
Weaviate 1.20 Release

Weaviate 1.20 is here!
As always, a brand-new release means a set of brand-new features. Here are the ⭐️highlights⭐️:
- Multi-tenancy – A scalable, efficient and easy solution for use-cases with many tenants per Weaviate cluster.
- PQ + Re-scoring – Product quantization (PQ) allows for faster vector search - now at basically no cost to accuracy!
- Autocut – A new way to set a threshold - set how many groups of results to retrieve from the result set.
- Search re-ranking – Multi-stage search (& re-ranking) for better end results. Multiple re-rankers available!
- New hybrid search ranking algorithm – Additional method available for deriving hybrid search scores.
- And more.
We hope we've whetted your appetite - so what're you waiting for?! Keep scrolling ⬇️!
1.20 not possibleDowngrading from 1.20.x to a 1.19.x or lower is not possible.
Please proceed with caution, such as by making a backup of your data & schema, or cluster before upgrading.
Multi-tenancy
Store data from up to millions of tenants in a single setup.
We’ll keep this brief as Etienne covered this in great detail in this blog post. The key point, though, is that Weaviate now makes it easy to store data from up to millions of tenants in a single setup.
This means that scaling your business or infrastructure to include data from a large group of users is easier and faster than ever. We have worked with our community on this feature to ensure that your compliance needs are met as well as performance needs, while keeping the experience a smooth one for everybody. Our multi-tenancy implementation allows for huge numbers of diverse users - whether they be large or small, and regardless of how often they access Weaviate.
The result is a multi-tenancy solution that we are very proud of. This is an opt-in feature, where to use multi-tenancy, you simply enable the feature and add the tenant key for each operation as required.
PQ + Re-scoring
Compress vectors with little to no recall loss.
With 1.20 we’ve improved Product Quantization (PQ) by leaps and bounds and are officially taking it out of experimental mode! Originally PQ was introduced and released in 1.18 and we wrote about it here.
The short summary is that we’ve made a myriad of improvements around query speed performance, convenience of use with large datasets, added disk retrieval and rescoring to improve recall and more.
For all the nitty gritty details, take a look at the below sections
Query Performance
With 1.20 we’ve improved query performance when PQ is enabled by implementing a more efficient DistanceLookupTable.
This was mainly accomplished in two ways:
-
We restructured arrays by collapsing two-dimensional slices into a single dimension. This serves multiple purposes: It improves cache locality during lookups since now allocated memory is contiguous. It allows us to decrease the number of allocations that need to be made. We now allocate one slice as opposed to 128+ sub-slices. This also means that we no longer need to save unnecessary slice headers, further reducing the overall size.
-
We added a pool to reuse lookup lists between requests.
Rescoring for Recall Performance
We’ve also improved recall by adding PQ rescoring efficiently to avoid any deterioration in performance. At first, when we calculate nearest neighbor distances, we only use compressed vector representations, this helps reduce memory requirements. However this distance might be inaccurate due to the distortion introduced by the lossy nature of PQ compression. This small distortion could affect the order/ranking of the vectors in the retrieved set which in turn affects the quality and relevance of the search results. To correct for this, we fetch from disk the uncompressed representation of all vectors in the final retrieved set, recalculate the distances to the query vector, and resort the list. After this rescoring phase we are then ready to respond to the query.
Additionally, with the introduction of rescoring, detailed above, we no longer need to support having more than 256 centroids - based on our testing one byte per code should be more than enough. We use this to optimize the codebook and gain performance by allowing the compiler to inline the extract/put code. We also don’t need to cast bytes into uint64 anymore since the size is fixed.
Fit Time on Large Datasets
Previously, if you added a large number of objects prior to enabling quantization the PQ fitting algorithm would take a long time - putting the index into read-only mode. With 1.20 we’ve introduced the trainingLimit parameter which lets you define an upper limit on how many objects are used to train the PQ algorithm irrespective of the number of objects added to Weaviate. This parameter defaults to 100000 and so for large datasets if you load more objects, prior to enabling PQ, only trainingLimit subset will be used to train PQ - thus limiting the time it takes to fit. In addition to these major changes, we’ve also fixed numerous bugs.
Experiments - Before & After
Below we provide a small taste of these experiments comparing PQ 1.18 vs the new and improved PQ of 1.20. Firstly we show the performance on an experimental dataset followed by a more real-world dataset.
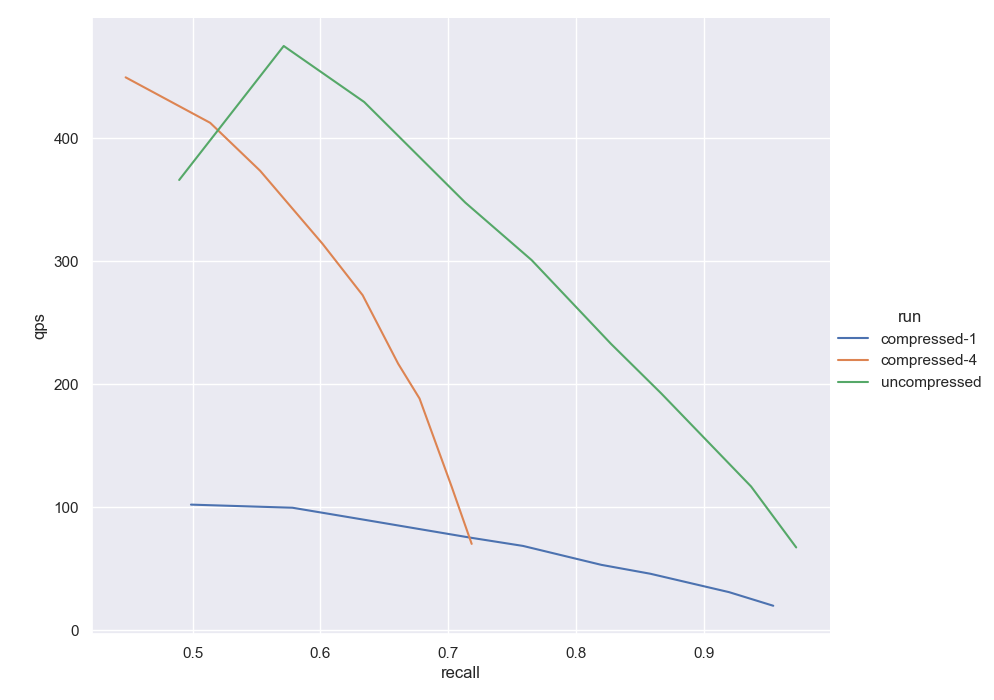 Figure 1: Before(V1.18) Using Gist+l2. The Green curve is obtained using uncompressed vectors. Blue compressing with 960 segments (a dimension per segment, 4:1 compression ratio). Orange uses 240 segments (4 dimensions per segment, 16:1 compression ratio).
Figure 1: Before(V1.18) Using Gist+l2. The Green curve is obtained using uncompressed vectors. Blue compressing with 960 segments (a dimension per segment, 4:1 compression ratio). Orange uses 240 segments (4 dimensions per segment, 16:1 compression ratio).
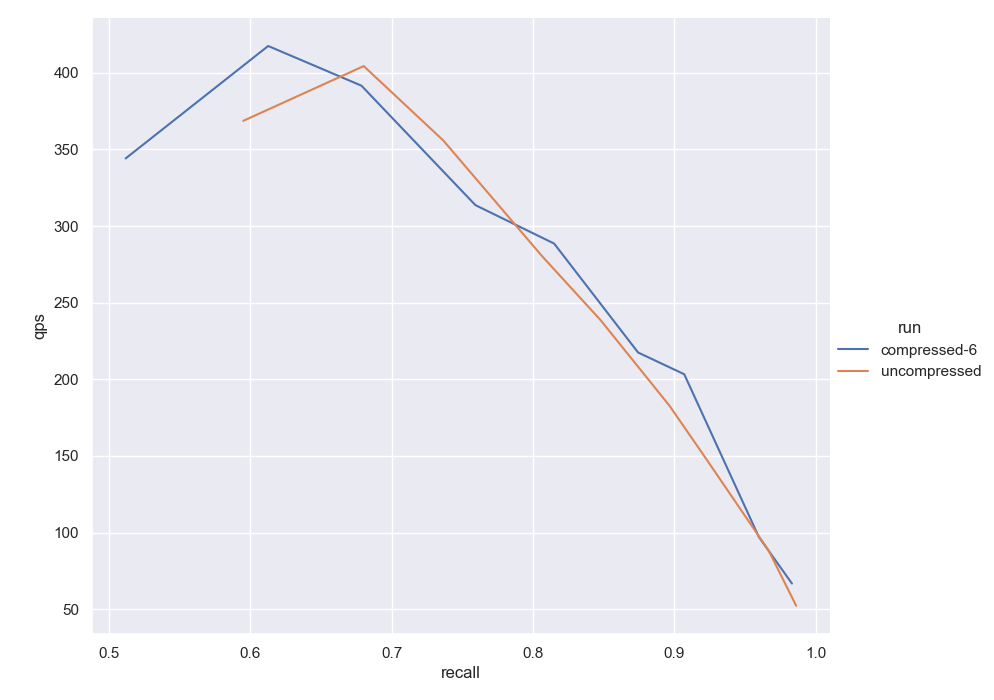 Figure 2: After(V1.20) Using Gist+l2. Both graphs are built using 32 max connections. The orange curve is obtained using uncompressed vectors. The blue when compressing with 160 segments (six dimensions per segment, 24:1 compression ratio).
Figure 2: After(V1.20) Using Gist+l2. Both graphs are built using 32 max connections. The orange curve is obtained using uncompressed vectors. The blue when compressing with 160 segments (six dimensions per segment, 24:1 compression ratio).
A more real-world dataset example:
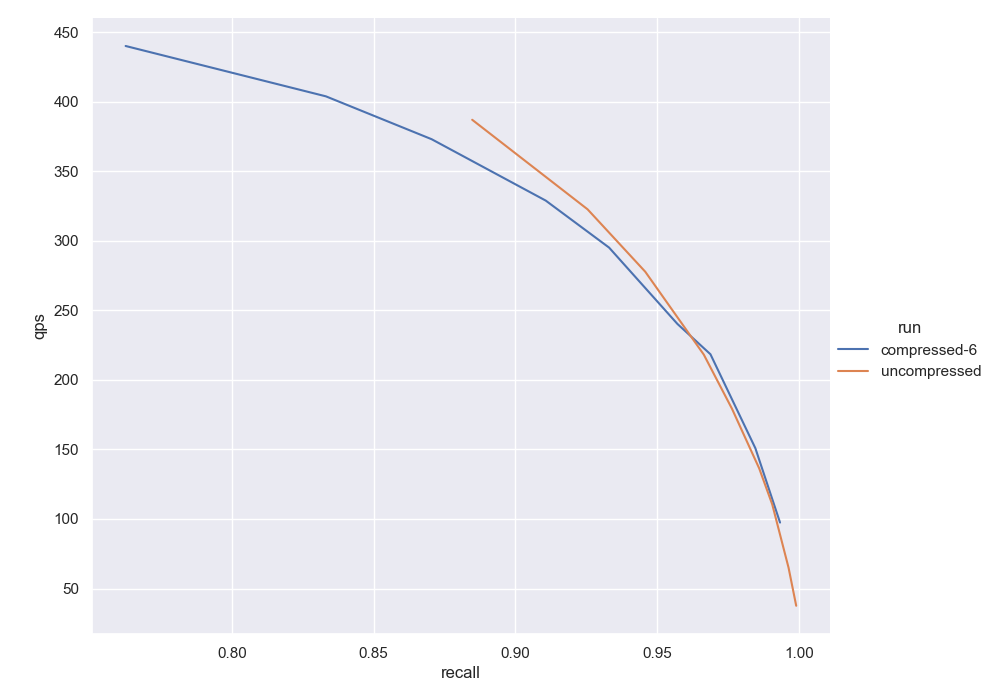 Figure 3: Using DBPedia vectorized with OpenAI
Figure 3: Using DBPedia vectorized with OpenAI ada002 using 500,000 vectors + cosine (V1.20). Both graphs are built using 32 max connections. The orange curve is obtained using uncompressed vectors. The blue is obtained by compressing with six dimensions per segment, 24:1 compression ratio.
As can be clearly seen above, previously there was a cost to be paid for compressing whereas now there is no real cost - compressed vs uncompressed performance is nearly identical even at high compression ratios. In addition to the experiments above, where we use Gist and ada002 vectorized DBPedia, we’ve also done many more tests using real-world datasets including high-dimensional vectors such as Meta’s Sphere. These tests demonstrate that we can generate high recall with PQ + rescoring achieving significant memory reduction. More to follow on these detailed experiments soon!
Autocut
Ask Weaviate to retrieve groups of results for convenience.
Before 1.20, limiting the number of search results meant manually specifying a distance or the limit (max) number of objects. Both of which can be a bit cumbersome to use, especially with no prior knowledge of the dataset.
With Autocut, you can solve this by simply specifying the number of groups of results to be returned. Each "group" is determined by reviewing distances between results, so that a "jump" in distance between results is considered a new group.
Autocut explained with an example
More concretely, imagine a set of hypothetical results to a query “large economy” from a dataset of countries. The results are sorted by distance from the query.
| Title | Distance | Gap > 0.07 | Group |
|---|---|---|---|
| United States | 0.07 | ✅ | 1 |
| China | 0.09 | ❌ | 1 |
| Japan | 0.23 | ✅ | 2 |
| France | 0.31 | ✅ | 3 |
| Canada | 0.33 | ❌ | 3 |
| Russia | 0.36 | ❌ | 3 |
| Indonesia | 0.48 | ✅ | 4 |
| Switzerland | 0.50 | ❌ | 4 |
| Taiwan | 0.51 | ❌ | 4 |
| Poland | 0.53 | ❌ | 4 |
You might see that there’s a relatively large jump in distance between some results, for example between “China” and “Japan”, and another one between “Japan” and “France”. Each autocut group would be based on these.
Here, an autocut value of 1 would return all "group 1" results (i.e. the first 2 results), an autocut value of 2 would return all "group 1" and "group 2" results (i.e. the first 3 results), and so on.
An example GraphQL query with Autocut
This example searches the Article class for articles related to "america", and retrieves the top 3 groups with Autocut.
{
Get {
Article (
nearText: {
concepts: ["america"]
},
autocut: 3
) {
prop1
prop2
}
}
}
Please refer to our documentation for more code examples, including for various Weaviate client libraries.
Motivation for Autocut
The first motivation for Autocut was to provide a better experience to human searchers. By only delivering relevant results, we present a cleaner user interface for information discovery. In addition to human search, there is also fascinating research on how this impacts generative search: in "Large Language Models Can Be Easily Distracted by Irrelevant Context", Shi et al. have shown that model performance is dramatically decreased when irrelevant information is included in the prompt. This led to the second motivation for the autocut filter: limiting irrelevant search results that would be fed to generative search.
Autocut aims approximate where a user would “cut” the results intuitively after observing N jumps in the distance from the query.
It can be combined with all vector search operators: nearXXX, bm25, and hybrid. autocut is placed after the operator, at the same level with limit/offset. It is disabled by default and can be explicitly disabled by setting its value to 0 or a negative number.
Search re-ranking
Multi-stage search for a better final results set.

We are introducing our first set of rerankers with two modules:
- Cohere’s reranker, and
- Integration with Sentence transformers cross-encoders.
Rerankers can improve the quality of the result set by reordering the results of a search, using a more expensive process than the initial search. As a reranker works on a smaller subset of data, different approaches can be used to improve search relevance.
With our reranker modules, you can conveniently perform multi-stage searches without leaving Weaviate.
In other words, you can perform a search - for example, a vector search - and then use a reranker to re-rank the results of that search. Our reranker modules are compatible with all of vector, bm25, and hybrid searches.
An example GraphQL query with a reranker
You can use reranking in a GraphQL query as follows:
{
Get {
JeopardyQuestion(
nearText: {
concepts: "flying" # search for "flying"
}
limit: 10
) {
answer
question
_additional {
distance
rerank(
property: "answer"
query: "floating" # sort "floating" results towards the top
) {
score
}
}
}
}
}
Please refer to our documentation for more code examples, including for various Weaviate client libraries.
This query retrieves 50 results from the Product class, using a hybrid search with the query “What is ref2vec?”. It then re-ranks the results using the content property of the Product class, and the query “what is ref2vec?”.
You can specify which property of the Product class you want to pass to the reranker. Note that here, the returned score will include the score from the reranker.
This is just a first step in integrating ranking models with Weaviate. Read our blog here for further thoughts on this exciting space, and let us know what you want to see next 😉!
New hybrid search ranking algorithm
A score-based hybrid results merger algorithm.


Hybrid search uses results from a keyword (BM25) search and a vector search to produce its final set of results. In 1.20, we introduce a new, optional, ranking algorithm that takes the BM25 and vector search scores to produce a more nuanced ranking of objects.
We are calling this the relative score fusion ranking algorithm, as it works by normalizing and summing the BM25 score and vector similarity values. This is in contrast to the existing ranked fusion algorithm which produced a new rank based on a sum of inverses of the BM25 and vector rankings.
Example GraphQL query with relative score fusion
In this example, we perform a hybrid search on the Question class, using the query “food”. We specifically tell Weaviate to use the relative score fusion algorithm to rank the results.
{
Get {
Question (
limit: 3
hybrid: {
query: "food"
fusionType: "relativeScoreFusion"
}
) {
question
answer
}
}
}
Please refer to our documentation for more code examples, including for various Weaviate client libraries.
In our internal benchmarks, it showed improved recall performance over the existing algorithm, and we encourage you to try it out. This change also enables the new AutoCut feature to be used with hybrid searches, allowing you to automate how the search result threshold is set.
Stay tuned, as we’ll be describing the relative score fusion feature in more detail in a separate blog post soon 👀.
And more!


Request success/failure rate in Prometheus metrics
With 1.20 we’re rolling out a way to monitor the fraction of requests that succeed/fail due to user errors, and/or server errors. This enables us to track these ratios over time and see if significant updates affect this. Having a code for each request simplifies the log monitoring process!
Given this new way to track each request, we have added a new metric, requests_total. There are three possible statuses:
ok: request was successfuluser_error: request ended with an error, that is mostly due to users wrong API usageserver_error: request ended with an unexpected error
Additionally, there are three labels associated with this metric:
api:graphqlorrestquery_type: name of the endpointGet/Aggregate/Explore/batch/classification/misc/nodes/objects/schema/backup
class_name: name of your class
Example requests
Here are some example requests:
requests_total{api="graphql",class_name="n/a",query_type="",status="ok"} 839
requests_total{api="graphql",class_name="n/a",query_type="",status="user_error"} 3
requests_total{api="graphql",class_name="n/a",query_type="Aggregate",status="user_error"} 8
requests_total{api="graphql",class_name="n/a",query_type="Explore",status="user_error"} 3
requests_total{api="graphql",class_name="n/a",query_type="Get",status="user_error"} 28
requests_total{api="rest",class_name="n/a",query_type="batch",status="ok"} 1143
requests_total{api="rest",class_name="n/a",query_type="classification",status="ok"} 9
requests_total{api="rest",class_name="n/a",query_type="misc",status="ok"} 14
requests_total{api="rest",class_name="n/a",query_type="nodes",status="ok"} 12
requests_total{api="rest",class_name="n/a",query_type="objects",status="ok"} 839
requests_total{api="rest",class_name="n/a",query_type="objects",status="server_error"} 4
requests_total{api="rest",class_name="n/a",query_type="objects",status="user_error"} 56
requests_total{api="rest",class_name="n/a",query_type="schema",status="ok"} 552
requests_total{api="rest",class_name="n/a",query_type="schema",status="user_error"} 55
The full list of metrics that are offered can be found here
Chaos benchmarks improvements
Scalability and performance are front of mind for us and as such with 1.20 we’ve introduced new chaos engineering style pipelines to help us assess Weaviate's performance and recall on ANN benchmarks including assessing Weaviate performance on PQ compressed vs. uncompressed vectors.
Summary
That's it from us - we hope you enjoy the new features and improvements in Weaviate 1.20. As always, the new Weaviate releases are available on WCD just a short time after the open source release. So it'll be available for you to use/upgrade very soon.
Thanks for reading, and see you next time 👋!
Ready to start building?
Check out the Quickstart tutorial, or sign up for a free Weaviate Cloud account.
Don't want to miss another blog post?
Sign up for our bi-weekly newsletter to stay updated!
By submitting, I agree to the Terms of Service and Privacy Policy.