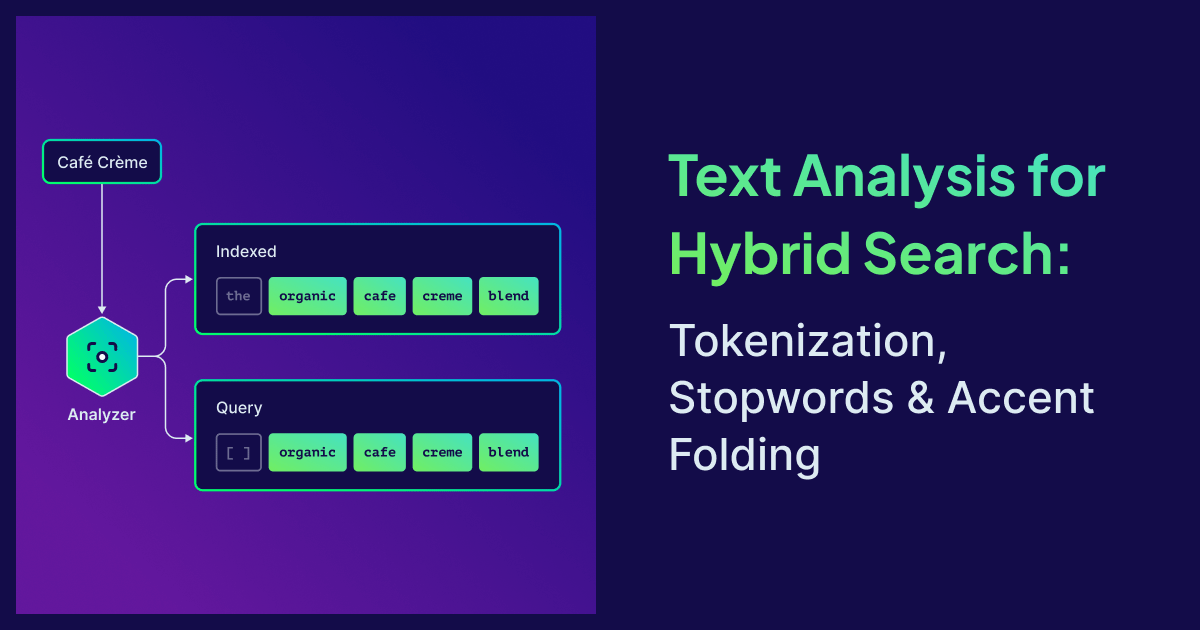
Query Profiling: See Where a Slow Query Spends Its Time
· 10 min read
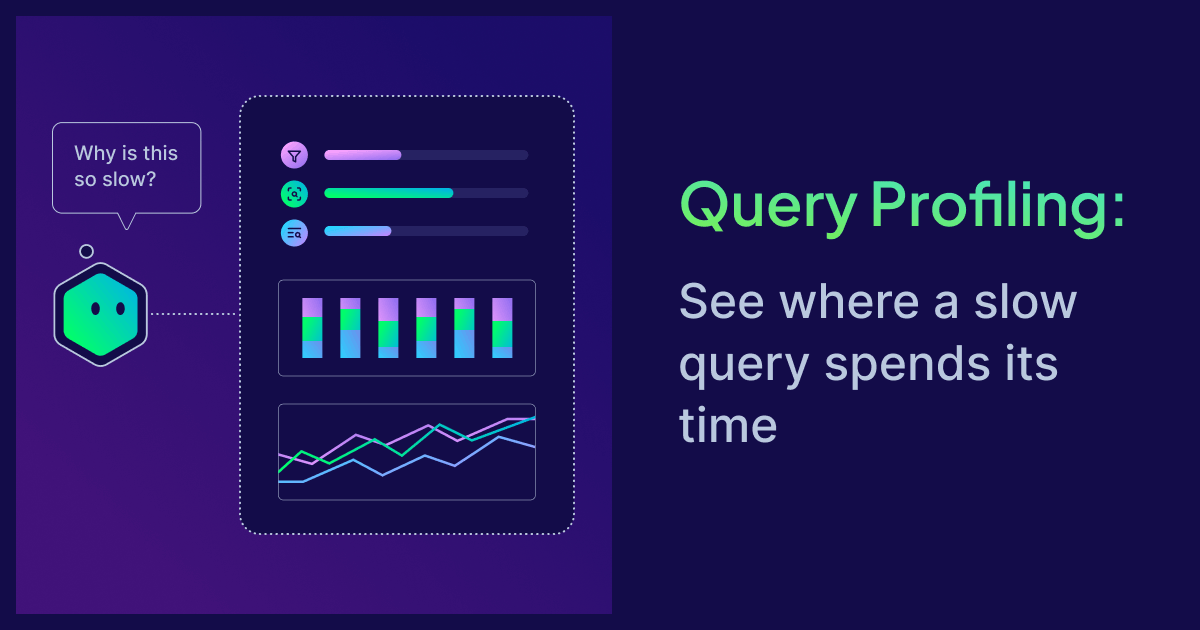
Query Profiling: See Where a Slow Query Spends Its Time
When a Weaviate query is slow, the first question is where the time went. Query profiling returns a per-stage, per-shard timing breakdown, making query performance issues visible.
· 9 min read