
Discover Healthsearch Unlocking Health with Semantic Search ✨
🛠️ Bridging semantic and generative search!
Isn’t it annoying when you just want to find a remedy for your headache and instead find out that you have a horrible disease? You google your symptoms and after digging into the first few search results, there is no doubt, you're probably going to die from a terrible disease in just a matter of hours. Spoiler alert, it's almost never the case. The phenomenon is called Dr. Google, and to save you the stress, we want to help you explore what others have found that may have helped them for their conditions.
Try out the live demo here✨

Healthsearch is a technical demonstration and acts as a proof of concept. The results shown in Healthsearch should not be taken as health advice or is it the intention of this demo. The search results are based on the semantic similarity between the query and user-written reviews.
Imagine you could type in I need to sleep better and instantly get a list of related supplements where other users have written reviews claiming it has helped them sleep better. Or you're dealing with persistent joint pain and looking for a natural supplement to alleviate discomfort.
We are excited to release our latest open source demo, Healthsearch. This demo decodes user-written reviews of supplements and performs semantic- and generative search on them, retrieving the most related products for specific health effects based on the reviews, and leveraging Large Language Models to generate product and review summaries. The demo can understand natural language queries and derive all search filters directly from the context of your query.
In this blog post, I’ll give you a quick tour of the Healthsearch project and its amazing features. We will also go through the implementations and the challenges I faced while working on it.
We’re providing all the source code on GitHub for you to discover and use for your own projects.
💡 User-Centric Design for Intuitive Search
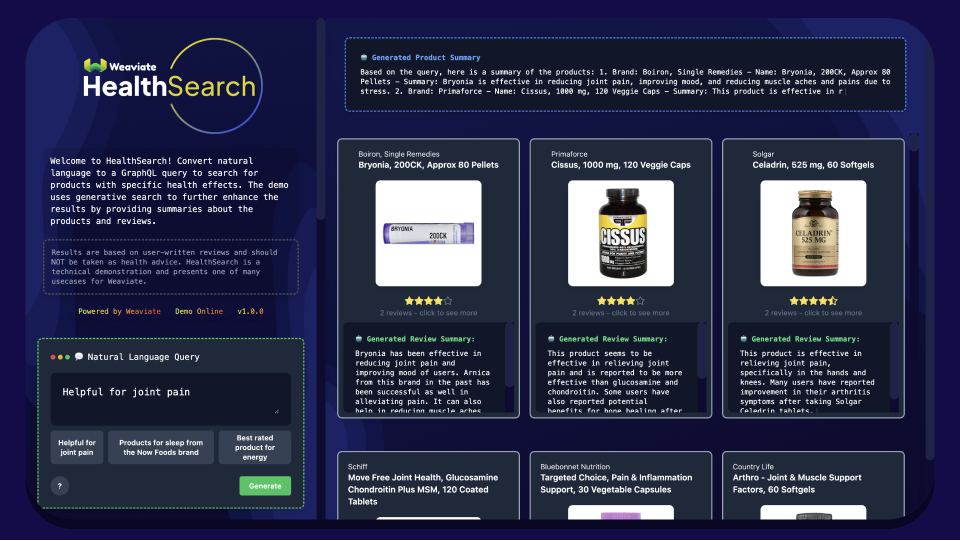
The first thing you might notice is the search bar on the left. It’s more than just a simple search tool. It has been designed to accept any natural language query to help you find supplements for your specific health effects. For example, queries could range from Good for joint pain and Improve muscle regeneration to Better sleep. But here's the twist - unlike typical search experiences, you won't find any filters on specific fields, no sorting, or result limits.
That's where the magic begins!
We use Large Language Models (LLM), like GPT4, to translate your everyday language query into a structured query format, called a GraphQL query.
You might be wondering, what is a GraphQL query? In simple terms, it's a powerful query language that allows us to ask for specific information we need, rather than getting a predefined set of information.
The exciting part is that we can extract information about filters, sorting, and limits directly from the context of your query. So, whether you're asking for the top 10 products for glowing skin, products for sleep from a specific brand, or best-rated products for toothache, our demo can interpret these queries and generate an appropriate GraphQL query in return.
To me, it was great to see that we got the feature to work for a couple of examples. Although it’s imperfect and needs some refinement, I think, the feature has exciting potential to improve the general search experience. Here's a example conversion from natural language to GraphQL.
Details
Natural Language Query
Products for sleep from the Now Foods brandGraphQL
{
Get{
Product(
nearText: {concepts: ["sleep"]}
where: {
path: ["brand"],
operator: Equal,
valueString: "Now Foods"
}
) {
name
brand
ingredients
reviews
image
rating
description
summary
effects
_additional {
id
distance
}
}
}
}
Now, let's delve deeper into what happens behind the scenes. Upon receiving the natural language query, we use the GPT4 Chat Completion API to generate a GraphQL query. The Chat Completion feature works like having a conversation with an AI. You provide a series of messages as input, and the model generates a relevant response as output.
We provide the model with examples of using Weaviate’s nearText feature, sorting mechanisms, filters, and limits, to let it generate a query that is compatible with Weaviate.

🔮 Apply it to your own use-case!
This feature is not restricted to health supplements and can be adapted to any other domain. Using other LLM providers and open source alternatives is encouraged and something we want to try in the future! To get started, you are welcome to explore all the source code in our GitHub repository to see how it is implemented line by line. Simply clone the project and read the documentation to set up the demo! (If you’re familiar with Docker, it’ll take just one command to setup everything 😈)
-
Accuracy With LLM outputs, consistency is not given, making it tricky to guarantee a certain level of query quality. You could experiment with different models that could lead to better outcomes. However, to be able to compare results between LLMs, you would need to evaluate your search results based on search metrics like Normalized Discounted Cumulative Gain (NDCG). Something that I’m eager to try is the new function-calling feature of OpenAI.
-
Limitations The critical part of successful query generation was the provision of the correct documentation and optimizing prompts. But, to reduce the overhead of prompt engineering, I think, fine-tuning LLMs or using systems that can retrieve specific documentation to use as context could also be a better approach to tackling this.
-
Performance Using GPT-4 gives good results, but it’s very slow. I hope the technology improves and alternatives arise that are better and faster. To use this feature in production I would recommend choosing a faster LLM and trade-off some quality.
🔎 Decoding reviews with Semantic Search
How does Healthsearch determine which supplements are suitable for specific health effects? It relies on the power of semantic search in user reviews. When you're seeking products that are good for joint pain, for instance, Healthsearch scans user reviews for discussions on products that have alleviated joint pain or similar conditions. The results are then aggregated and grouped according to their respective products. As I mentioned before, all results are purely based on the content of user-written reviews.
The strength of Semantic Search truly shines in this use case because reviews are often unstructured, and reviews can be expressed in numerous ways. Phrases such as good for joint pain, helpful for joint pain, and improves arthritis, may differ in wording but bear the same semantic meaning. Capturing these variations is important for this specific use case and it’s also universally applicable to other use cases involving user reviews.
But how did we accomplish this with Weaviate? The process is surprisingly straightforward. We created Product objects embedded with their reviews, summaries, and other metadata, to enable semantic search. To optimize performance, we vectorize specific fields using the gpt-3.5-turbo model and leave out fields that do not require vectorization. We choose the model because it’s faster than GPT4, but you can use any other embedding model (Cohere, HuggingFace, etc.).
Product Schema
class_obj = {
"class": "Product",
"description": "Supplement products",
"properties": [
{
"dataType": ["text"],
"description": "The name of the product",
"name": "name",
"moduleConfig": {
"text2vec-openai": {
"skip": True,
"vectorizePropertyName": False,
}
},
},
{
"dataType": ["text"],
"description": "The brand of the product",
"name": "brand",
"moduleConfig": {
"text2vec-openai": {
"skip": True,
"vectorizePropertyName": False,
}
},
},
{
"dataType": ["text"],
"description": "The ingredients contained in the product.",
"name": "ingredients",
"moduleConfig": {
"text2vec-openai": {
"skip": False,
"vectorizePropertyName": True,
}
},
},
{
"dataType": ["text[]"],
"description": "Reviews about the product",
"name": "reviews",
"moduleConfig": {
"text2vec-openai": {
"skip": True,
"vectorizePropertyName": False,
}
},
},
{
"dataType": ["text"],
"description": "Image URL of the product",
"name": "image",
"moduleConfig": {
"text2vec-openai": {
"skip": True,
"vectorizePropertyName": False,
}
},
},
{
"dataType": ["number"],
"description": "The Rating of the product",
"name": "rating",
"moduleConfig": {
"text2vec-openai": {
"skip": True,
"vectorizePropertyName": False,
}
},
},
{
"dataType": ["text"],
"description": "The description of the product",
"name": "description",
"moduleConfig": {
"text2vec-openai": {
"skip": False,
"vectorizePropertyName": True,
}
},
},
{
"dataType": ["text"],
"description": "The summary of the reviews",
"name": "summary",
"moduleConfig": {
"text2vec-openai": {
"skip": False,
"vectorizePropertyName": True,
}
},
},
{
"dataType": ["text"],
"description": "The health effects of the product",
"name": "effects",
"moduleConfig": {
"text2vec-openai": {
"skip": False,
"vectorizePropertyName": True,
}
},
},
],
"moduleConfig": {"generative-openai": {"model": "gpt-3.5-turbo"}},
"vectorizer": "text2vec-openai",
}
To give you a clearer picture, we define a new class in the Weaviate database (similar to a blueprint) using a Python dictionary. This class includes fields like product name, brand, reviews, ratings, etc. Each field's datatype is specified, which can be text, image, number, etc., and a brief description and field name is added. Some fields are configured to be vectorized, meaning their semantic content will be incorporated into the overall vector indexed in the database. Fields like rating or image URLs, which do not contribute to the semantic richness, are excluded to maintain the embedding quality.
One of the critical factors to consider when using a semantic search on user reviews is the authenticity and relevance of the reviews. Ensuring that the dataset is free of fake or irrelevant reviews before feeding it into the database for semantic search is vital.
In developing Healthsearch, I leveraged a model from my bachelor thesis, a spaCy model known as Healthsea. This model quickly analyzes reviews and filters those focusing on health effects, enhancing the quality of input for our semantic search. While I did not incorporate a specific fake review filter for Healthsearch, I did tackle this challenge in my thesis. For those interested in exploring how to handle fake reviews, I delve deeper into the topic in this article: Healthsea.
💥 Amplifying Search Results with Generative Search
After the translation of the query to GraphQL and the retrieval of the most semantically relevant product, we enhance our demo with a feature called Generative Search. Essentially, we examine the top five results and employ an LLM to generate a product summary. This concise summary offers a brief overview of the products, highlighting their pros and cons and providing valuable insights. The icing on the cake? Each summary is crafted around your query, ensuring every search is unique and interesting.
This greatly enhances user experience, as you can quickly understand the products by reading the summary. It simplifies complex information and aids swift decision-making. This methodology is versatile and can be applied to numerous other use cases besides creating summaries.
For a more detailed exploration of the generative feedback loop with Weaviate, we have an amazing blog post by Connor.
The implementation of Generative Search in Weaviate involves using the generate module to define the prompt and the fields that will be used as context. For every generated query, another query is created using the generate module. This is done to ensure only the top 5 products are considered (to manage context length), and these queries are executed in parallel. The result is a list of the top 5 products with their generated summaries.
GraphQL with generate module
{
Get {
Product(
limit: 5
nearText: {concepts: ["Helpful", "joint pain"]}
) {
ingredients
description
summary
_additional {
generate(
groupedResult: {
task: "Summarize products based on this query: Helpful for joint pain"
}
) {
groupedResult
error
}
id
distance
}
}
}
}
}
While generative search offers immense potential, it comes with its own set of challenges:
-
Quality Control
Since each generated summary hinges on the user query, ensuring the quality of these texts can be a significant hurdle. The challenge here: How can we consistently produce accurate, relevant, and useful summaries tailored to each unique query and evaluate them?
-
Performance
Since we're using GPT4 (again), the processing takes time, which makes the search experience a bit exhausting. I recommend finding other and faster alternatives when processing time is essential for your use case.
🔥 Introducing Semantic Caching
Generating a query and its summary, mainly when using the GPT4 model, can be a time-intensive process. Consequently, caching previous results becomes crucial to improving the system's efficiency. Caching also helps when encountering LLM API outages, creating a new dependency layer for your project. But what if we could take it a step further? What if we employed Weaviate as a cache and took advantage of its semantic search capabilities?
“Helpful for joint pain” versus “Good for joint pain”
If we relied solely on string matching, these two queries would be distinct. However, when we delve into their semantic context, they convey the same meaning. So, why not embed the queries to return cached results when the semantic meaning of a query closely aligns with a previous one?
This approach, which I call Semantic Caching, is advantageous as it enables us to extract much more from generated results than traditional string matching would permit. It's a simple yet potent solution that enhances the efficiency of the search process.

💚 Open Source is the way
The repository for this project is entirely open-sourced, granting you access to every line of code, both front-end and back-end. We also offer an extract of our supplement dataset, enabling you to run the entire demo on your personal device. The demo can serve as a starting point and a template for displaying your own data.
This blog post introduced you to Healthsearch, a cool demo that allows you to explore health supplements using natural language queries based on specific health effects. We looked at Semantic and Generative Search, translated search instructions to GraphQL, and used Weaviate as a Semantic Cache. I hope this blog post inspired you and that you find some of the presented features useful for your own projects!
Thank you for taking the time to read this blog post. We invite you to check out our repo and delve into the fascinating world of semantic and generative search! 💚

Ready to start building?
Check out the Quickstart tutorial, or sign up for a free Weaviate Cloud account.
Don't want to miss another blog post?
Sign up for our bi-weekly newsletter to stay updated!
By submitting, I agree to the Terms of Service and Privacy Policy.