
The Details Behind the Sphere Dataset in Weaviate

Earlier in December, we wrote a blog post about importing the Sphere dataset into Weaviate. In that post, we talked about what the Sphere dataset is, announced the release of the Sphere dataset files for Weaviate, and shared how you can use Weaviate to search through large datasets like Sphere. More specifically, we provided a short guide on how you could import Sphere into Weaviate using Python as well as Spark, before finishing with example queries on the entire Sphere dataset. If you haven’t checked that out we recommend you have a quick look!
In this post, we will pull back the curtains and go behind the scenes to show you how we got all of that data into Weaviate. You will see all the gory details of what it took to get all ~1 billion (898 million) article snippet objects from Sphere and their vector representations into Weaviate. We’ll also dive into the hardware and software setup that was used along with the performance metrics behind the import process.
If you are:
- Interested in ingesting a large dataset or corpus into Weaviate
- Wondering how to use Apache Spark (or pyspark) with Weaviate, or
- Wondering what it took for us to get a dataset that big into Weaviate,
This article will answer at least some of those questions.
We note that our goal was to import 1B objects into Weaviate to see how the system behaves. Currently, for large datasets RAM is the most likely bottleneck, so we used node sizes that were larger than needed, to be on the safe side.
Now let’s get to the details of the setup!
The Setup

Hardware:
To set up our cluster we provisioned 6 Node GKE’s (Google Kubernetes Engine) located in US Central1 Region (Zone C). Each node was an instance of type m1-ultramem-40, which is a Memory optimized instance of 40 vCPU’s with a RAM of 961 GiB. So, in total our setup had 240 vCPUs and 5766 GiB of memory. We chose Memory optimized instances because the Compute optimised ones did not have enough memory. In hindsight, we might have gotten away with smaller instances since the RAM usage per instance peaked at about 600GiB.
Software (Weaviate and Spark):
Weaviate
We deployed 6 instances of Weaviate (one on each GKE node with automatic sharding per node for a total of 6 shards) where we gave Weaviate the entirety of the resources available on the machine. Additionally, each Weaviate instance had 1800 GiB of disk memory and the text2vec-huggingface vectorizer module enabled. We didn’t need to perform any vectorization of the dataset because the Sphere dataset comes with pre-computed vectors, the vectorizer module was meant to vectorize queries only. The Weaviate version used was built from v1.16.0 with a preview of the Hybrid Search functionality. You can see an example of the hybrid search in action in our previous post and last week with v1.17 we officially released this Hybrid Search functionality for you to try as well!
Using the Spark Connector
To import the dataset into Weaviate, we used the Spark Connector instead of one of our client libraries. The massive size of this dataset led to the use of the Spark dataframe, and the Spark connector can efficiently populate Weaviate from a Spark dataframe. Another time-saving feature is that the connector is able to automatically infer the correct datatype for your Weaviate class schema based on the Spark DataType. (We have a podcast speaking with the creator of the Spark connector coming up soon on our YouTube channel so keep your eyes and ears peeled for that!)
We used a single 64 GiB Google Cloud Platform(GCP) n2 instance to run Spark. The steps below can be followed to import data from the Sphere dataset. You can refer to this tutorial for details on the import code.
If you are following along, make sure to modify the code to import only as much of the Sphere dataset as you dare, as it might potentially become a very expensive exercise! First, using the
pysparklibrary, you can instantiate a connection, called aSparkSession:
spark = (
SparkSession.builder.config(
"spark.jars",
"gcs-connector-hadoop3-latest.jar,weaviate-spark-connector-assembly-v0.1.2.jar",
)
.master("local[*]")
.appName("weaviate")
.getOrCreate()
)
Following this you need to import the Sphere dataset into a Spark dataframe, by loading the Parquet files that we have made available:
NOTE: because of the high volume of downloads, please request access via hello@weaviate.io
df = spark.read.parquet("gs://sphere-demo/parquet/sphere.899M.parquet")
Next up, spin up a Weaviate instance (or cluster), connect to it and create a schema for the Sphere dataset:
client = weaviate.Client("http://localhost:8080")
client.schema.create_class(
{
"class": "Sphere",
"properties": [
{"name": "raw", "dataType": ["string"]},
{"name": "sha", "dataType": ["string"]},
{"name": "title", "dataType": ["string"]},
{"name": "url", "dataType": ["string"]},
],
}
)
Then import the contents of the Spark dataframe into Weaviate:
df.withColumnRenamed("id",
"uuid").write.format("io.weaviate.spark.Weaviate") \
.option("batchSize", 100) \
.option("scheme", "http") \
.option("host", "localhost:8080") \
.option("id", "uuid") \
.option("className", "Sphere") \
.option("vector", "vector") \
.mode("append").save()
When this is done, your instance of Weaviate should have finished ingesting the specified data from Spark and be ready to go. The entire import took approximately 48 hours for us, but your mileage may vary of course, depending on your setup and how much of the Sphere data you are importing.
With the setup above our main goal was to look at system performance while importing 1B objects but we are working on another, further scalable solution using technologies such as Vamana, and HNSW+PQ. Vamana will allow for disk based Approximate Nearest Neighbours(ANN) search and with HNSW+PQ we are using HNSW to build and search a graph over product quantized (PQ) encoded, compressed vectors. Both of these developments should help with memory usage at scale - if you’d like to dig deeper have a read here. More to come on this as we get into the new year, this is just a sneak peek at what our engineering team is cooking up for all of you!
Import Performance Metrics

In this section let’s take a look at a few stats related to the Sphere import run. This will give you an idea of the Weaviate cluster’s performance over the course of this massive import process.
Let’s start off with a bird’s eye view of the whole run. As mentioned above, the entire process took approximately 48 hours and on a high level the system performed very well. The graph beneath the text show the number of vectors imported over time:

As can be seen the slope, indicating import speed, is almost linear. meaning that we see pretty much no slow down in the import times regardless of the quantity of objects already imported. Note here that the line is not completely straight due to the fact that time complexity of the HNSW index is roughly logarithmic and not linear.
To remind ourselves of the scale of data that we’re dealing with, take a look at the bar chart below. It shows the size of the LSM stores.
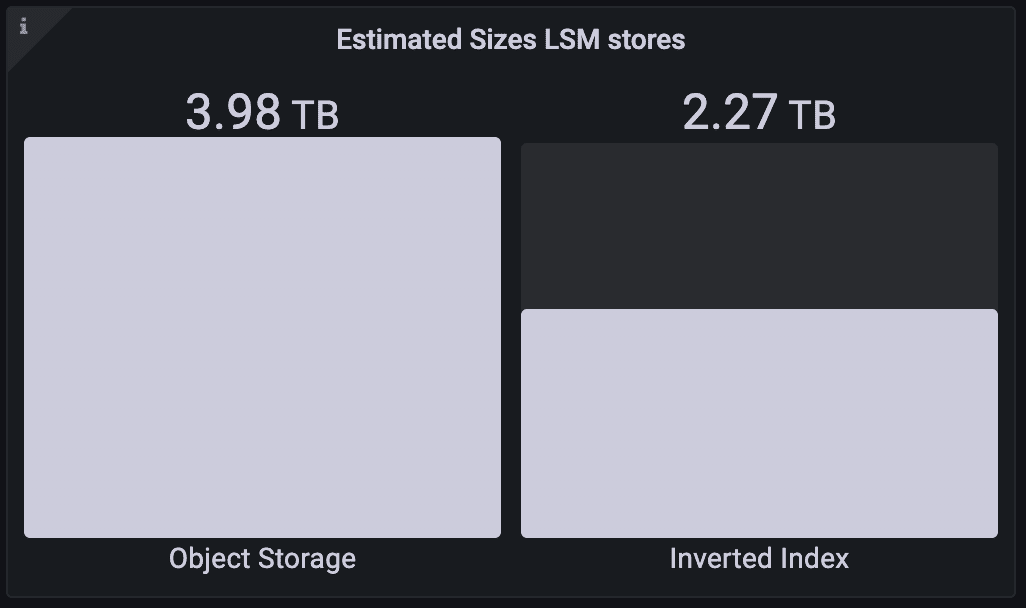
The object store stores the objects and their vectors, and the inverted index powers BM25+filter searches. The inverted index is not strictly required, but is mainly there to provide efficient filtering and more than worth the storage space it takes up. The LSM store size is well into terabytes of data - and yet Weaviate continues to perform admirably!
Now we’ll zoom in and look at performance over a window of 15 minutes of batch imports. To provide a little context, we used 22 parallel batches each with a batch size of 100. An average batch duration of around 1s was great to work with since the batches are large enough for Weaviate to receive enough data to process without it being a bottleneck, yet small enough to minimize the risk of timing out.
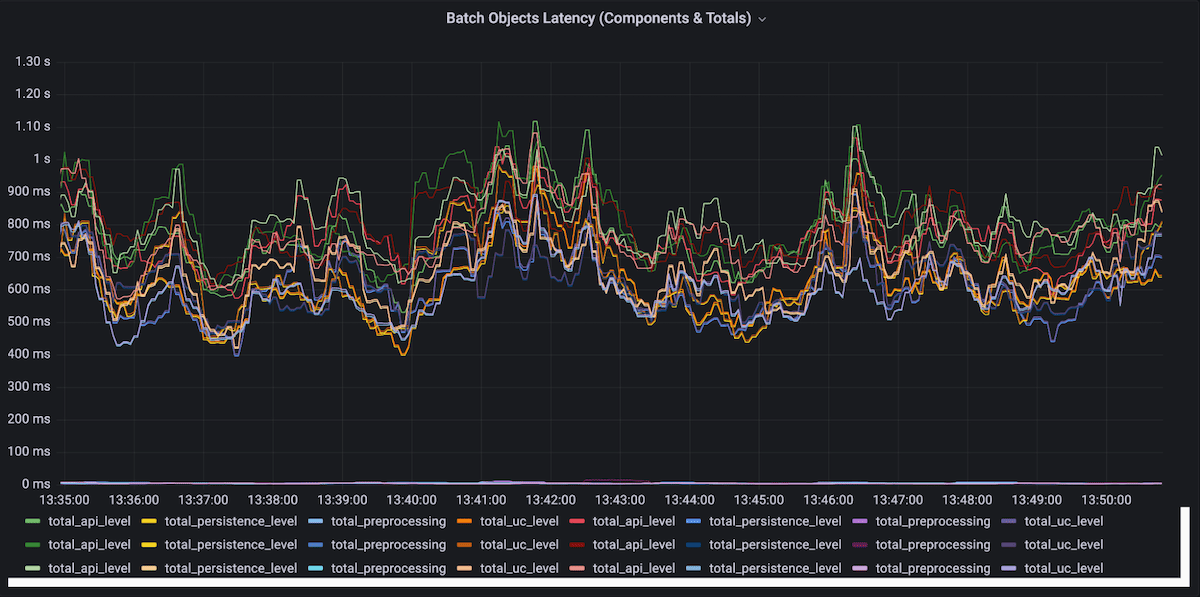
As seen in the time window above we get great consistent performance and generally the batch latency is low, keeping under a second for the most part. With last week’s v1.17 release, large dataset imports are made even faster by enabling the memtable to adjust size dynamically and additional fixes also remove the occasional latency spikes.
And that’s all folks! Here we provided all the details of the hardware setup, the usage of the Spark connector and system performance during the Sphere dataset import run. Hope you had as much fun reading this as I did putting it together! As I alluded to earlier if this work excites you then you’ll be glad to know that we’ve got a lot more updates along this line of work cooking in the Weaviate kitchen🧑🍳.
Ready to start building?
Check out the Quickstart tutorial, or build amazing apps with a free trial of Weaviate Cloud (WCD).
Don't want to miss another blog post?
Sign up for our bi-weekly newsletter to stay updated!
By submitting, I agree to the Terms of Service and Privacy Policy.