
How A.I. Creates Art - A Gentle Introduction to Diffusion Models

One of the major developments this past year were the advancements made in machine learning models that can create beautiful and novel images such as the ones below. Though machine learning models with the capability to create images have existed for a while, this previous year we saw a marked improvement in the quality and photo-realism of the images created by these models.

Models like DALL·E 2, Stable Diffusion and others which are the technologies underlying many platforms such as Lensa and Midjourney are being used by millions of people and are quickly becoming main stream as people realize their potential.
These models not only have the ability to dream up photo-realistic images when prompted with text input but can also modify given images to add details, replace objects or even paint in a given artists style. See below for the Mona Lisa drip painted in the style of Jackson Pollock!

The technology behind these images is called diffusion models. In this post I aim to provide a gentle introduction to diffusion models so that even someone with minimal understanding of machine learning or the underlying statistical algorithms will be able to build a general intuition of how they work. Additionally I’ll also provide some external resources that you can use to access pre-trained diffusion models so you can start to generate your own art!
These are the points that we’ll expand on in this article:
- How diffusion models can create realistic images
- How and why we can control and influence the images these models create using text prompts
- Access to some resources you can use to generate your own images.
How Diffusion Models Work
Diffusion models are a type of generative model - which means that they can generate data points that are similar to the data points they’ve been trained on(the training set). So when we ask Stable Diffusion to create an image it starts to dream up images that are similar to the billions of images from the internet that it was trained on - it’s important to note that it doesn’t simply copy an image from the training set(which would be no fun!) but rather creates a new image that is similar to the training set. Generative models are not limited to just generating images; they can also generate songs, written language or any other modality of data - however to make it easier for us to understand we will only consider generative models that for image data.
The core idea behind all generative models is that they learn what the training set “looks” like. In other words, generative models learn the underlying distribution of the training set. That means that they know the likelihood that a data point will be observed in the training set. For example, if you are training a generative model on images of beautiful landscapes then, for that generative model, images of trees and mountains are going to be much more common then images of someones kitchen. Furthering this line of reasoning, for that same generative model, an image of static noise would also be quite unlikely since we don’t see that in the training set. This seems like a weird point to make but it will be very important later on!

Learning the true underlying distribution of any set of images is not computationally feasible because it requires you to consider every pixel of every image. However, if our model could learn the underlying distribution of the training set of images it could calculate the likelihood that any new image came from that set. It could also generate novel images that it thinks are most likely to belong to the training set. One way to do this, using the underlying distribution, would be to start off with static noise (an image with random pixel values) and then slightly alter pixel values over and over again while making sure each time you alter the pixel values it increases the likelihood of the overall image coming from the dataset - this is indeed what diffusion models do!
The question then becomes how diffusion models can learn (or even approximate) the underlying distribution of the images in your training set? The main insight behind how this happens is: if you take any image from your training set and add a small amount of random static noise to it you will create a new image that is slightly less likely - since images with random noise are unlikely to be seen in the training set. Thus you could take any image from your training set, and step by step, add increasing levels of random noise to it and generate incrementally more noisy versions of that image as shown below.
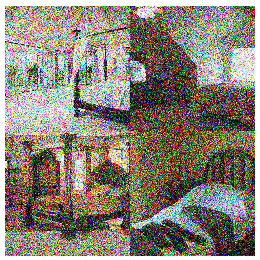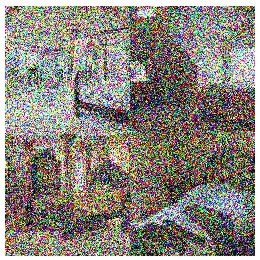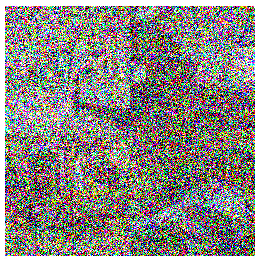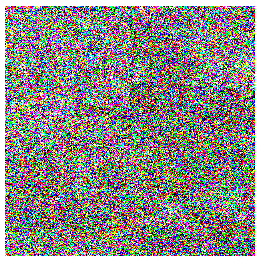

This “noising” process, shown in the images above allows us to take training set images and add known quantities of noise to it until it becomes completely random noise. This process takes images from a state of having high probability of being found in the training set to having a low probability of existing in the training set.
Once the “noising” step is completed, then we can use these clean and noisy image combinations during the training phase of the diffusion model. In order to train a diffusion model we ask it to remove the noise from the noised images step by step until it recovers something as close as possible to the original image. This process is known as “de-noising”, is illustrated below and, is carried out for each image in the training set with multiple levels of random noise added. Once the diffusion model is trained in this way it becomes an expert at taking images that are less likely to be seen in the dataset (noisy images) and incrementally turning them into something that is more likely to be seen in the training set. By teaching the model to “de-noise” images we have developed a way to alter images to make them more like images from the training set.


Now if we take this trained diffusion model and just give it a random static image and run the de-noising process it will transform the static image into an image that resembles images in the training set!

How Text Prompts Control the Image Generation Process
So far we have explained the general idea behind how diffusion models can start off from static noise and incrementally alter the pixel values so that the picture all together gains meaning and follows the distribution of the training set. However, another important detail is that most diffusion models don’t just spit out random images that look like training set images, they allow us to add a text prompt that can control the specific types of images are generated. The idea behind conditioning the images on a text prompt requires another model, one that is trained on images along with their captions. Examples of this data are shown below:

This model learns to relate descriptions of an image in text format with the image representation itself. In doing so it gives us a way to represent our written prompts as vectors that also capture the visual meaning behind the prompt. We can then pass these prompt vectors into our diffusion model along with the noised images during the training process. This allows us to tame the image generation process of the diffusion model by specifying to the model what types of images in the training set to resemble as it alters the pixels step by step.
The amount of control you have over exactly what is generated is quite fascinating, you can even engineer a paragraph length prompt to describe exactly what you want the diffusion model to create and watch as it brings multiple variations of your description to life.
Diffusion Model Resources to Create Art
Here are some diffusion models that you can use to generate images:
- Stable Diffusion on Hugging Face
- A notebook that uses the same Stable Diffusion model as above if you’d like to tinker with the code.
- Midjourney - allows you to create images by submitting prompts as discord messages
- A Web UI for Stable Diffusion
 “Searching through a high dimensional vector space”
“Searching through a high dimensional vector space”
Sources and Further Reading
Here I’ve attempted to provide a general intuition of how diffusion models work, there are many many more details that are involved in this process. If you enjoyed this introduction to diffusion models and would like to dive in deeper to get a better understanding of the code and algorithms involved I would recommend the following blog posts and courses in the following order or increasing complexity:
- The Illustrated Stable Diffusion
- Generative Modeling by Estimating Gradients of the Data Distribution
- The Annotated Diffusion Model
Ready to start building?
Check out the Quickstart tutorial, or sign up for a free Weaviate Cloud account.
Don't want to miss another blog post?
Sign up for our bi-weekly newsletter to stay updated!
By submitting, I agree to the Terms of Service and Privacy Policy.