
Multimodal Embedding Models

The Multisensory Nature of Human Learning
Humans have a remarkable ability to learn and build world models through the integration of multiple sensory inputs. Our combination of senses work synergistically to provide us with rich and diverse information about our environment. By combining and interpreting these sensory inputs, we are able to form a coherent understanding of the world, make predictions, and acquire new knowledge very efficiently.
The process of learning through multi-sensory inputs begins from the early stages of human development. Infants explore the world through their senses, touching, tasting, listening, and observing objects and people around them. This sensory exploration helps them link different perspectives of the same experience to create a holistic understanding of their environment.
This fusion of multisensory data when learning new concepts is also partially responsible for why humans can learn with very few data points - making us great few-shot learners. Let's imagine you are trying to teach the concept of a dog to a child. The next time you see a dog at the park you point it out and say “This is a dog!”. Let's say that this is a single observation/data point - in the supervised machine-learning sense. From this single data point, the child receives an abundance of information: they see how the dog moves, interacts, and reacts to the world around it, hear how the dog barks, see how the fur on the dog blows in the wind, can touch the dog to see how it feels and even smell the dog. So, from this single “data point” the child extracts a very rich representation of multiple interdependent modalities of data that very distinctly define the concept of a dog.

Over time and with age, this fusion of sensory inputs gets more refined and nuanced and allows infants to develop higher levels of abstraction and understanding of objects' properties, such as shape, texture, and weight.
Humans are such good multimodal reasoning engines that we do it without noticing - let's consider a practical scenario. Imagine you’re on an airplane and only have your wireless headset that cannot be plugged into the in-flight entertainment system - a predicament I find myself in more often than not these days!😅 So you start watching a movie with no sound and for the most part, you notice that you can get a pretty good, although imperfect, understanding of what’s going on. Now imagine you turn on the captions, and now you can understand pretty much everything that’s going on and you can even fill in sound effects with your imagination supported by the modalities of data you have available.
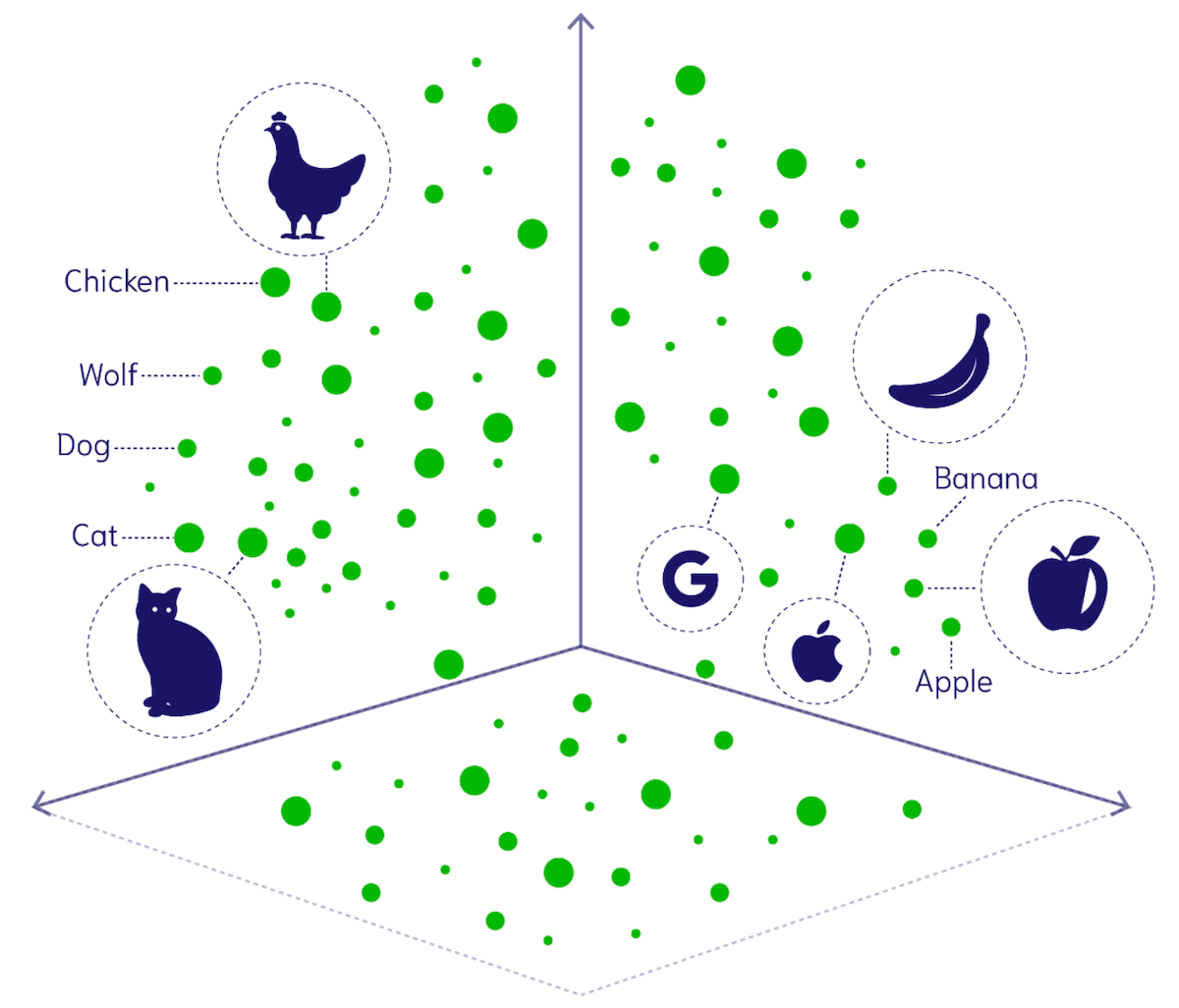
In order for our machine learning models to interact more naturally with data, the way we do, and ultimately be more general and powerful reasoning engines we need them to understand a data point through its corresponding image, video, text, audio, tactile and other representations - it needs to be able to preserve the meaning behind all of these data modalities once embedded in high dimensional vector space as demonstrated in Figure1 below. For example, in order to understand what a train is, we need our ML models to “see” and “hear” the train move, “feel” the motion of the ground near the train, and “read” about it. This is easier said and understood than done. Having a model that jointly comprehends all of these data modalities is very difficult, let's discuss some of the challenges that stand between us and truly multimodal models.
Addressing Challenges of Learning Multimodal Embeddings
1. Lack of Rich & Aligned Multimodal Datasets
Collecting and preparing multimodal datasets is very challenging. Each modality requires specific data collection techniques and preprocessing steps. Furthermore aligning and normalizing the data across modalities is crucial to ensure compatibility. This is quite challenging due to differences in data formats, temporal alignment, and semantic alignment. If the data is stitched together from different datasets and is not aligned properly then it becomes very difficult for the machine-learning model to extract and learn interdependencies between the modalities.
Current approaches address this by taking multiple rich datasets and fusing them across data modalities where possible. So for example you might be able to combine the image/video of a lion from a computer vision dataset with the roar of a lion from an audio dataset but perhaps not with motion since you might not have motion data for a lion. There are also attempts to collect richer multimodal datasets such as the EGO4D which collects multiple data modalities for a given scenario. EGO4D actually captures motion/tactile data by capturing accelerometer and gyroscopic data temporally aligned with video captures of activities! The problem with this is that generating a rich multimodal dataset is very costly and even impractical in some cases.
2. Model Architecture
Designing the architecture for a single model that can process multimodal data is difficult. Usually, machine learning models are specialists in one domain of data - for example computer vision or natural language. Training a single, jack-of-all-modalities model is very difficult.
Current multimodal approaches like ImageBind from FAIR, Meta AI(which combines image, speech, text, video, motion and depth/thermal data) approach this problem by taking separate specialist pre-trained models for each modality and then finetuning them to bind their latent space representations using a contrastive loss function; which essentially pulls together representations of similar examples across modalities closer together and pushes apart distinct examples in a joint vector space. The key insight is that all combinations of paired modalities are not necessary to train such a joint embedding, and only image-paired data is sufficient to align and bind the modalities together. The limitation however is that adding and finetuning a separate pretrained model for every modality or task becomes prohibitively expensive and is not scalable.
3. Model Interpretability
Understanding and interpreting the decisions made by multimodal models can be challenging. The fusion of different modalities may introduce complexities in interpreting the learned representations and attributing importance to each modality. Consider, for example, searching in the learned joint embedding space of a multimodal model what accelerometer motion data is closest to a person giving a speech about globalization. The lesson is that some modalities or data objects just don’t pair together naturally.
The ImageBind model handles this by using the image representation as ground truth and pulling all other concepts closer to image representations which then establishes a naturally learned alignment between other modalities. These image representations are initialized with large-scale vision-language models such as CLIP, thereby leveraging the rich image and text representations of these models. Some of these alignments are explained directly (comparing a video of a person delivering a speech to audio of the speech) while other pairs of modalities are explained through their relation to an intermediate modality(understanding the relation between motion data and text data by seeing how they both relate to video/image data). With that said in other cases a logical explanation of why two examples are close together might not be possible without a close examination of the training sets.
4. Heterogeneity and Training Optimization
Handling modality imbalance(we have a lot of image and text data and significantly less motion and tactile data) makes it very difficult to learn all modalities equally well; this takes careful tuning of the contribution of each modality during training and optimizing the fusion mechanism to prevent dominance by a single modality. Data imbalance is one consideration but even more important to consider is how much unique information a modality brings - this is known as heterogeneity. Assessing heterogeneity accurately allows you to decide which modalities are different enough to be separately processed and which modality pairs interact differently and thus should be differently fused.
HighMMT has been proposed to handle high-modality scenarios involving a large set of diverse modalities. HighMMT uses two new information-theoretic metrics for heterogeneity quantification, enabling it to automatically prioritize the fusion of modalities that contain unique information or unique interactions. This results in a single model that scales up to 10 modalities and 15 tasks from 5 different research areas, demonstrating a crucial scaling behavior not found in ImageBind: performance continues to improve with each modality added, and it transfers to entirely new modalities and tasks during fine-tuning.
In conclusion, efforts on developing multimodal models attempt to mimic human learning by combining different inputs, such as images, text, and audio, to improve the performance and robustness of machine learning systems. By leveraging multi-sensory inputs, these models can learn to recognize complex multimodal patterns, understand context across modes, and generate more comprehensive and accurate outputs even in the absence of some modalities. The main goal is to give these models the ability to interact with data in a more natural way thus enabling them to be more powerful and general reasoning engines.
Multimodal Models in Weaviate
Currently, the only out-of-the-box multimodal module that can be configured and used with Weaviate is multi2vec-clip which can be used to project images and text into a joint embedding space and then perform a nearVector or nearImage search over these two modalities. Outside of this, you can only use multimodal models if they are hosted on Huggingface or if you have your own proprietary multimodal models. We know that our users love multimodal models and we’ve been cooking up more OOTB integrations with cutting-edge multimodal models so that it’s easy for you to start using them in your vector search pipelines. Be on the lookout for new multimodal search capabilities soon, I “hear” it's going to be amazing.😉
Ready to start building?
Check out the Quickstart tutorial, or build amazing apps with a free trial of Weaviate Cloud (WCD).
Don't want to miss another blog post?
Sign up for our bi-weekly newsletter to stay updated!
By submitting, I agree to the Terms of Service and Privacy Policy.