
Evaluation Metrics for Search and Recommendation Systems

How do you evaluate the quality of your search results in a Retrieval-Augmented Generation (RAG) pipeline or in a recommendation system? While many new metrics are currently emerging to evaluate the quality of retrieved contexts for RAG pipelines, there are already established metrics to objectively measure information retrieval systems.
This article gives a comprehensive overview of commonly used evaluation metrics in search and recommendation systems. As recommendation systems can be viewed as a special case of information retrieval or search systems, similar metrics apply to both.
To explain how each of the following metrics is calculated, this article uses a minimal example dataset of eight pastries - to stay in line with the bagel example our colleagues used in their recent discussion on how to choose and evaluate an embedding model - as shown below.
We will use the pytrec_eval Python package to showcase how you can evaluate your retrieval or recommendation pipelines in your code. Check out the code in the related GitHub repository.
pytrec_evalis a Python interface to TREC's evaluation tool, trec_eval. It is an attempt to stop the cultivation of custom implementations of Information Retrieval evaluation measures for the Python programming language.
To use the pytrec_eval package, you can simply pip install it.
pip install pytrec_eval
Metrics to Evaluate Information Retrieval Systems
This section covers the most popular offline metrics for evaluating information retrieval systems, such as search and recommendation systems. It explores precision@K, recall@K, MAP@K, MRR@K, and NDCG@K.
As you might have noticed, all of these metrics end with "@K" (pronounced: "at K"). This simply means we are only evaluating the top K results.
All of the following metrics can take values between 0 and 1, where higher values mean better performance.
Additionally, the following evaluation metrics can be categorized into not rank-aware vs. rank-aware metrics. While not rank-aware metrics, such as precision and recall, only reflect the number of relevant items in the top K results, rank-aware metrics, such as MAP, MRR, and NDCG, consider the number of relevant items and their position in the list of results.
Precision
The precision@K metric measures how many of the retrieved items are relevant. This metric is not rank-aware and thus only considers the number of relevant results but not their order. You can calculate precision@K by dividing the number of relevant items within the top K results by K.
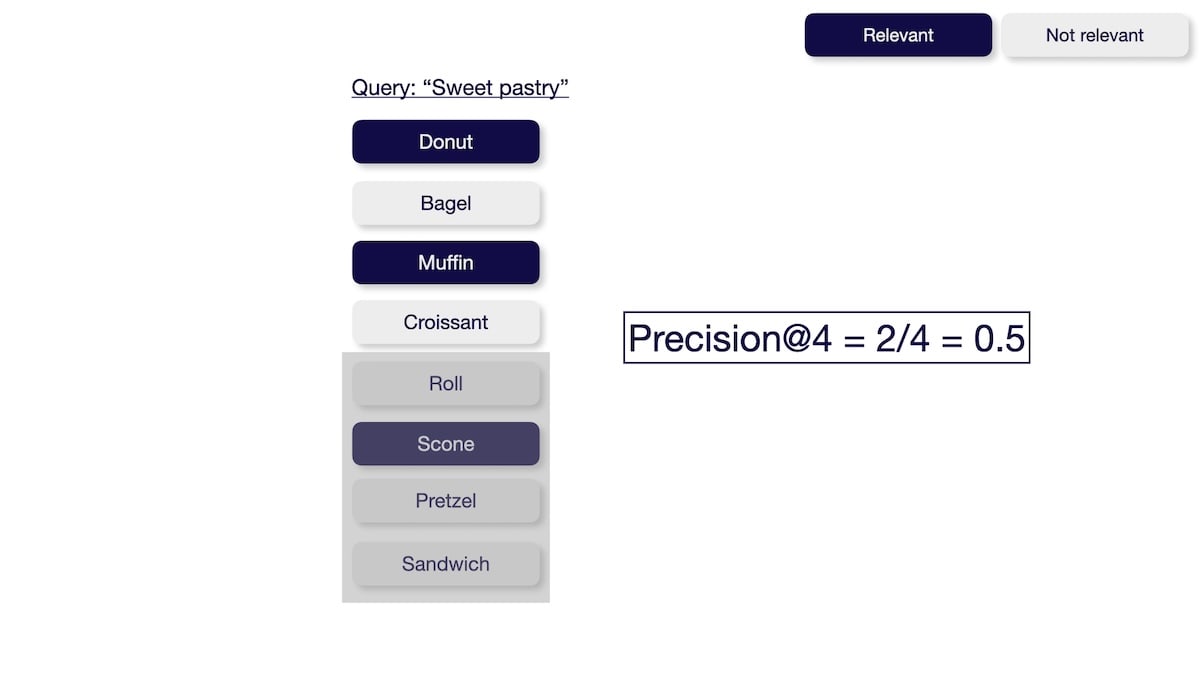
With pytrec_eval you can evaluate your search results as follows:
import pytrec_eval
qrel = {
'sweet pastry' : {
'donut' : 1,
'muffin' : 1,
'scone' : 1,
},
}
run = {
'sweet pastry' : {
'donut' : 0.95,
'bagel' : 0.9,
'muffin' : 0.8,
'croissant' : 0.7,
},
}
evaluator = pytrec_eval.RelevanceEvaluator(qrel, {'P.4'})
results = evaluator.evaluate(run)
{
"sweet pastry": {
"P_4": 0.5
}
}
Recall
The recall@K metric measures how many relevant items were successfully retrieved from the entire dataset. This metric is not rank-aware and thus only considers the number of relevant results but not their order. You can calculate the recall@K by dividing the number of relevant items within the top K results by the total number of relevant items in the entire dataset.
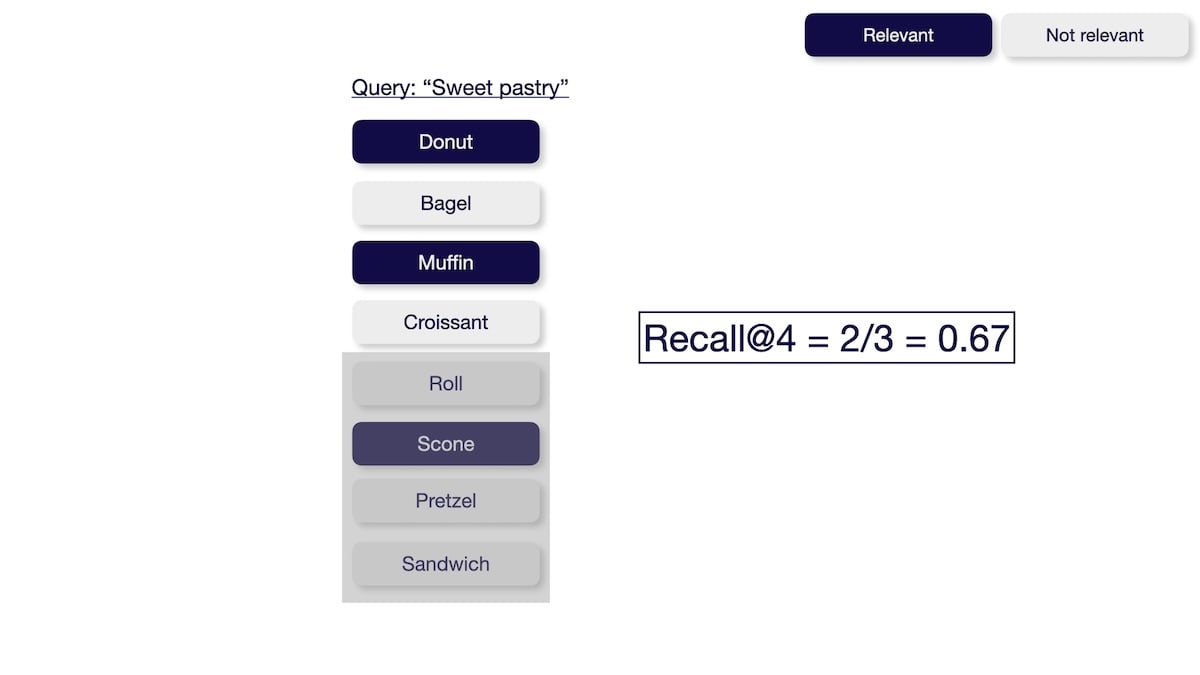
With pytrec_eval you can evaluate your search results as follows:
evaluator = pytrec_eval.RelevanceEvaluator(qrel, { 'recall.4' })
results = evaluator.evaluate(run)
{
"sweet pastry": {
"recall_4": 0.6666666666666666
}
}
Mean Reciprocal Rank (MRR)
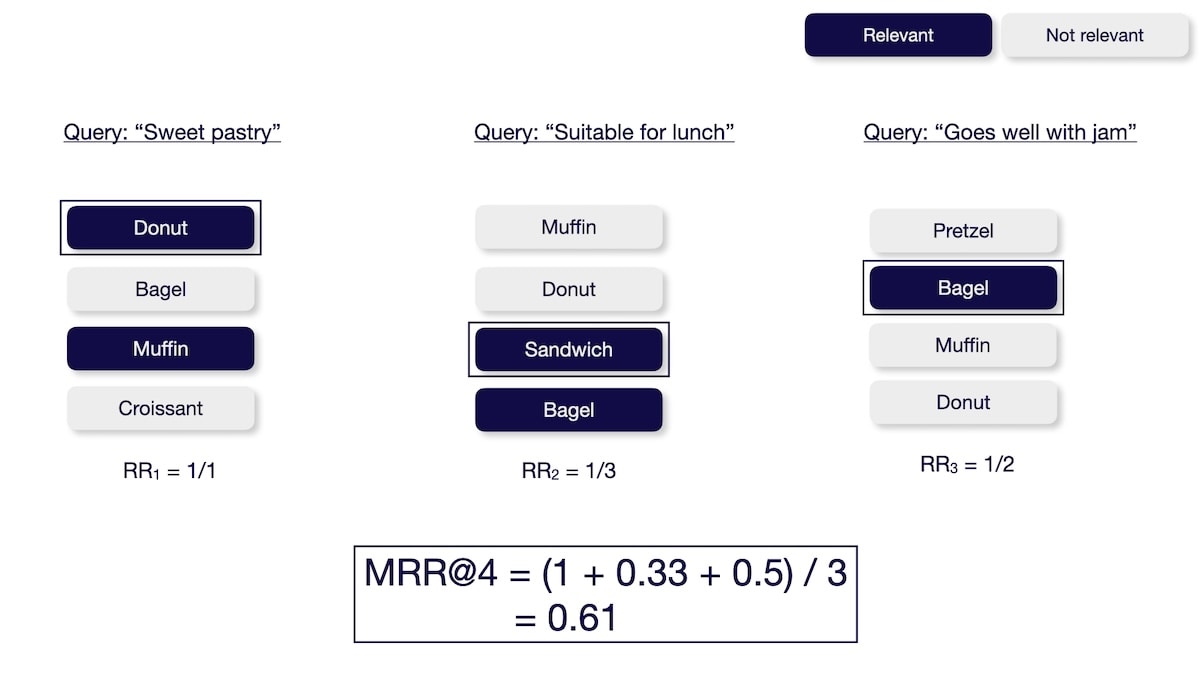
The Mean Reciprocal Rank@K (MRR@K) metric measures how well the system finds a relevant result as the top result. This metric only considers the order of the first relevant results but not the number or order of the other relevant results. You can calculate the MRR@K by averaging the Reciprocal Ranks (RR) across multiple queries (in case of information retrieval) or users (in case of recommendations) U in the evaluated dataset.
The Reciprocal Rank is calculated as follows:
Note that the MRR metric is not available in the pytrec_eval package as of this writing.
Mean Average Precision (MAP)
The Mean Average Precision@K (MAP@K) metric measures the system's ability to return relevant items in the top K results while placing more relevant items at the top. You can calculate the MAP@K metric by averaging the average precision at K across multiple queries (in case of information retrieval) or users (in case of recommendations) U in the evaluated dataset.
The average precision@K (AP@K) metric measures the precision values at all the relevant positions within K and averages them.

This is also the default metric used in the Massive Text Embedding Benchmark (MTEB) Leaderboard for the Reranking category.
With pytrec_eval you can evaluate your search results as follows.
qrel = {
'sweet pastry' : {
'donut' : 1,
'muffin' : 1,
},
}
run = {
'sweet pastry' : {
'donut' : 0.95,
'bagel' : 0.9,
'muffin' : 0.8,
'croissant' : 0.7,
},
}
evaluator = pytrec_eval.RelevanceEvaluator(qrel, { 'map_cut.4'})
results = evaluator.evaluate(run)
{
"sweet pastry": {
"map_cut_4": 0.8333333333333333
}
}
Note that the pytrec_eval package doesn't take average across multiple queries.
Normalized Discounted Cumulative Gain (NDCG)
The Normalized Discounted Cumulative Gain@K (NDCG@K) metric measures the system's ability to sort items based on relevance. In contrast to the above metrics, this metric requires not only if a document is relevant but also how relevant it is (e.g., relevant vs. somewhat relevant vs. not relevant).
You can calculate the NDCG@K by calculating the discounted cumulative gain (DCG) and then normalizing it over the ideal discounted cumulative gain (IDCG).
The DCG is calculated as follows:

This is the default metric used in the MTEB Leaderboard for the Retrieval category.
With pytrec_eval you can evaluate your search results as follows:
qrel = {
'goes well with jam' : {
'bagel' : 2,
'croissant' : 2,
'roll' : 2,
'scone' : 1,
'muffin' : 1,
'donut' : 1,
},
}
run = {
'goes well with jam' : {
'pretzel' : 0.9,
'bagel' : 0.85,
'muffin' : 0.7,
'donut' : 0.6,
},
}
evaluator = pytrec_eval.RelevanceEvaluator(qrel, { 'ndcg_cut.4', })
results = evaluator.evaluate(run)
{
"goes well with jam": {
"ndcg_cut_4": 0.4672390440360399
}
}
Summary
This article gave a brief overview of the most popular evaluation metrics used in search and recommendation systems: Precision@K, recall@K, MRR@K, MAP@K, and NDCG@K. We have also discussed that MAP@K is most popular for evaluating recommendation systems, while NDCG@K is highly popular for evaluating retrieval systems.
Additionally, you have learned how to calculate each of these metrics and how to implement their calculation in Python with the pytrec_eval library. You can review the implementation details by checking out the code in the related GitHub repository.
Ready to start building?
Check out the Quickstart tutorial, or build amazing apps with a free trial of Weaviate Cloud (WCD).
Don't want to miss another blog post?
Sign up for our bi-weekly newsletter to stay updated!
By submitting, I agree to the Terms of Service and Privacy Policy.