
What Is Agentic RAG? From LLM RAG to AI Agents
While Retrieval-Augmented Generation (RAG), often referred to as LLM RAG, dominated 2023, agentic workflows are driving massive progress in 2024. The usage of AI agents opens up new possibilities for building more powerful, robust, and versatile Large Language Model(LLM)-powered applications. One possibility is enhancing LLM RAG pipelines with AI agents in agentic RAG pipelines. Agentic RAG is a way to make the RAG pipeline more reliable by adding planning, tool use, and validation loops.
This article introduces you to the concept of agentic RAG, its implementation, and its benefits and limitations.
Fundamentals of Agentic RAG
Agentic RAG describes an AI agent-based implementation of RAG. Before we go any further, let’s quickly recap the fundamental concepts of RAG and AI agents.
What is Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) is a technique for building LLM-powered applications. It leverages an external knowledge source to provide the LLM with relevant context and reduce hallucinations.
Many teams also call this LLM RAG or retrieval augmented generation for LLMs, since retrieval supplies the model with external context at inference time.
A naive LLM RAG pipeline consists of a retrieval component (typically composed of an embedding model and a vector database) and a generative component (an LLM). At inference time, the user query is used to run a similarity search over the indexed documents to retrieve the most similar documents to the query and provide the LLM with additional context.
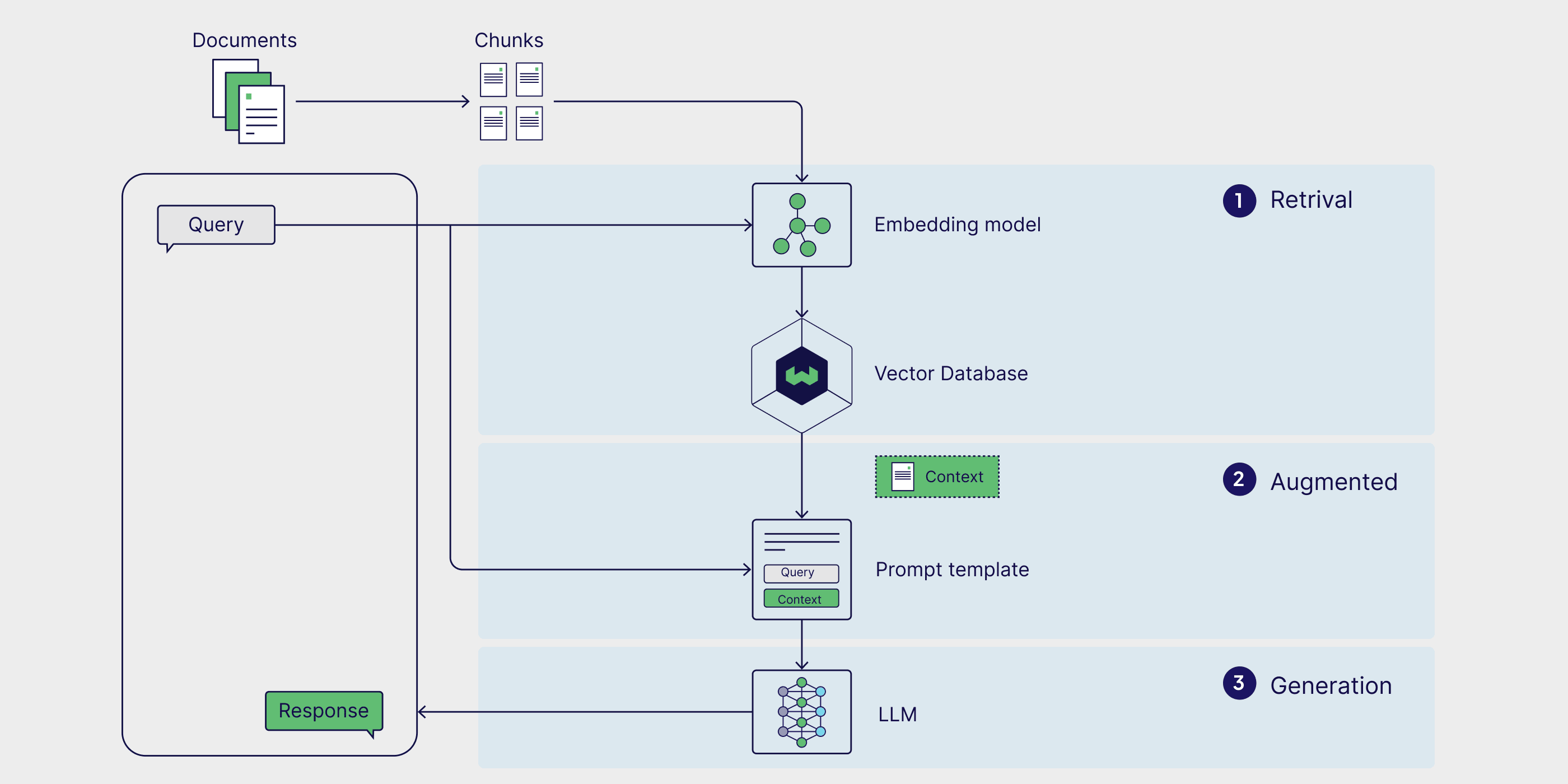
Typical RAG applications have two considerable limitations:
- The naive RAG pipeline only considers one external knowledge source. However, some solutions might require two external knowledge sources, and some solutions might require external tools and APIs, such as web searches.
- They are a one-shot solution, which means that context is retrieved once. There is no reasoning or validation over the quality of the retrieved context.
What are Agents in AI Systems
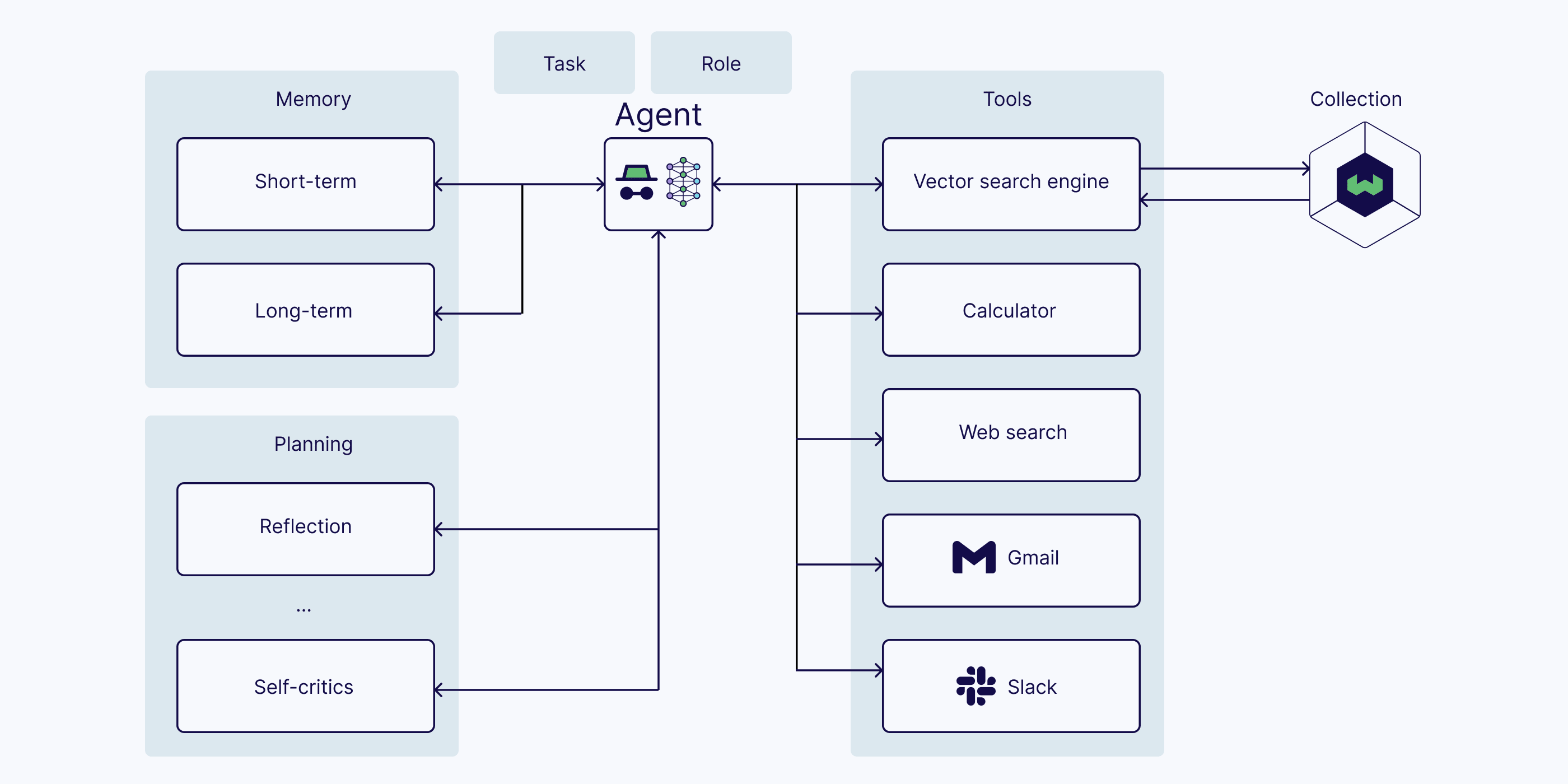
With the popularity of LLMs, new paradigms of AI agents and multi-agent systems have emerged. AI agents are LLM-based systems with a role and task that use tools and agent memory (short-term and long-term) to plan, act, and adapt. The reasoning capabilities of LLMs help the agent plan the required steps and take action to complete the task at hand.
Thus, the core components of an AI agent are:
- LLM (with a role and a task)
- Memory (short-term and long-term)
- Planning (e.g., reflection, self-critics, query routing, etc.)
- Tools (e.g., calculator, web search, etc.)
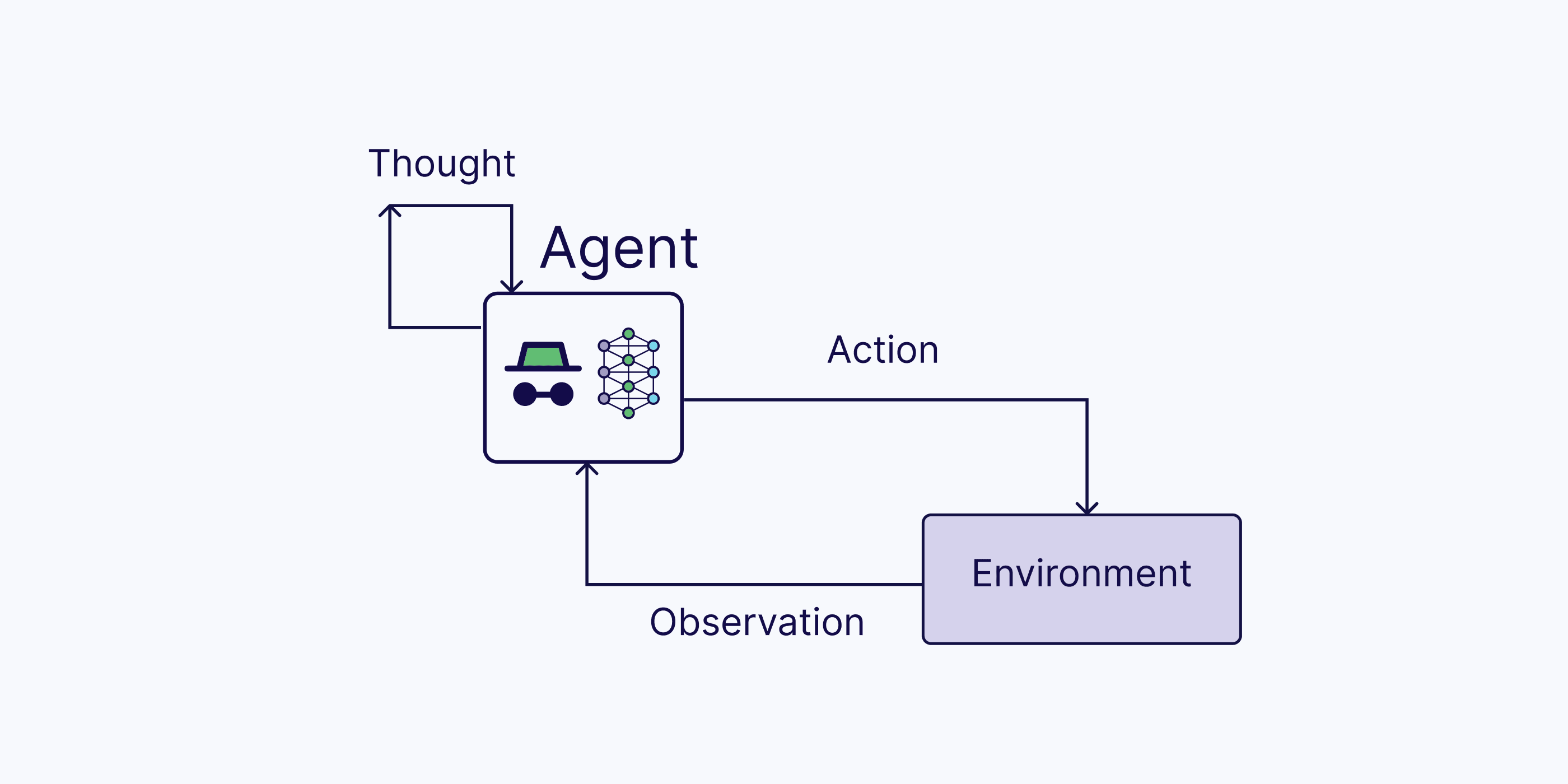
One popular framework is the ReAct framework. A ReAct agent can handle sequential multi-part queries while maintaining state (in memory) by combining routing, query planning, and tool use into a single entity.
ReAct = Reason + Act (with LLMs)
The process involves the following steps:
-
Thought: Upon receiving the user query, the agent reasons about the next action to take
-
Action: the agent decides on an action and executes it (e.g., tool use)
-
Observation: the agent observes the feedback from the action
-
This process iterates until the agent completes the task and responds to the user.
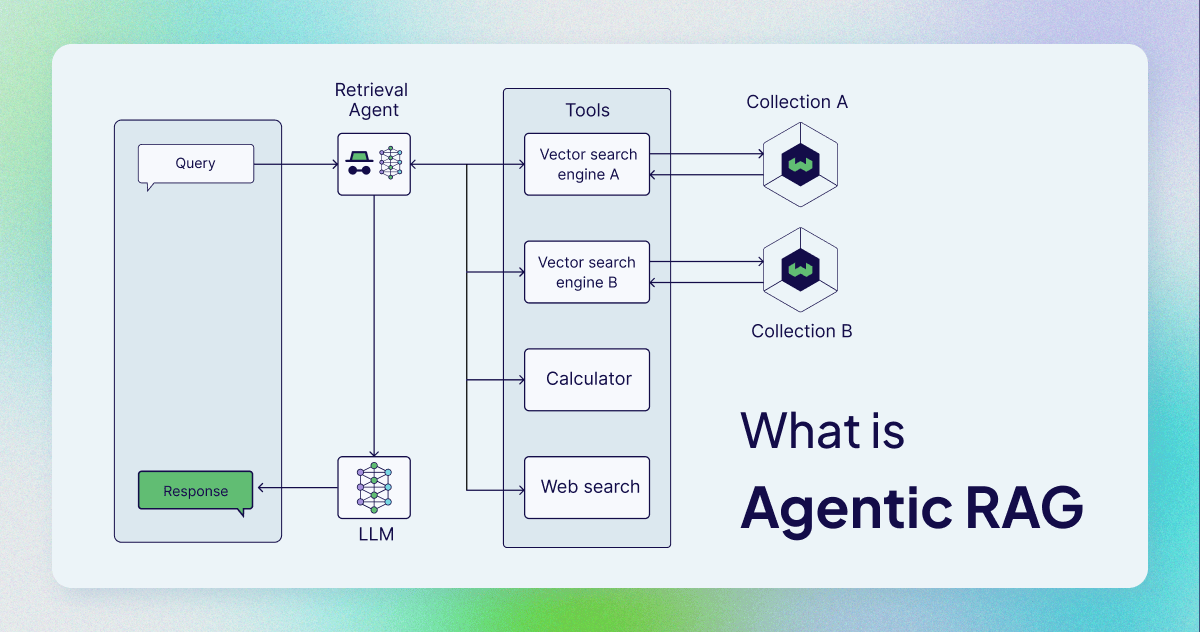
What is Agentic RAG?
Agentic RAG describes an AI agent-based implementation of RAG. Specifically, it incorporates AI agents into the RAG pipeline to orchestrate its components and perform additional actions beyond simple information retrieval and generation to overcome the limitations of the non-agentic pipeline.
In other words, agentic RAG turns retrieval into an iterative process: the agent can retrieve, evaluate, re-retrieve, and validate context before generating the final answer.
This makes agentic RAG more robust than one-shot retrieval in production systems.
Agentic RAG describes an AI agent-based implementation of RAG.
How does Agentic RAG work?
Although agents can be incorporated in different stages of the LLM RAG pipeline, agentic RAG most commonly refers to the use of agents in the retrieval component.
Specifically, the retrieval component becomes agentic through the use of retrieval agents with access to different retriever tools, such as:
- Vector search engine (also called a query engine) that performs vector search over a vector index (like in typical RAG pipelines)
- Web search
- Calculator
- Any API to access software programmatically, such as email or chat programs
- and many more.
In many systems, retrieved results also act as a form of long-term memory, allowing agents to recall relevant information across steps.
The RAG agent can then reason and act over the following example retrieval scenarios:
- Decide whether to retrieve information or not
- Decide which tool to use to retrieve relevant information
- Formulate the query itself
- Evaluate the retrieved context and decide whether it needs to re-retrieve.
Agentic RAG Architecture
In contrast to the sequential naive RAG architecture, the core of the agentic RAG architecture is the agent. Agentic RAG architectures can have various levels of complexity. In the simplest form, a single-agent RAG architecture is a simple router. However, you can also add multiple agents into a multi-agent RAG architecture. This section discusses the two fundamental RAG architectures.
Single-Agent RAG (Router)
In its simplest form, agentic RAG is a router. This means you have at least two external knowledge sources, and the agent decides which one to retrieve additional context from. However, the external knowledge sources don't have to be limited to (vector) databases. You can retrieve further information from tools as well. For example, you can conduct a web search, or you could use an API to retrieve additional information from Slack channels or your email accounts.
-ae2ec18616941504070d6b2a7210a358.png)
Multi-agent RAG Systems
As you can guess, the single-agent system also has its limitations because it's limited to only one agent with reasoning, retrieval, and answer generation in one. Therefore, it is beneficial to chain multiple agents into a multi-agent RAG application.
For example, you can have one master agent who coordinates information retrieval among multiple specialized retrieval agents. For instance, one agent could retrieve information from proprietary internal data sources. Another agent could specialize in retrieving information from your personal accounts, such as email or chat. Another agent could also specialize in retrieving public information from web searches.
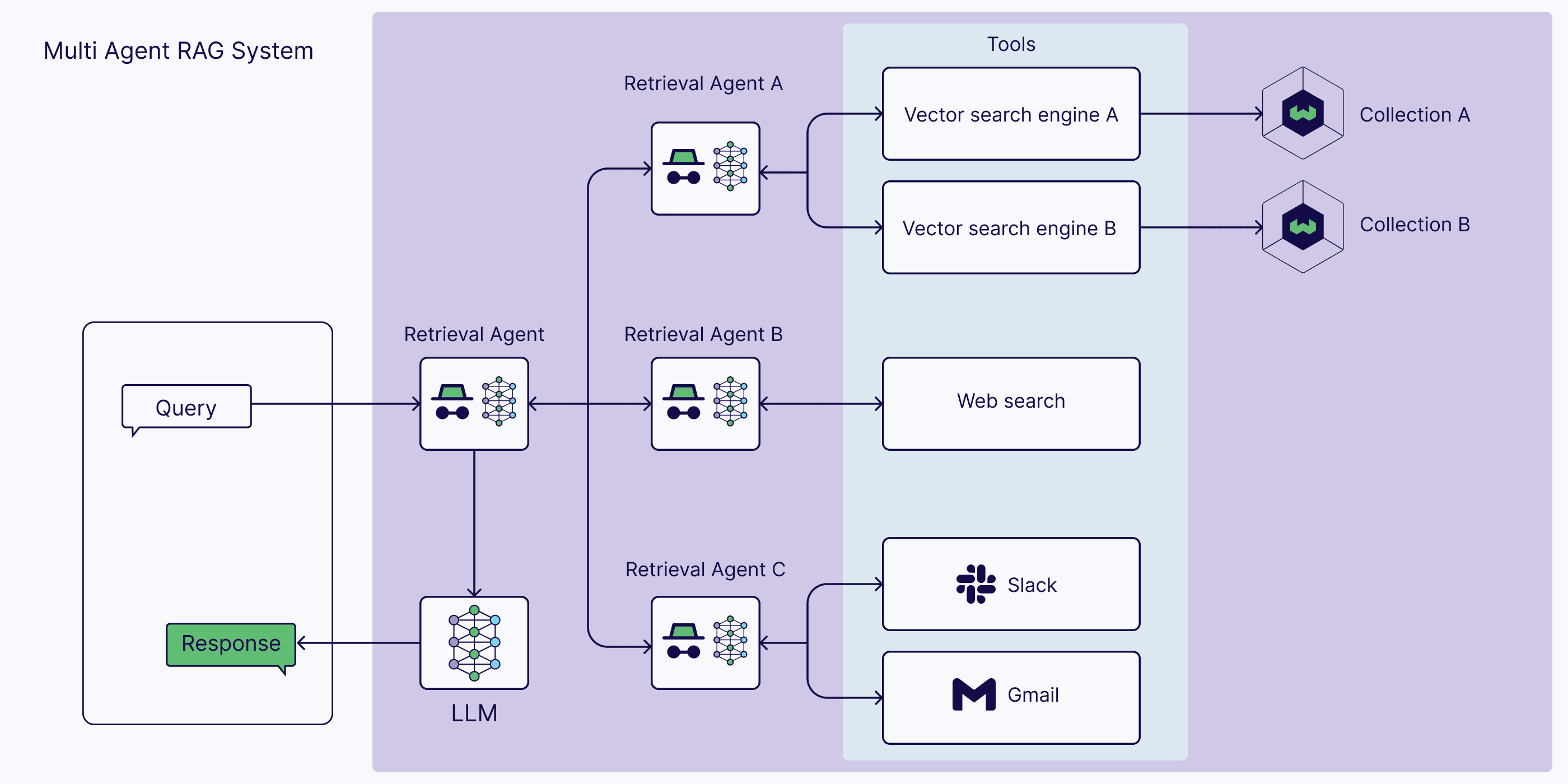
Beyond Retrieval Agents
The above example shows the usage of different retrieval agents. However, you could also use agents for purposes other than retrieval. The possibilities of agents in the RAG system are manifold.
Agentic RAG vs. (Vanilla) RAG
While the fundamental concept of RAG (sending a query, retrieving information, and generating a response) remains the same, tool use generalizes it, making it more flexible and powerful.
Think of it this way: Common (vanilla) RAG is like being at the library (before smartphones existed) to answer a specific question. Agentic RAG, on the other hand, is like having a smartphone in your hand with a web browser, a calculator, your emails, etc.
| Vanilla LLM RAG | Agentic RAG | |
|---|---|---|
| Access to external tools | No | Yes |
| Query pre-processing | No | Yes |
| Multi-step retrieval | No | Yes |
| Validation of retrieved information | No | Yes |
Here, we use “RAG” and “LLM RAG” interchangeably—both refer to retrieval augmented generation for large language models.
Implementing Agentic RAG
As outlined earlier, agents are comprised of multiple components. To build an agentic RAG pipeline, there are two options: a language model with function calling or an agent framework. Both implementations get to the same result, it will just depend on the control and flexibility you want.
Language Models with Function Calling
Language models are the main component of agentic RAG systems. The other component is tools, which enable the language model access to external services. Language models with function calling offer a way to build an agentic system by allowing the model to interact with predefined tools. Language model providers have added this feature to their clients.
In June 2023, OpenAI released function calling for gpt-3.5-turbo and gpt-4. It enabled these models to reliably connect GPT’s capabilities with external tools and APIs. Developers quickly started building applications that plugged gpt-4 into code executors, databases, calculators, and more.
Cohere further launched their connectors API to add tools to the Command-R suite of models. Additionally, Anthropic and Google launched function calling for Claude and Gemini. By powering these models with external services, it can access and cite web resources, execute code and more.
Function calling isn’t only for proprietary models. Ollama introduced tool support for popular open-source models like Llama3.2, nemotron-mini, and others.
To build a tool, you first need to define the function. In this snippet, we’re writing a function that is using Weaviate’s hybrid search to retrieve objects from the database:
def get_search_results(query: str) -> str:
"""Sends a query to Weaviate's Hybrid Search. Parses the response into a {k}:{v} string."""
response = blogs.query.hybrid(query, limit=5)
stringified_response = ""
for idx, o in enumerate(response.objects):
stringified_response += f"Search Result: {idx+1}:\n"
for prop in o.properties:
stringified_response += f"{prop}:{o.properties[prop]}"
stringified_response += "\n"
return stringified_response
We will then pass the function to the language model via a tools_schema. The schema is then used in the prompt to the language model:
tools_schema=[{
'type': 'function',
'function': {
'name': 'get_search_results',
'description': 'Get search results for a provided query.',
'parameters': {
'type': 'object',
'properties': {
'query': {
'type': 'string',
'description': 'The search query.',
},
},
'required': ['query'],
},
},
}]
Since you’re connecting to the language model API directly, you’ll need to write a loop that routes between the language model and tools:
def ollama_generation_with_tools(user_message: str,
tools_schema: List, tool_mapping: Dict,
model_name: str = "llama3.1") -> str:
messages=[{
"role": "user",
"content": user_message
}]
response = ollama.chat(
model=model_name,
messages=messages,
tools=tools_schema
)
if not response["message"].get("tool_calls"):
return response["message"]["content"]
else:
for tool in response["message"]["tool_calls"]:
function_to_call = tool_mapping[tool["function"]["name"]]
print(f"Calling function {function_to_call}...")
function_response = function_to_call(tool["function"]["arguments"]["query"])
messages.append({
"role": "tool",
"content": function_response,
})
final_response = ollama.chat(model=model_name, messages=messages)
return final_response["message"]["content"]
Your query will then look like this:
ollama_generation_with_tools("How is HNSW different from DiskANN?",
tools_schema=tools_schema, tool_mapping=tool_mapping)
You can follow along this recipe to recreate the above.
Agent Frameworks
Agent Frameworks such as DSPy, LangChain, CrewAI, LlamaIndex, and Letta have emerged to facilitate building applications with language models. These frameworks simplify building agentic RAG systems by plugging pre-built templates together.
- DSPy supports ReAct agents and Avatar optimization. Avatar optimization describes the use of automated prompt engineering for the descriptions of each tool.
- LangChain provides many services for working with tools. LangChain’s LCEL and LangGraph frameworks further offer built-in tools.
- LlamaIndex further introduces the QueryEngineTool, a collection of templates for retrieval tools.
- CrewAI is one of the leading frameworks for developing multi-agent systems. One of the key concepts utilized for tool use is sharing tools amongst agents.
- Swarm is a framework built by OpenAI for multi-agent orchestration. Swarm similarly focuses on how tools are shared amongst agents.
- Letta interfaces reflecting and refining an internal world model as functions. This entails potentially using search results to update the agent’s memory of the chatbot user, in addition to responding to the question.
Why are Enterprises Adopting Agentic RAG
Enterprises are moving on from vanilla RAG to building agentic RAG applications. Replit released an agent that helps developers build and debug software. Additionally, Microsoft announced copilots that work alongside users to provide suggestions in completing tasks. These are only a few examples of agents in production and the possibilities are endless.
Benefits of Agentic RAG
The shift from vanilla RAG to agentic RAG allows these systems to produce more accurate responses, perform tasks autonomously, and better collaborate with humans.
The benefit of agentic RAG lies primarily in the improved quality of retrieved additional information. By adding agents with access to tool use, the retrieval agent can route queries to specialized knowledge sources. Furthermore, the reasoning capabilities of the agent enable a layer of validation of the retrieved context before it is used for further processing. As a result, agentic RAG pipelines can lead to more robust and accurate responses.
Limitations of Agentic RAG
However, there are always two sides to every coin. Using an AI agent a for subtask means incorporating an LLM to do a task. This comes with the limitations of using LLMs in any application, such as added latency and unreliability. Depending on the reasoning capabilities of the LLM, an agent may fail to complete a task sufficiently (or even at all). It is important to incorporate proper failure modes to help an AI agent get unstuck when they are unable to complete a task.
Summary
This blog discussed the concept of agentic RAG, which involves incorporating agents into the RAG pipeline. Although agents can be used for many different purposes in a RAG pipeline, agentic RAG most often involves using retrieval agents with access to tools to generalize retrieval. Agentic RAG is increasingly used to make LLM RAG pipelines more reliable by adding tool use, multi-step retrieval, and validation.
This article discussed agentic RAG architectures using single-agent and multi-agent systems and their differences from vanilla RAG pipelines.
With the rise and popularity of AI agent systems, many different frameworks are evolving for implementing agentic RAG, such as LlamaIndex, LangGraph, or CrewAI.
Finally, this article discussed the benefits and limitations of agentic RAG pipelines.
Further Resources
- Notebook using Swarm
- Notebook using Letta and Weaviate
- Notebooks on using function calling in Ollama
- Notebook on Vanilla RAG versus Agentic RAG
Ready to start building?
Check out the Quickstart tutorial, or sign up for a free Weaviate Cloud account.
Don't want to miss another blog post?
Sign up for our bi-weekly newsletter to stay updated!
By submitting, I agree to the Terms of Service and Privacy Policy.