
Long-Context Retrieval Models with Monarch Mixer
A breakdown of the Long Context Retrieval Embedding Models from Stanford!💥
In Short⏩:
-
They release 3 long context(2k/8k/32k) BERT-like encoder embedding models on HuggingFace
-
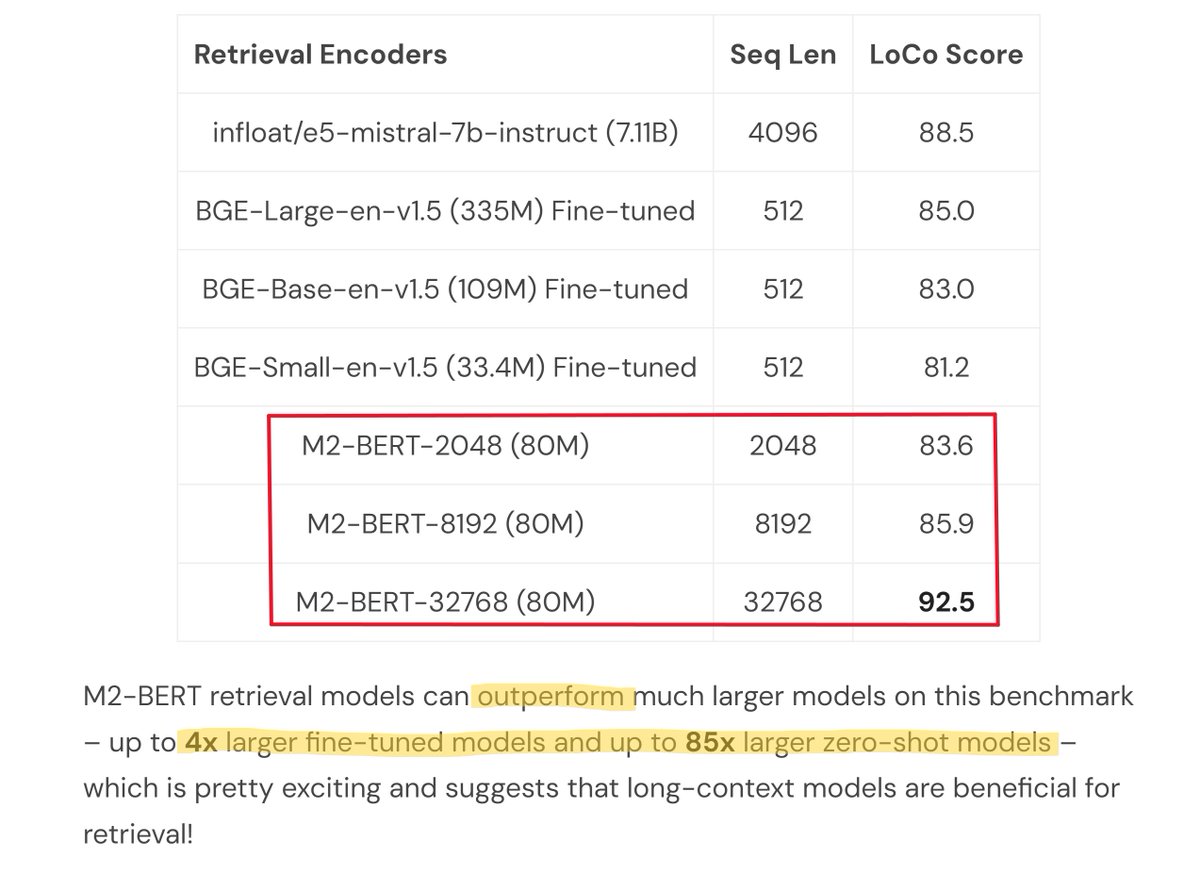
The models are only 80M params and outperform MUCH larger models (4-85x larger)
-
Accessible via @togethercompute endpoints and integrated into @llama_index and @LangChainAI
-
They also release LoCo a long context retrieval benchmark.
🏗️Architechtural Details:
-
They replace the Attention and MLP blocks in the transformer architecture with diagonal block matrix (Monarch Matrices -M2) operations which are hardware optimized and subquadratic in the sequence length - O(N^(1.5))
-
This enables scaling sequence length and model parameters better.
🪃Training Details:
-
These M2 models are trained for long context retrieval on a mixture of long and short context tasks data - surprisingly only training on long context doesn't work.
-
Use a cosine similarity loss instead of the trusty supervised contrastive training loss.
This loss function. can be computed independently per datapoint in a batch instead of needing to sum over all negative examples in a batch.
Thus training can be scaled for large batch sizes of long context inputs without OOM'ing
Ready to start building?
Check out the Quickstart tutorial, or build amazing apps with a free trial of Weaviate Cloud (WCD).
Don't want to miss another blog post?
Sign up for our bi-weekly newsletter to stay updated!
By submitting, I agree to the Terms of Service and Privacy Policy.