect below:
Patch releases ready sooner
In the past, whenever we were working on bug fixes between releases, we would wait until we had several bug fixes complete before cutting a patch release.
This felt like the right thing to do at the time. However, we've realized that this had one major drawback. You and everyone who relies on Weaviate's stability had to wait longer to get access to the improvements and fixes ready to go. This had to change! 🤔
The new way
Beginning with Weaviate 1.15, we decided to take a different approach and give you access to the latest and greatest as soon as we had it ready.
So, whenever we complete an important fix (or group of fixes) or introduce a significant feature improvement, we don't delay the release until other fixes are ready.
During the lifetime of v1.15, we created five stable releases. So that you didn't have to wait a day longer than necessary to get access to the important improvements.

Other improvements and bug fixes
And, of course, many other improvements and bug fixes went into this release.
You can find the complete list and the relevant links in the release notes.

Enjoy
We hope you enjoy all the new features, new operators, new modules, performance improvements, and bug fixes that made this the best Weaviate release yet!🔥
Ready to start building?
Check out the Quickstart tutorial, or sign up for a free Weaviate Cloud account.
Don't want to miss another blog post?
Sign up for our bi-weekly newsletter to stay updated!
By submitting, I agree to the Terms of Service and Privacy Policy.