
The Art of Scaling a Vector Database like Weaviate
Scaling is not simply a process, but a principle that is as intrinsic to performance as growth is to life itself. Much like an orchestra preparing for its grand performance, how to scale a system reflects a deep understanding of its components, how they work in unison, and how they must evolve to keep pace with increasing demands.
The beauty of scaling a vector database lies not in adding power for power's sake but in understanding the various types of stress placed upon a system and responding accordingly. When we speak of scaling Weaviate, we genuinely talk about the ancient art of knowing when to divide to multiply, replicate to preserve, and strengthen the foundation rather than build higher. There are two paths to scaling: adding more memory, more CPUs, and expanding the capacity of a single node - vertical scaling or creating a distributed consciousness with horizontal scaling, where knowledge is shared across multiple nodes, each node holding a piece of the larger intelligence.
Choosing between the paths is never simply technical; it acknowledges our assumptions about how intelligence should be organized, how knowledge and data should be preserved, and how systems should respond to the inevitable failures that time brings.
Let's explore horizontal and vertical scaling of a vector database, like Weaviate and their use cases and decide which is appropriate.
Horizontal and Vertical Scaling: The art of distributed intelligence
In a vector database like Weaviate, there are two methods to scale: horizontal scaling and vertical scaling. Under horizontal scaling are two fundamental strategies; sharding, which distributes data across multiple nodes, and replication, which creates redundant copies for high availability (HA). Sharding and replication can work independently or in harmony, each addressing distinct aspects of the scaling challenge. Vertical scaling, or “scaling up,” increases resources like memory and CPU for better performance.
Sharding: The Art of Thoughtful Division
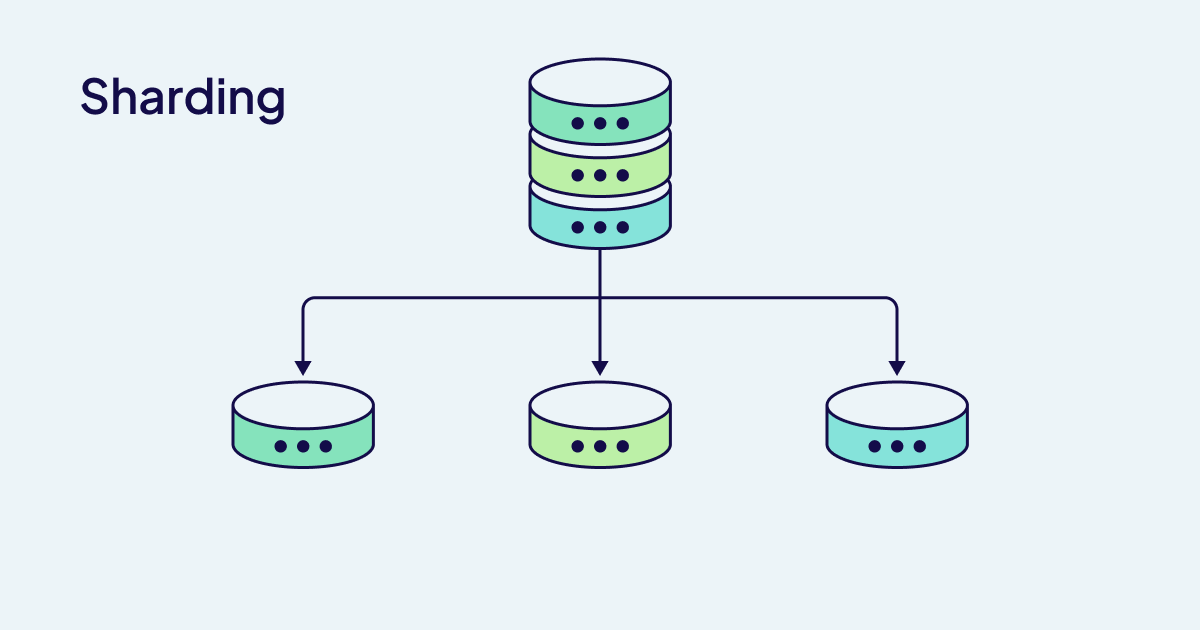
Sharding is a sophisticated system with a single collection index composed of multiple shards distributed across servers; Weaviate automatically handles the necessary orchestration at import and query time. A 64-bit Murmur-3 hash algorithm based on each object's UUID determines shard placement through a virtual shard system. The virtual system enables efficient resharding by minimizing data movement.
Due to the HNSW index structure, resharding is a costly process that should be used rarely.
Take, for example, a semantic search system that indexes millions of research papers or a recommendation engine that processes user behavior across global markets - sharding enables storage scalability and import parallelization in both of these massive knowledge bases. Creating multiple shards for your collection is recommended, as it can improve performance on even just a single node.
Replication: the art of resilient data
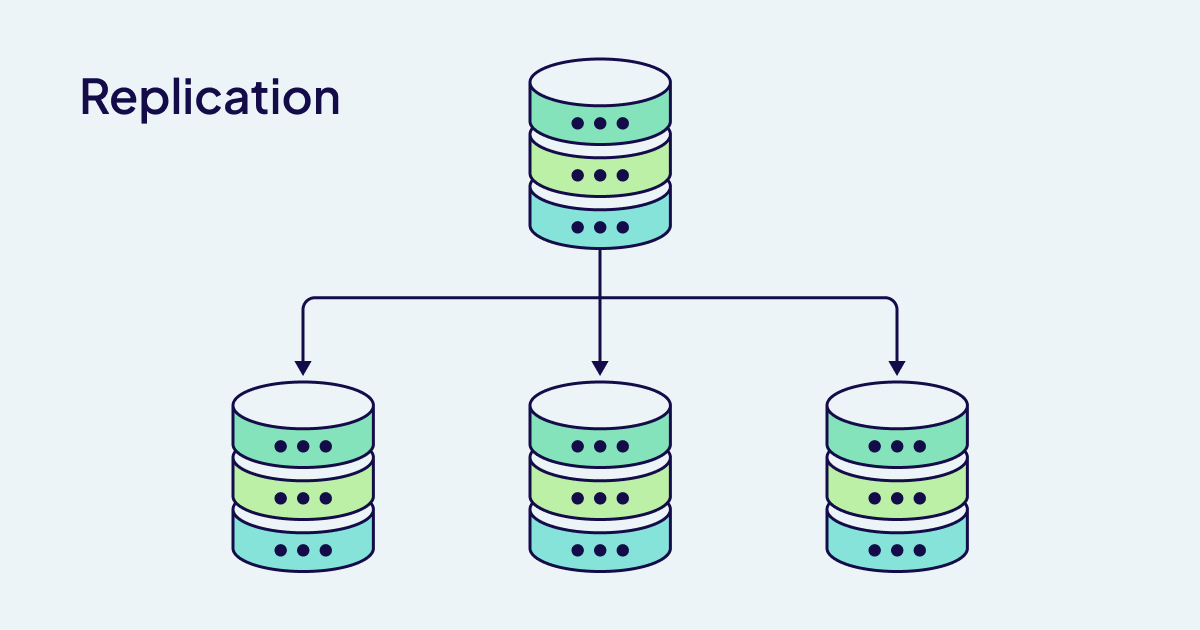
Where sharding divides to multiply, replication multiplies to preserve. Replication in Weaviate has multiple approaches: cluster metadata replication handled by the Raft consensus algorithm and tunable, leaderless data replication. A dual-layer approach ensures that the structural knowledge of the cluster and the actual vector data maintain appropriate levels of redundancy.
High Availability (HA) emerges from a distributed database structure; it ensures service continuity even when individual nodes fail. This resilience means the difference between graceful degradation and complete service interruption for applications like real-time customer support chatbots or financial risk assessment systems.
One of the most significant advantages of Weaviate's performance scaling for a production environment is that replication enables zero-downtime maintenance. Upgrades are performed using rolling updates, where one node is often unavailable while other nodes continue serving traffic.
Vertical scaling: the art of reinforcement
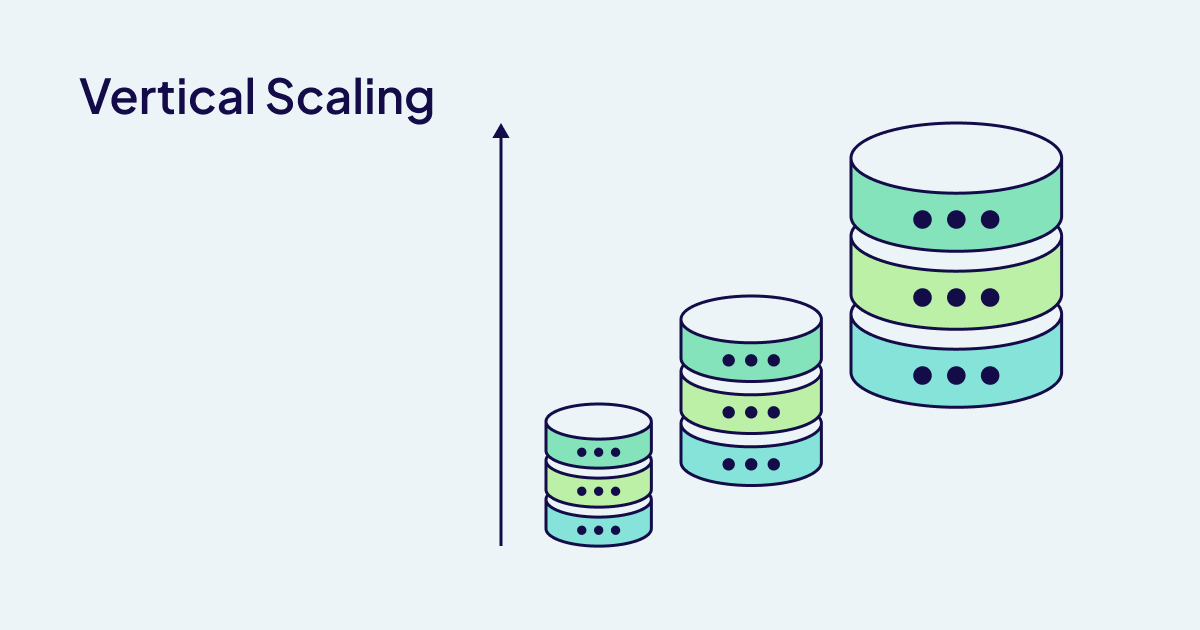
CPU and memory are the primary resources used for Weaviate clusters. CPU has a direct effect on query and import speed. Whole memory determines the maximum supported dataset size. For applications experiencing query latency issues under load, vertical scaling through increasing CPUs can often provide immediate relief. However, if memory is an issue and your system runs out of memory before reaching query throughput limits, horizontal scaling through sharding will be necessary to distribute the memory burden across multiple nodes.
As you can imagine, Weaviate provides sophisticated controls for resource management with environment variables like LIMIT_RESOURCES for automatic resource limitation, GOMEMLIMIT for Go runtime memory control, and GOMAXPROCS for setting the maximum number of threads being executed simultaneously.
The difference between vertical and horizontal scaling of vector databases
Vertical scaling represents concentrated strength - adding more CPU cores, expanding memory or upgrading storage options. It makes for a simplified architecture while also pushing the boundaries of what a single machine can achieve. If your searches require a faster response time, vertical scaling can provide the most direct solution.
By contrast, horizontal scaling embraces distribution as a strategy for capacity and resilience. Instead of making individual nodes larger, it creates clusters of nodes that coordinate to share the workload. This strategy has two techniques, sharding and replication.
The art of wisdom: knowing when and how to scale
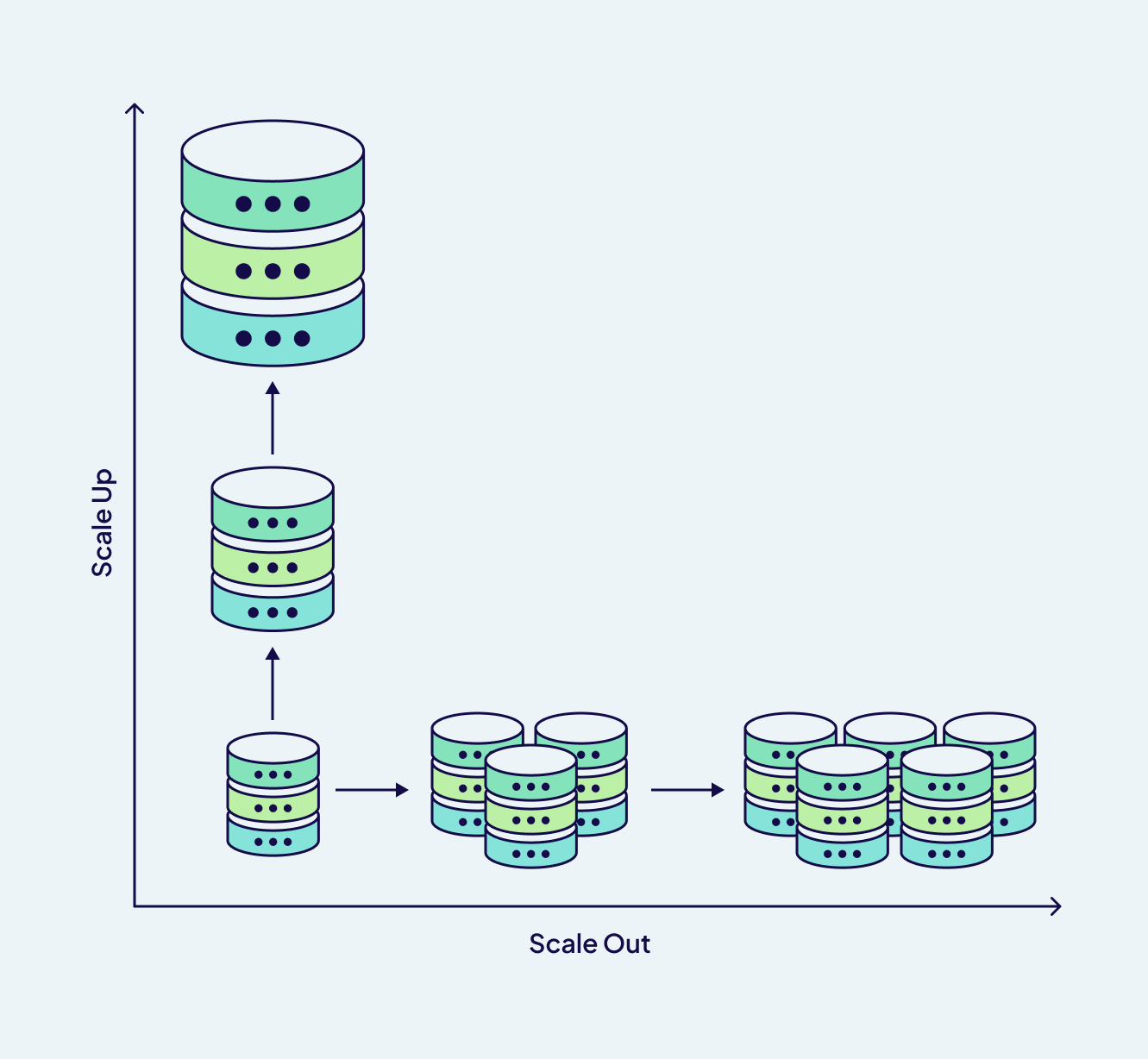
In a vector database, deciding between vertical and horizontal scaling, sharding, and replication solely depends on specific performance characteristics and requirements. Consider the following scenarios:
- The growing knowledge base: A system that needs to index increasingly large document repositories. Sharding will address any memory limitations in this scenario while enabling parallel imports. If the single-node memory capacity is exceeded, distribution across multiple shards is essential.
- The high-concurrency service: A content recommendation system that serves thousands of users simultaneously. Replication will effectively distribute query load as each replica will handle a portion of concurrent requests. Since the user query patterns are similar, replication will be more effective than sharding in this scenario.
- The mission-critical application: A system that cannot tolerate downtime during maintenance will benefit significantly from replication. It will provide both performance benefits and operational resilience.
Integrating sharding and replication is the most sophisticated approach as that architecture provides both the storage scalability of sharding and the availability benefits of replication. Modern AI applications are increasingly demanding this approach. The key to scaling lies in understanding that it is not a single decision but an ongoing architectural evolution that will respond to changing requirements and usage patterns.
Summary: Scaling for long-term success
The evolution of AI applications has created new categories of scaling challenges that traditional databases have not historically needed to address. The companies building sophisticated AI systems understand that the architecture of their deployment directly impacts the quality of insights that their AI can generate, the speed it can learn, and the reliability it can serve its users. What sets them apart is anticipating growth and complexity instead of reactive responses to capacity limits. The future of this landscape belongs to those who master the balance of technical sophistication combined with architectural restraint, scaling complexity without losing essential simplicity.
The accurate measure of successful scaling is not whether a system can be made bigger but whether it can be made wiser. Not whether a system can process more queries per second but whether each query delivers insights that matter. Pursuing this vision, whether to scale horizontally or vertically, whether to replicate or shard, is more than simply an engineering decision. It is an act of design that shapes how data can emerge, evolve, and endure in the systems created.
Additional resources
Ready to start building?
Check out the Quickstart tutorial, or build amazing apps with a free trial of Weaviate Cloud (WCD).
Don't want to miss another blog post?
Sign up for our bi-weekly newsletter to stay updated!
By submitting, I agree to the Terms of Service and Privacy Policy.