
Exploring RAG and GraphRAG: Understanding when and how to use both
Retrieval Augmented Generation (RAG) is an effective way to get AI to extract information from the specific set of data you want it to work with. The idea is relatively simple - although generative LLMs are amazing at what they do, they don’t know everything. So if we want an LLM to generate a response based on specific information in our documents, we have to provide it with that information (context) first.
RAG is the solution to that problem, and has become pretty much ubiquitous for most knowledge base search systems we see out in the wild today. What more can you need? In this article we want to highlight that your data and what it looks like, as well as the valuable information in your data, may dictate what kind of RAG is most effective for it.
While in many cases the relevant context may be found in the content of our data, there are applications where additional information can help improve performance of a RAG application. Graph RAG, for example, allows for context to be retrieved based on relations between data points in our database. With the combination of vector search based RAG and Graph RAG in a hybrid RAG system, we can return results not only on their contextual meaning, but also based on the relationships within our data. To help you understand the difference between the two approaches, we’ve also created a recipe that you can run with Colab.
🧑🍳 This blog comes with an accompanying recipe and helper functions which can all be found in the ms-graphrag-neo4j repository. You can also open the specific "Naive RAG vs GraphRAG with Neo4J & Weaviate" recipe as a Colab here
What is RAG & what is it good at
RAG stands for “Retrieval Augmented Generation”. Let’s zone in on the first word there: retrieval. The first step in getting an LLM to respond to something based on some specific context is to retrieve that relevant context in the first place.
What is Naive RAG?
Retrieving context can be done in many many ways, but by far the most common way is to do semantic search (vector search) over a given set of data. This brings us to the term “Naive RAG”, which is simply a basic question-answer system with vector search based retrieval. Within most RAG systems, the “R” (retrieval) is based on vector search. This allows us to use of the semantic meaning of a query and extract the most relevant data based on that meaning, using embedding models to encode both the user query and all the data we may have stored somewhere (vector databases like Weaviate that are designed to do just this).
Because of the fundamental nature of Naive RAG, it’s a great way of retrieving relevant context for any given query, which can then be used by an LLM to generate a response. Most datasets that include embeddings used for Naive RAG contain a list of “text” fields, and for each of them, we have an embedding:

An important thing to notice is that each entry is an independent entry. Each entry has meaning that can be represented by a vector (embedding). So, the only information Naive RAG has access to are the independent vectors for each entry. This way of representing data doesn’t represent any relationships between data points beyond the proximity of their meaning in vector space.
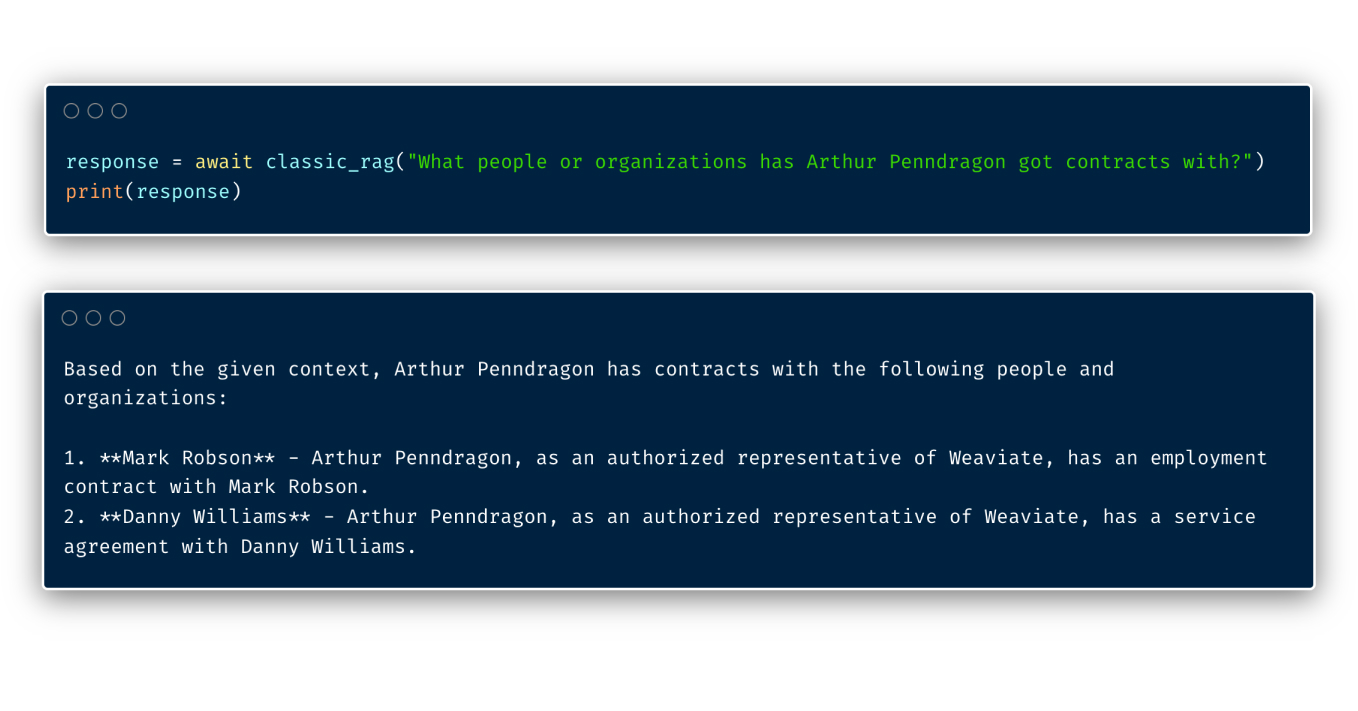
Take the example in our recipe. Here, we’ll be showcasing RAG over a dataset that includes (fake) contracts (such as partnerships, employment etc) that were signed between individuals and companies. For each contract, we have the contract_text, author and contract_type. We then go ahead and vectorize all of this information, where each contract has one vector representing its meaning.
When we ask a question about the data, it does a great job at fetching the most relevant contracts to the question we just asked.
Where Naive RAG is not enough
Now, in most cases the so-called relationships between data points may not be so relevant to any given search task. But with these contracts, you can probably already start to imagine that something that encodes relationships might be super valuable. For example, for each contract we retrieve, we know the author, but our retrieved context does not encode further information such as whether the person the author has signed a contract with has relationships to yet other authors. With that in mind, let’s move on to Graph RAG 👇
What is GraphRAG?
GraphRAG has recently become an umbrella term referring broadly to RAG approaches where the retrieval component specifically leverages knowledge graphs. Under this umbrella, numerous methods have emerged, each differing in how they utilize graph-based retrieval to enhance LLM responses (learn more here).
Among these, the GraphRAG implementation from Microsoft has risen as one of the most popular and widely-adopted approaches.

Microsoft's GraphRAG pipeline. Image from [Edge et al., 2024] licensed under CC BY 4.0.
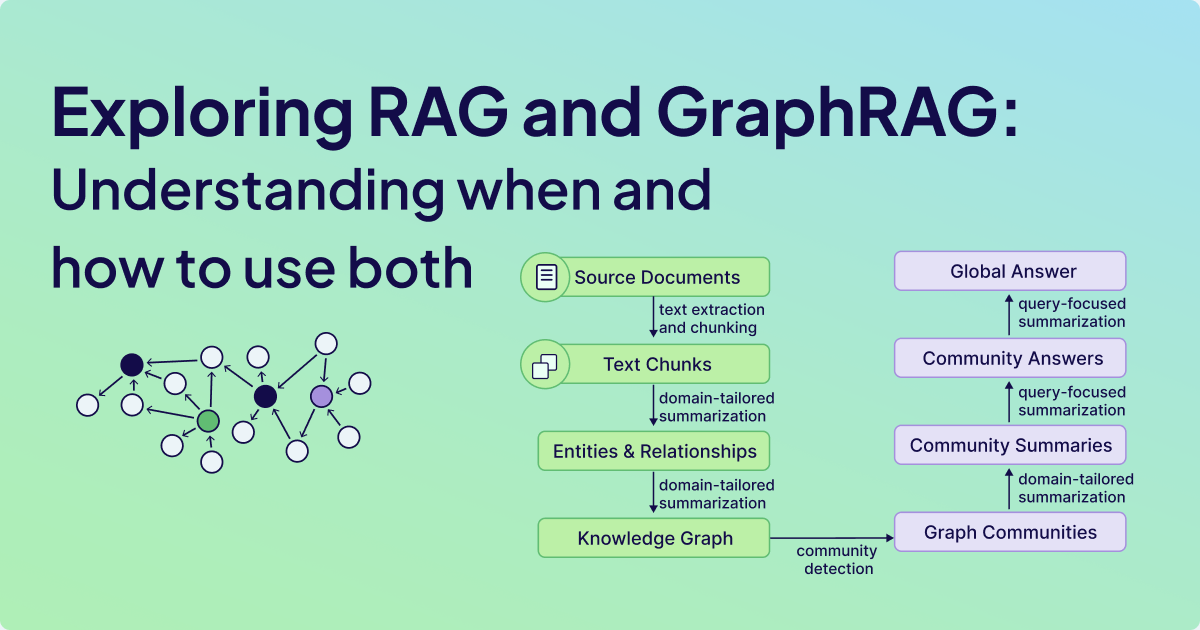
Microsoft's GraphRAG (MS GraphRAG) enhances knowledge graph construction by leveraging an LLM in a two-stage process. In the initial stage, entities and relationships are extracted and summarized from source documents, laying the foundation for the knowledge graph, as depicted in the pipeline illustration above.
How GraphRAG Extends Naive RAG Capabilities
What sets MS GraphRAG apart from naive RAG is its ability to detect graph communities and generate domain-specific summaries for groups of closely related entities once the knowledge graph is constructed. This layered approach integrates fragmented information from various text sources into a cohesive and organized representation of entities, relationships, and communities.
The resulting entity- and community-level summaries can be used to provide relevant information in response to user queries within a RAG application. Additionally, the structured knowledge graph enables the application of multiple retrieval approaches, such as a combination of graph search and vector search together, enhancing the overall search and retrieval experience
Implementing GraphRAG with Neo4j
For this blog post, we've developed a streamlined Python project that encapsulates all the prompts to avoid overwhelming you with extensive code. While this implementation is a proof-of-concept rather than production-ready code, it provides a practical demonstration. You can easily initialize a Neo4j driver and pass it to this simplified Ms Graph RAG implementation to see the concepts in action.
Extracting Entities and Relations
We use the same dummy financial dataset as we used in the baseline RAG implementation. This dataset comprises 100 contracts involving various parties. For MS GraphRAG method, the most critical configuration decision involves specifying which entity types should be extracted and summarized, as this selection fundamentally shapes all downstream results. Given our focus on contracts, we prioritize the extraction of key entity categories including Person, Organization, and Location.
allowed_entities = ["Person", "Organization", "Location"]
await ms_graph.extract_nodes_and_rels(texts, allowed_entities)
After the results we should have the following results:
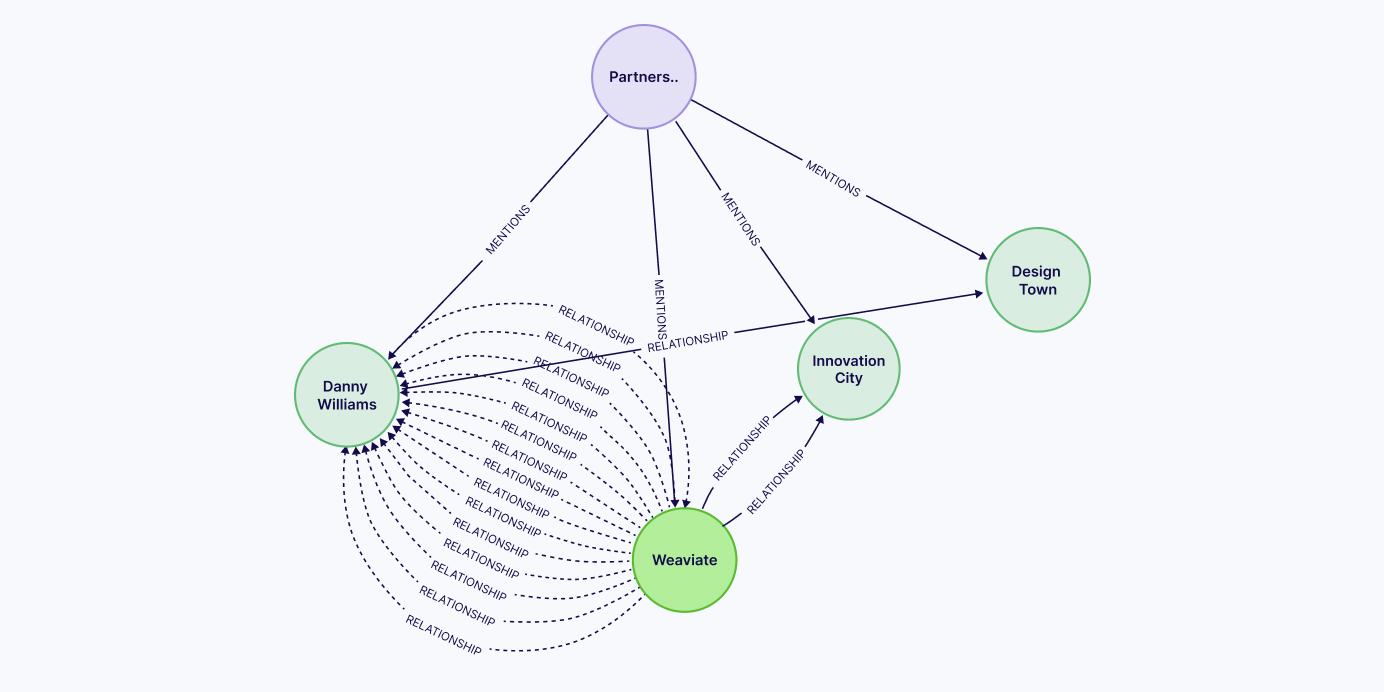
The purple node is the contract that contains its text and metadata, while the green nodes represent extracted entities. Each entity has a name and description, and they can have multiple relationships between each other, as shown in the above image.
Generating Community Summaries
When an entity is mentioned in multiple contracts, it will have multiple descriptions, as it gets one description per contract. Similarly, there can be multiple relationships between entities if they appear in multiple chunks. To consolidate the information, the implementation proceeds with entity and relationship summarization, where we use an LLM to generate concise summaries and resolve duplicates or redundant information.
await ms_graph.summarize_nodes_and_rels()
Results are:
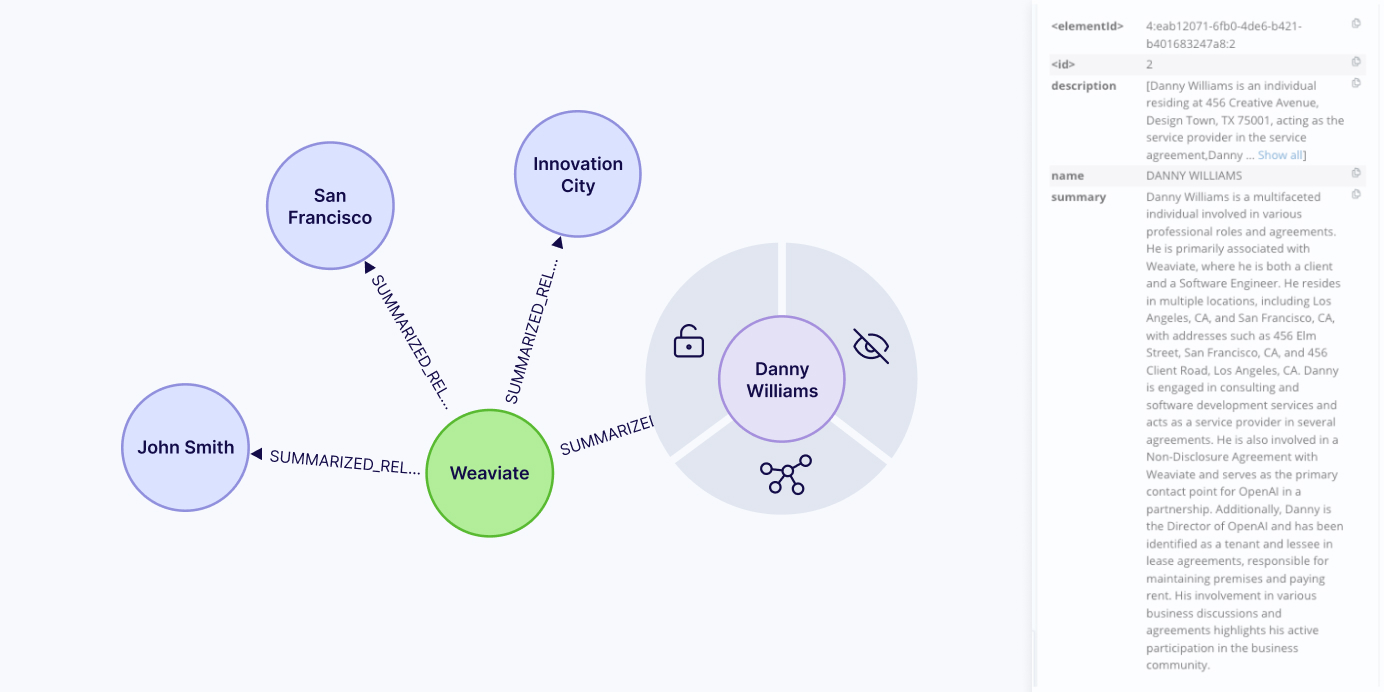
The revised model now displays a single consolidated relationship between entities, containing summarized information from all input sources. Furthermore, each entity receives a comprehensive summary, which can be quite detailed, as evidenced by the extensive profile generated for Danny Williams.
In the final phase of the indexing process, we employ graph algorithms, specifically the Leiden algorithm, to identify communities within the network. These communities represent clusters of densely interconnected nodes that exhibit stronger connections among themselves than with the rest of the graph.
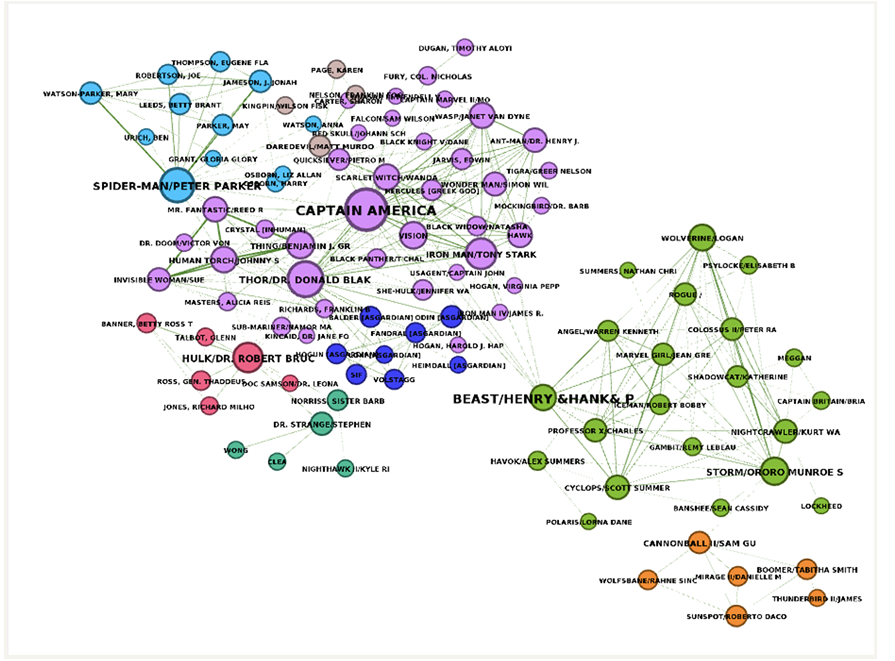
Communities are distinguished by entity color in this visualization. This illustrates how densely interconnected nodes naturally cluster to form communities.
The idea behind MS GraphRAG is to generate comprehensive high-level summaries that span multiple relationships and nodes. This provides a more holistic overview by synthesizing interconnected information into a cohesive picture.
await ms_graph.summarize_communities()
With a knowledge graph constructed, we can move onto the retrieval part.
Hybrid Local Graph & Vector Search
There are multiple effective methods for retrieving information from a knowledge graph. The Microsoft GraphRAG team demonstrates three distinct approaches:
-
Global search
-
Local search
-
DRIFT search
The local search approach generates responses by intelligently merging information from the AI-extracted knowledge graph with relevant text segments from the source documents. Local search is particularly effective for questions that require detailed understanding of specific entities or concepts documented in the corpus (e.g., "What therapeutic benefits does lavender oil provide?").
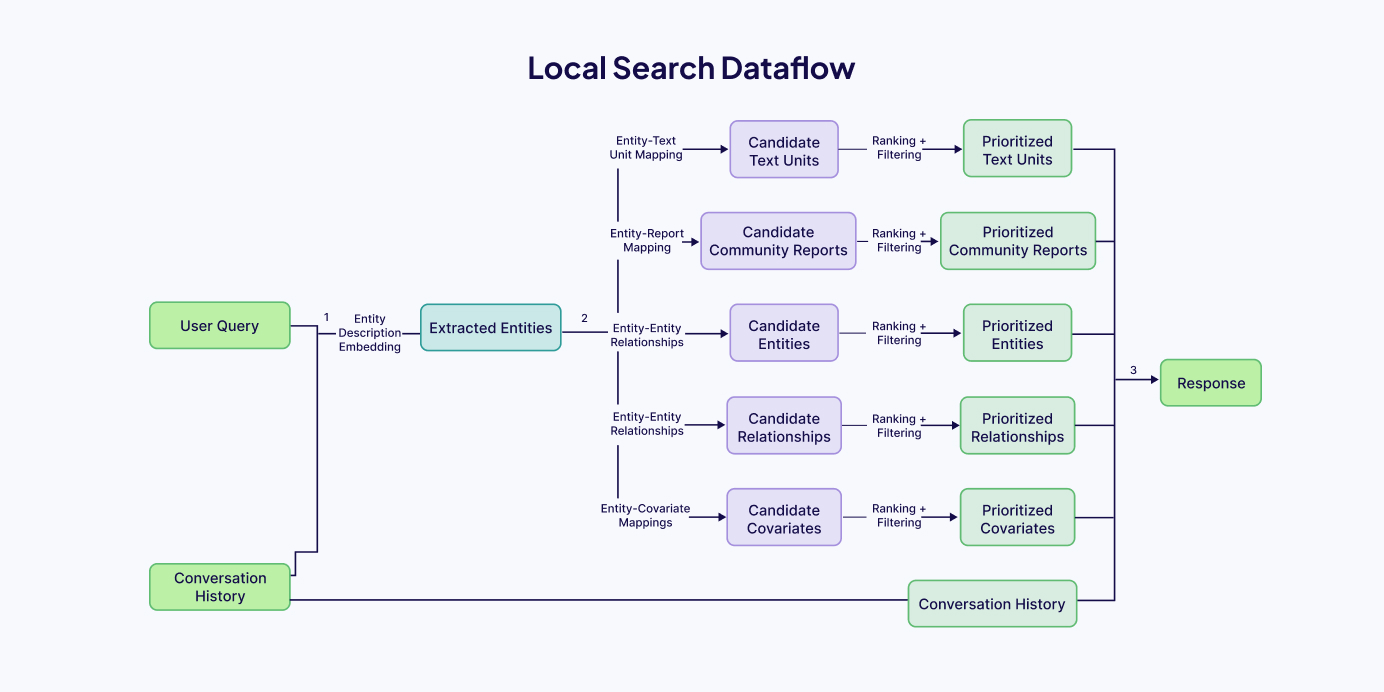
Local search is a retrieval and response generation method that works by finding the most relevant information in your document collection based on specific entities mentioned in a user's question. Here's how it works:
-
Entity Recognition: When a user asks a question, the system identifies key entities (people, places, concepts, etc.) that are semantically related to the query.
-
Knowledge Graph Navigation: These identified entities act as entry points into your knowledge graph, allowing the system to:
- Find connected entities (relationships)
- Extract relevant attributes and properties
- Pull in contextual information from community reports or other sources
After indexing our entities in Weaviate, we'll implement a retrieval pipeline that leverages both vector and graph databases. First, Weaviate's semantic search capabilities identify the most relevant entities based on the query's meaning. Then, we can use Neo4j's graph traversal capabilities to discover connected entities, relationships, and community structures, revealing both direct connections and broader contextual networks that might not be immediately apparent through vector search alone. This hybrid approach combines the semantic understanding of vector search with the relationship intelligence of graph databases for comprehensive information retrieval.
retriever = WeaviateNeo4jRetriever(driver=driver,
client=client,
collection="Entities",
id_property_external="entity_id",
id_property_neo4j="name",
retrieval_query=retrieval_query
)
First, we query the Weaviate vector database to identify relevant entities based on semantic similarity to the user's question. The retrieved entity IDs serve as linking points that we map to corresponding nodes within our Neo4j graph database.
Behind the scenes, the system then executes a Cypher query that traverses the knowledge graph, following relationships between entities and extracting contextually relevant information. The integration of both the semantic search capabilities of Weaviate and the relationship-oriented structure of Neo4j creates a retrieval system that understands both content and connections within your data. The retrieval query is:
retrieval_query = """
WITH collect(node) as nodes
WITH collect {
UNWIND nodes as n
MATCH (n)<-[:MENTIONS]->(c:__Chunk__)
WITH c, count(distinct n) as freq
RETURN c.text AS chunkText
ORDER BY freq DESC
LIMIT 3
} AS text_mapping,
collect {
UNWIND nodes as n
MATCH (n)-[:IN_COMMUNITY*]->(c:__Community__)
WHERE c.summary IS NOT NULL
WITH c, c.rating as rank
RETURN c.summary
ORDER BY rank DESC
LIMIT 3
} AS report_mapping,
collect {
UNWIND nodes as n
MATCH (n)-[r:SUMMARIZED_RELATIONSHIP]-(m)
WHERE m IN nodes
RETURN r.summary AS descriptionText
LIMIT 3
} as insideRels,
collect {
UNWIND nodes as n
RETURN n.summary AS descriptionText
} as entities
RETURN {Chunks: text_mapping, Reports: report_mapping,
Relationships: insideRels,
Entities: entities} AS output
"""
This Cypher query traverses from the initial set of entities to their corresponding neighbors, communities, chunks, and more.
If we test on the same example about Weaviate, we get the following answer (Note: all of the data for this demo is generated 👍):
Weaviate is a corporation organized under the laws of both the State of
California and the State of Delaware. Its principal place of business is
primarily located in San Francisco, CA, with additional offices at 123
Innovation Drive, Tech City, CA, and 123 Tech Lane, Silicon Valley, CA.
The company is involved in a wide range of activities, including
consulting, software development, data analysis, cloud storage, technical
support, and project management services. Weaviate is actively engaged in
partnerships to develop innovative AI solutions and advanced data
processing technologies, contributing resources and expertise to these
collaborations.
....
Known Limitations of GraphRAG
MS GraphRAG offers more entity-centric indexing and retrieval compared to traditional RAG's chunk-based approach, providing richer entity and community descriptions. However, it faces challenges with static LLM-generated summaries that require periodic full reindexing to capture updates when new data comes in. This indexing pipeline can incur substantial token costs. In contrast, traditional RAG does not require any reindexing pipeline for summary generation when new data is added, allowing for more efficient updates. Additionally, scalability might become problematic with nodes having thousands of connections, and highly-connected generic entity types must be filtered to prevent skewed results. The comprehensive preprocessing required for summarization represents both a strength for detail and a limitation for maintaining current information.
Summary
While Naive RAG is a simple and effective starting point for retrieval-augmented generation—especially when your data is well-structured and self-contained—Graph RAG takes things a step further by understanding the relationships and context between entities. It’s particularly powerful when your data is rich in connections and interdependencies, like contracts, research papers, or organizational records. By combining both approaches in a hybrid system, you can leverage the best of semantic similarity and structural insights to deliver more nuanced, accurate, and insightful responses. Whether you're just getting started with RAG or looking to push the boundaries with GraphRAG, choosing the right strategy starts with understanding your data.
Ready to start building?
Check out the Quickstart tutorial, or build amazing apps with a free trial of Weaviate Cloud (WCD).
Don't want to miss another blog post?
Sign up for our bi-weekly newsletter to stay updated!
By submitting, I agree to the Terms of Service and Privacy Policy.