
Vamana vs. HNSW - Exploring ANN algorithms Part 1

Vector databases must be able to search through a vast number of vectors at speed. This is a huge technical challenge that is only becoming more difficult over time as the vector dimensions and dataset sizes increase.
Like many others, our current prevailing solution is to use Approximate Nearest Neighbor (ANN) algorithms to power Weaviate. But the key question is - which ones to use? There are many different ANN algorithms, each with different advantages and limitations.
Large Scale
When we talk about a vast number of objects, today we often see use cases with hundreds of millions of vectors, but it won't take long until billions, or even trillions, will be a pretty standard use case.
To get vector databases to that kind of scale, we need to constantly evolve and look for more efficient solutions. A big part of this search is to explore ANN algorithms that would let us go beyond the available RAM (which is a bit of a bottleneck) without sacrificing the performance and the UX.
What to expect
In this series of blog posts, we will take you on a journey with us as we research and implement new ANN algorithms in our quest to reach the 1T goal.
In this article, we will cover the need for disk-based solutions, explore Vamana (how it works and contrast it against HNSW), and present the result of Vamana implementation.
If you are new to vector databases and ANN, I recommend you to read "Why is Vector Search so Fast?"
The article explains what vector databases are and how they work.
Need for approximation
In order for a vector database to efficiently search through a vast number of vectors, the database needs to be smart about it. A brute-force approach would calculate the distance between the query vector and every data vector in the queried collection, but this is computationally very expensive. For a database with millions of objects and thousands of high-dimensional vectors, this would take far too long.
Weaviate, an open-source vector database written in Go, can serve thousands of queries per second. Running Weaviate on Sift1M (a 128-dimensional representation of objects) lets you serve queries in single-digit milliseconds. But how is this possible?
 See the benchmark page for more stats.
See the benchmark page for more stats.
Weaviate does not look for the exact closest vectors in the store. Instead, it looks for approximate (close enough) elements. This means you could have a much faster reply, but there is no guarantee that you will actually have the closest element from your search. In the vector search space, we use recall to measure the rate of the expected matches returned. The trade-off between recall and latency can be tuned by adjusting indexing parameters. Weaviate comes with reasonable defaults, but also it allows you to adjust build and query-time parameters to find the right balance.
Weaviate incrementally builds up an index (graph representation of the vectors and their closest neighbors) with each incoming object. Then when a query arrives, Weaviate traverses the index to obtain a good approximated answer to the query in a fraction of the time that a brute-force approach would take.
HNSW is the first production-ready indexing algorithm we implemented in Weaviate. It is a robust and fast algorithm that builds a hierarchical representation of the index in memory that could be quickly traversed to find the k nearest neighbors of a query vector.
Need for disk solutions
There are other challenges to overcome. Databases have grown so fast that even the above-described algorithms will not be enough. We no longer talk about thousands of vectors but hundred of millions or even billions! Keeping all the vectors in memory and adding a graph representation of vector connections requires a lot of RAM. This sparked the emergence of a new set of algorithms that allow vectors to reside on disk instead of in memory whilst retaining high performance.
Some prominent examples of disk-based solutions include DiskANN and SPANN.
The future of Weaviate
Today, users use Weaviate in production to serve large-scale use cases with single-digit millisecond latencies and massive throughput. But not every use case requires such a high throughput that the cost of keeping all indexes in memory is justified. What if you have a case where you have a large-scale dataset but very few queries? What if cost-effectiveness is more of a priority than the lowest possible latencies?
We believe there is a need for other index types besides the battle-tested HNSW implementation. But cost-effectiveness can never justify sacrificing the user experience. As a result, we are working on establishing a new type of vector index that combines the low operating cost of SSD-based solutions with the ease of use of existing in-memory solutions.
At Weaviate, we pride ourselves on our research acumen and on providing state-of-the-art solutions. So we took time to explore these solutions to identify and evaluate the right building blocks for Weaviate's future. Here we share some of our findings from this research.
On the HNSW vs. Vamana comparison
As the first step to disk-based vector indexing, we decided to explore Vamana – the algorithm behind the DiskANN solution. Here are some key differences between Vamana and HNSW:
Vamana indexing - in short:
- Build a random graph.
- Optimize the graph, so it only connects vectors close to each other.
- Modify the graph by removing some short connections and adding some long-range edges to speed up the traversal of the graph.
HNSW indexing - in short:
- Build a hierarchy of layers to speed up the traversal of the nearest neighbor graph.
- In this graph, the top layers contain only long-range edges.
- The deeper the search traverses through the hierarchy, the shorter the distance between vectors captured in the edges.
Put simply, Vamana can build a flat graph, in contrast to HNSW, which uses a hierarchical representation. And a flat graph may suffer less performance degradation from being stored on disk than a hierarchical representation might. The reason is that since the outgoing connections from each node are known, it is possible to store the information in such a way that we can calculate the exact position on the file to read when retrieving information on the neighbors of a given node. This makes the information retrieval process very efficient, and thus the lower speed imposed by disk storage becomes less of a problem.
The main advantage of the hierarchical representation used in HNSW is that the traversal of the graph is accelerated. This is solved in the Vamana implementation by hosting long-range connections with a similar function.
Traversing a graph
Traversing a graph is a bit like planning international travel. First, we could take a long-distance flight (akin to a fast jump), taking us to a city closer to our destination. Then we could take a train (a lot better for the environment 😉) to get to the town of our choice. Finally, we can jump on a bike to reach our local destination.
For a better understanding, consider the below graphic, which shows a graph with all the connections generated using 1000 objects in two dimensions.
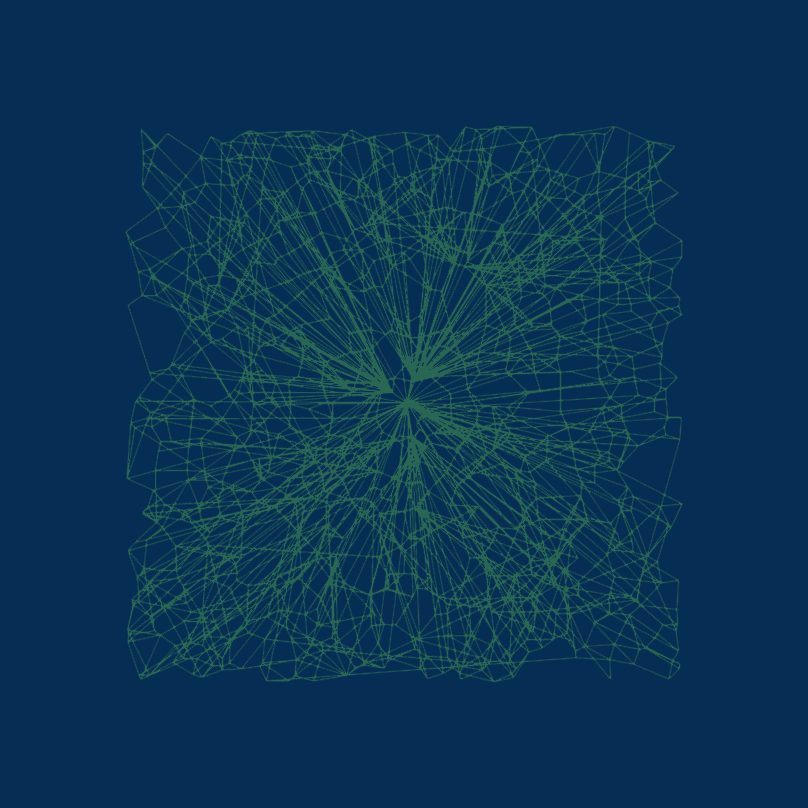
If we iterate over it in steps – we can analyze how Vamana navigates through the graph.

In the first step, you can see that the entry point for the search is in the center, and then the long-range connections allow jumping to the edges. This means that when a query comes, it will quickly move in the appropriate direction.
The second, third, and final steps highlight the nodes reachable within three, six, and nine hops from the entry node.
HNSW, on the other hand, implements the same idea a bit differently. Instead of having all information together on a flat graph, it has a hierarchical representation distributed across multiple layers. The top layers only contain long-range connections, and as you dive deeper into the layers, your query is routed to the appropriate region where you can look more locally for your answer. So your search starts making only big jumps across the top layers until it finally looks for the closest points locally in the bottom layers.
Performance comparison
So, how do they perform? Let's take a look in terms of speed as well as recall.
The chart below illustrates a comparison of the C++ Vamana reference code provided by Microsoft and our HNSW implementation when using Sift1M. Following Microsoft’s experiments, we have used sift-query.fvecs (100,000 vectors sample) for building the index and sift-query.fvecs (1,000 vectors sample) for querying. We are retrieving 10 (fig. 1) and 100 (fig. 2) objects per query. The chart shows the recall vs. latency on the same Google Cloud setup Microsoft used. In both cases, you might notice that both Vamana and HNSW implementations are performing similarly.
Keep in mind that – while Vamana is the algorithm that powers DiskANN – at this stage, we are comparing both solutions in memory.
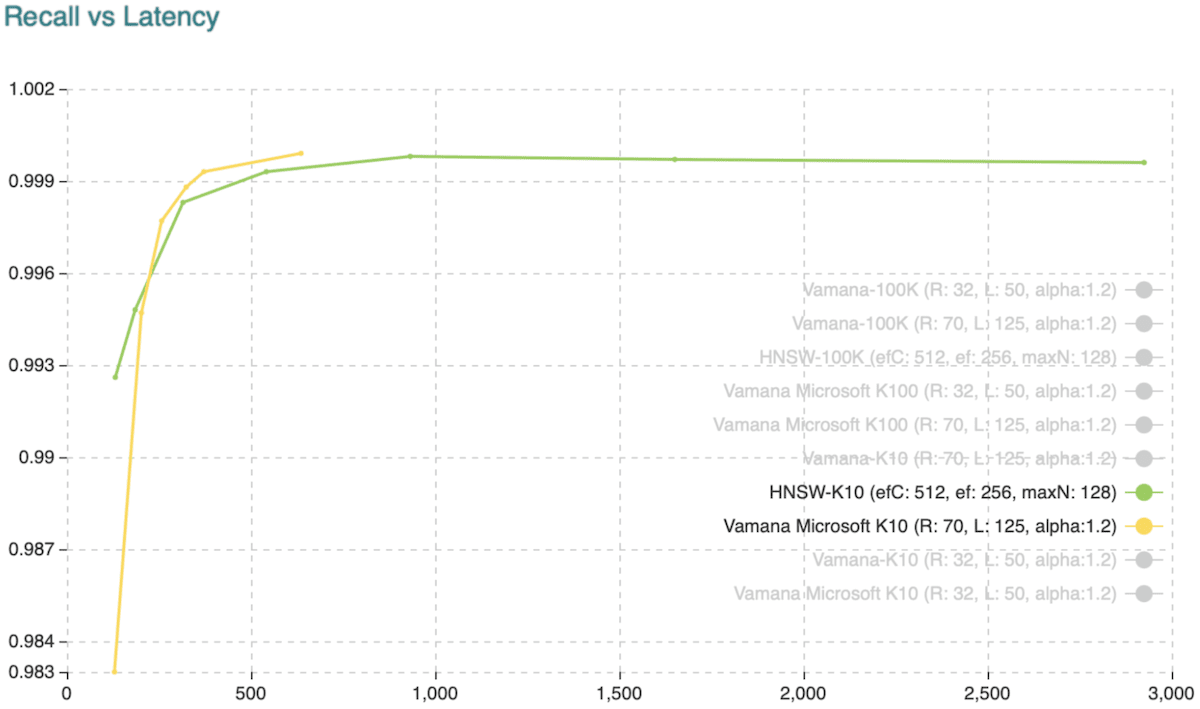 Fig. 1: Recall vs. Latency when retrieving the ten approximate nearest neighbors.
Fig. 1: Recall vs. Latency when retrieving the ten approximate nearest neighbors.
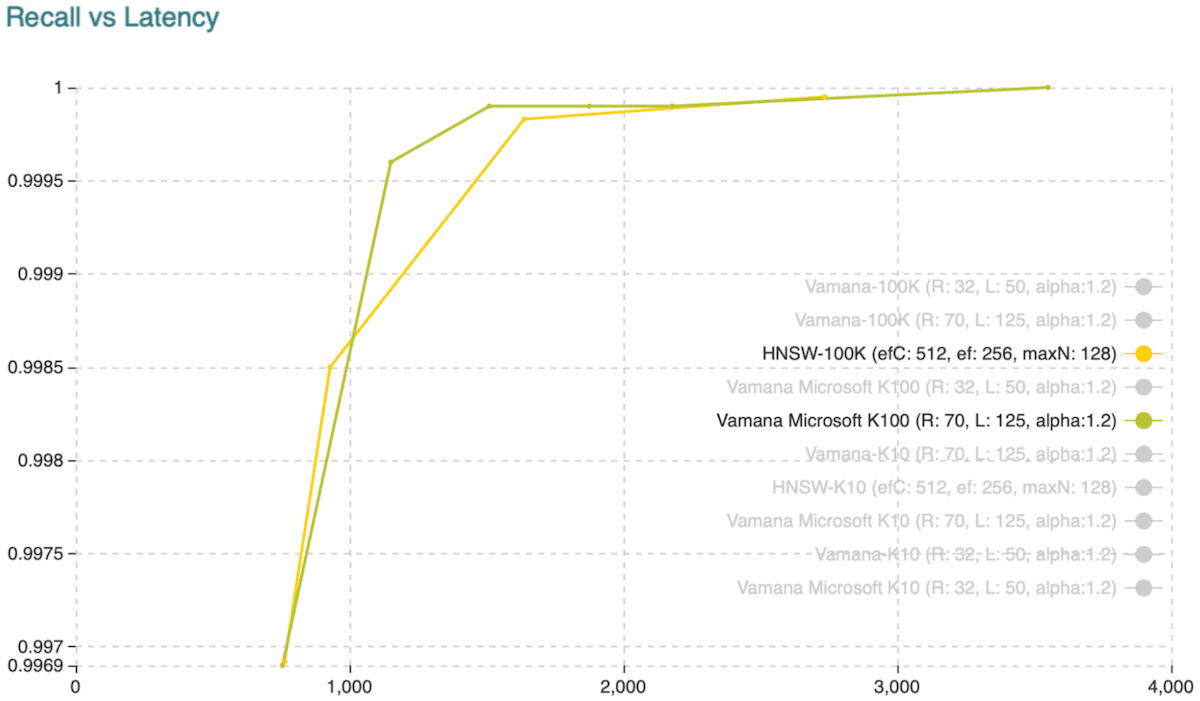 Fig. 2: Recall vs. Latency when retrieving the hundred approximate nearest neighbors.
Fig. 2: Recall vs. Latency when retrieving the hundred approximate nearest neighbors.
Vamana implementation details
We have also included a development implementation of the Vamana indexing algorithm in Weaviate. For the algorithm to perform well, such an implementation needs careful attention to the optimization of the code. The original algorithm from Microsoft rests upon the greedy search and the robust prune methods, which are described in the DiskANN paper as follows:

In plain English
These pseudo-code snippets are notoriously difficult to read, so here's a plain-English explanation of how Vamana works.
The greedy search algorithm is used to find the solution for a query. The main idea is to start looking for the best points iteratively from the entry point. The algorithm keeps a result set of points, starting with the entry point.
On every iteration, it checks what points are in the result set that has not been visited yet and, from them, takes the best candidate (the one closest to the query point) and explores it. Exploring in this context means adding the candidate (out neighbors) from the graph to the result set and marking it as visited. Notice the size of the result set has to stay bounded, so every time it grows too much, we only keep those L points closer to the query. The bigger the maximum size of the result set, the more accurate the results and the slower the search. We stop searching when all points in the current set are visited and return the top k results.
On the other hand, the robust prune method optimizes the graph on a particular point p so that the greedy search will run faster. For that, it checks a list of visited nodes and selects on each iteration a point that minimizes the distance from p (the node for which we are currently optimizing the graph) and adds it to the out neighbors of the node p. It also removes the nodes that could be reached from the newly added node with a shorter distance than from p (amplifying the former distance by alpha to keep long-range connections).
Together, these two algorithms should enable fast searches with high recall.
Implementation observations
We initially implemented the Vamana algorithm as described, resulting in very good recall results. Yet the latency was not good at all. We have since realized that the performance decay was due to many set operations making the algorithm perform poorly as is.
In our revised implementation, we have modified the algorithm a bit to keep a copy of visited and current nodes on a single sorted list. Also, as the parameter L grows, the search on the sets becomes more expensive, so we already decided to keep a bit-based representation of the vectors residing on the sets, which made a huge impact performance-wise. With these changes alone, we achieved performance close to Microsoft's implementation, as shown in (fig. 3) and (fig. 4). Note that the implementation from Microsoft is in C++, and our implementation is in Go.
We evaluated different data structures and achieved the best performance by:
- Keeping a sorted array-based set.
- Making insertions use binary search.
- Making the copy function from Go to move full memory sections.
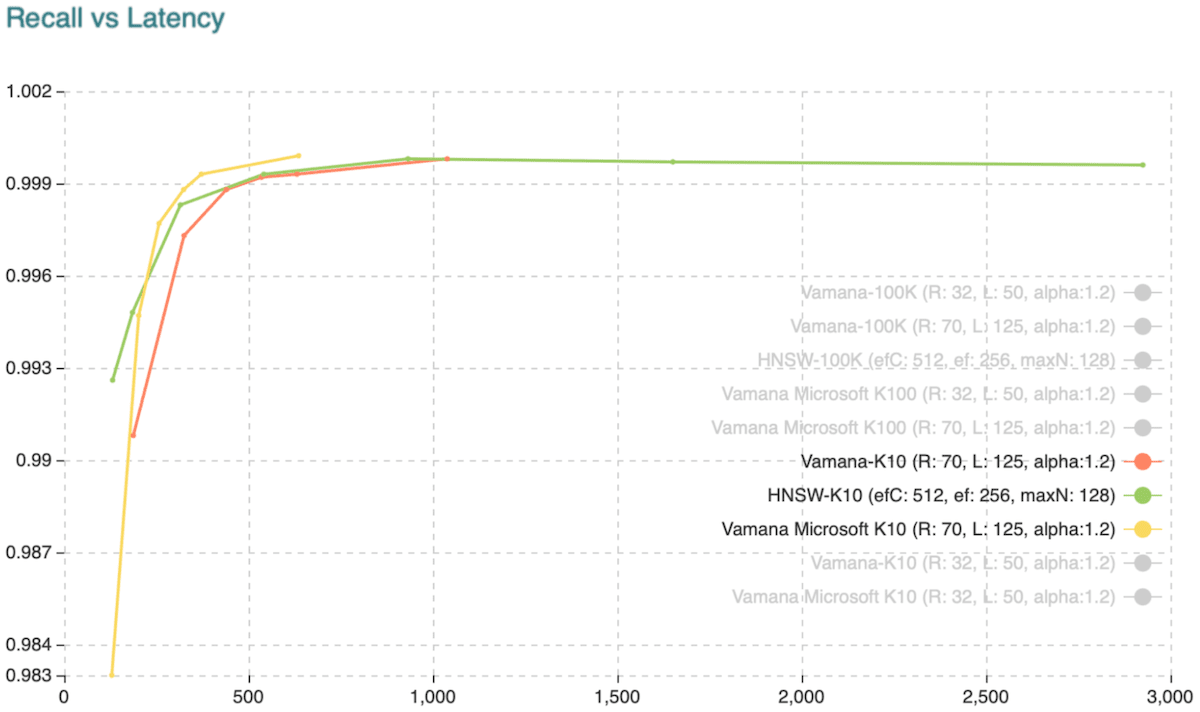 Fig. 3: Recall vs. Latency when retrieving the ten approximate nearest neighbors.
Fig. 3: Recall vs. Latency when retrieving the ten approximate nearest neighbors.
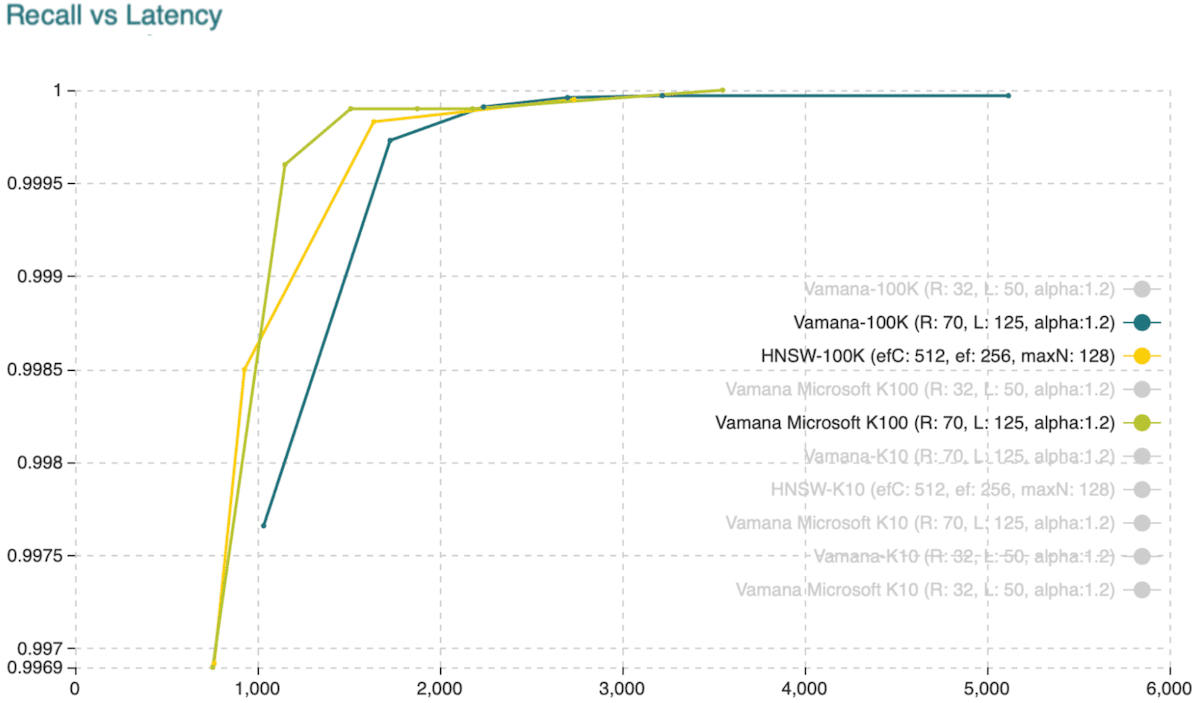 Fig. 4: Recall vs. Latency when retrieving the hundred approximate nearest neighbors.
Fig. 4: Recall vs. Latency when retrieving the hundred approximate nearest neighbors.
So, when do SSDs come into play?
But wait, is this the end of it? Was moving to disk, not the final goal? We are still on memory, are we not? Don't worry. This was just the first step toward our goal. We want to ensure that we have a solid implementation in memory before we move to disk, and this milestone ends here.
!Spoilers alert, as you read this article, we are evaluating our implementation on disk.
We will prepare a similar article to outline; how we moved everything to disk and what the price was performance-wise.
Conclusions
We've managed to implement the indexing algorithm on DiskANN, and the resulting performance is good.
From years of research & development, Weaviate has a highly optimized implementation of the HNSW algorithm. With the Vamana implementation, we achieved comparable in-memory results.
There are still some challenges to overcome and questions to answer. For example:
- How do we proceed to the natural disk solution of Weaviate?
- Should it be just an implementation of DiskANN?
- Or should we explore the capabilities of HNSW and adjust it to work on disk?
- How can we guarantee the excellent database UX – so valuable to many Weaviate users – while reaping the benefits of a disk-based solution?
Stay tuned as we explore these challenges and questions. We will share our insights as we go. 😀
Keep in touch and check our blog from time to time.
Ready to start building?
Check out the Quickstart tutorial, or build amazing apps with a free trial of Weaviate Cloud (WCD).
Don't want to miss another blog post?
Sign up for our bi-weekly newsletter to stay updated!
By submitting, I agree to the Terms of Service and Privacy Policy.