
Vector Embeddings Explained
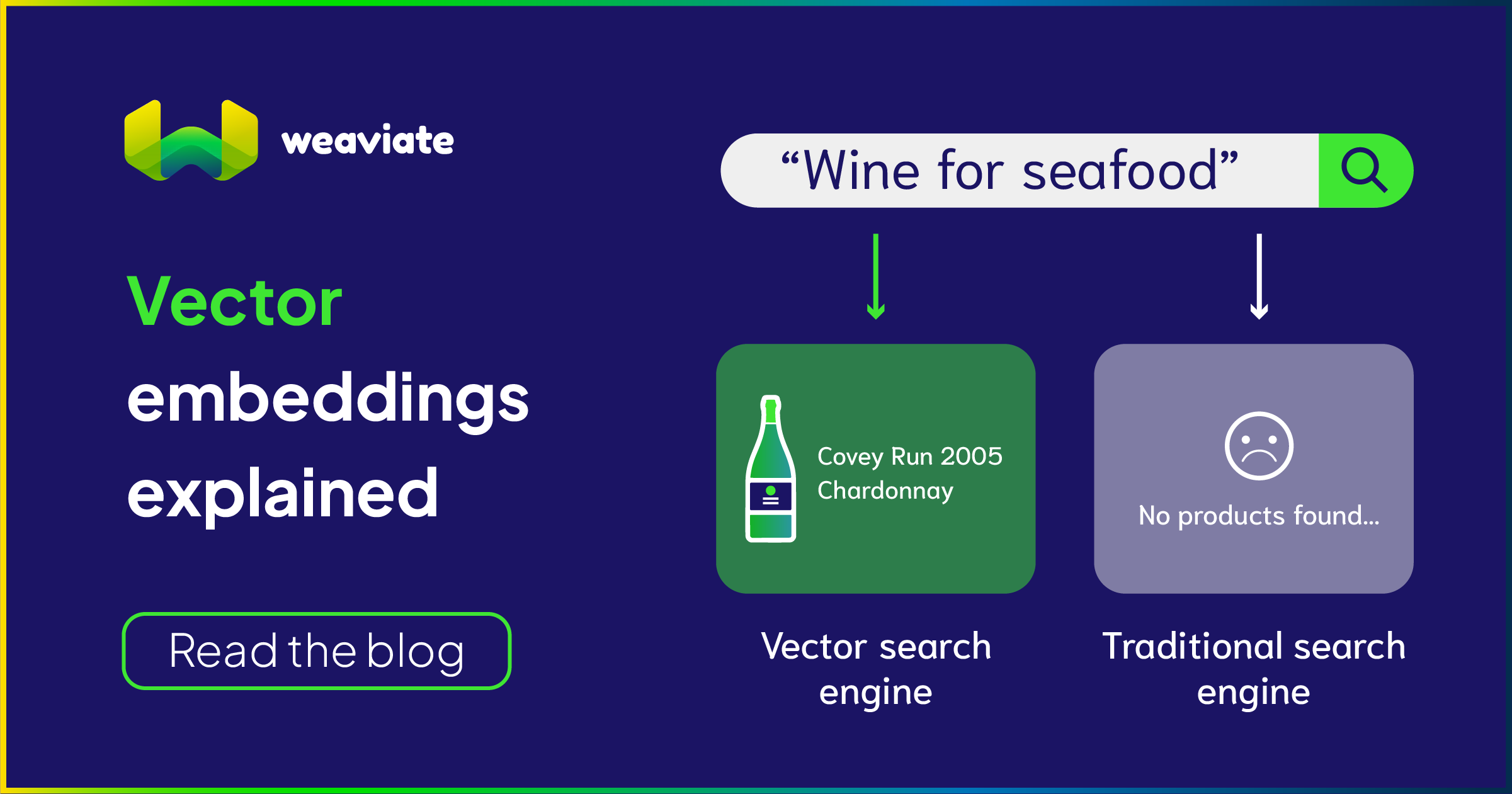
The core function of a vector embedding database - or simply a vector database - is to provide high-quality search results, going beyond simple keyword or synonym searches, and actually finding what the user means by the query, or providing an actual answer to questions the user asks.
Semantic searches (as well as question answering) are essentially searches by similarity, such as by the meaning of text, or by what objects are contained in images. For example, consider a library of wine names and descriptions, one of which mentioning that the wine is “good with fish”. A “wine for seafood” keyword search, or even a synonym search, won’t find that wine. A meaning-based search should understand that “fish” is similar to “seafood”, and “good with X” means the wine is “for X”—and should find the wine.
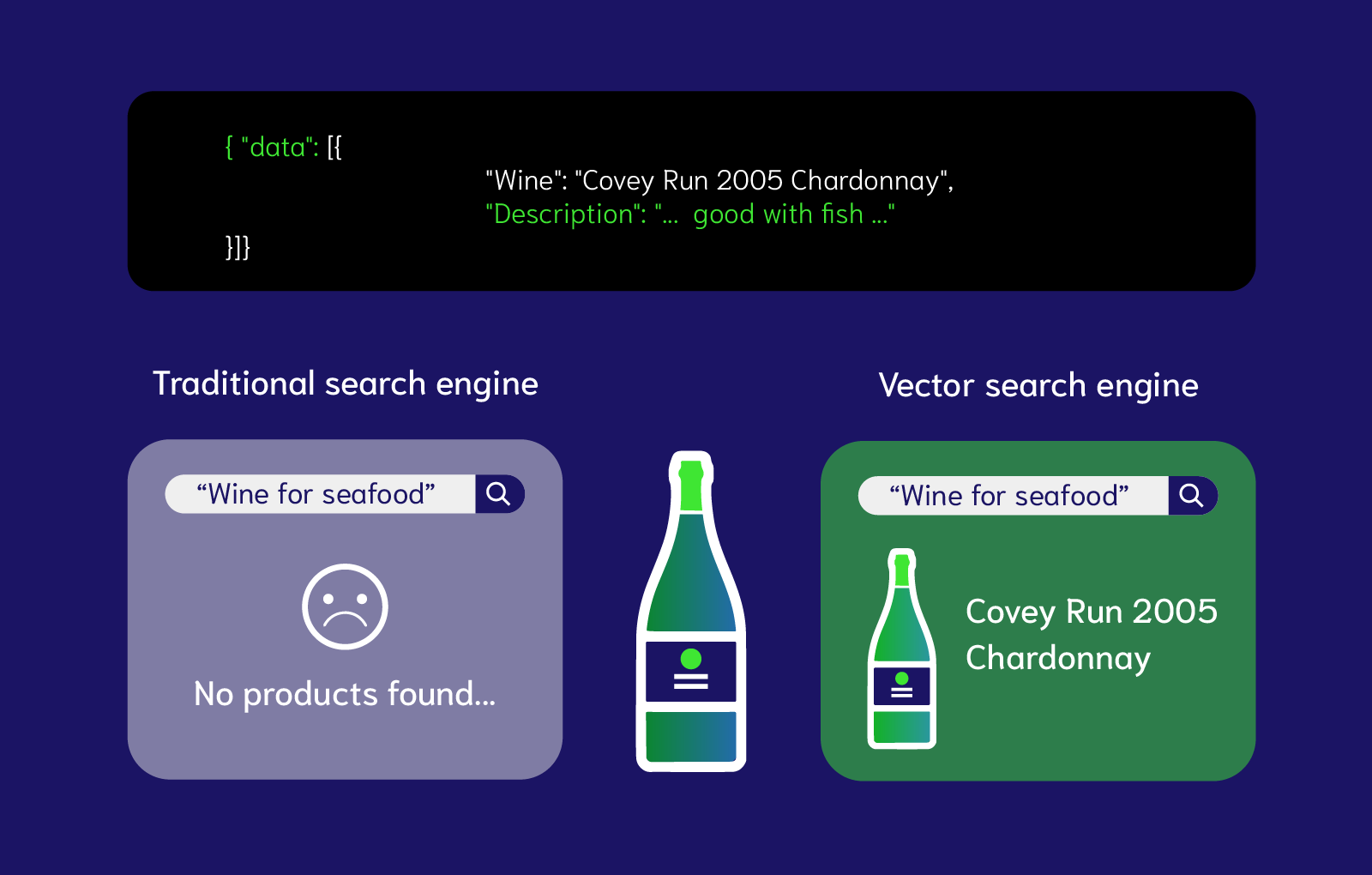
How can computers mimic our understanding of language, and similarities of words or paragraphs? To tackle this problem, semantic search uses at its core a data structure called vector embedding (or simply, vector or embedding), which is an array of numbers. Here's how the semantic search above works, step by step:
- The vector database computes a vector embedding for each data object as it is inserted or updated into the database, using a given model.
- The embeddings are placed into an index, so that the database can quickly perform searches.
- For each query,
- a vector embedding is computed using the same model that was used for the data objects.
- using a special algorithm, the database finds the closest vectors to the given vector computed for the query.
The quality of the search depends crucially on the quality of the model - this is the "secret sauce", as many models are still closed source. The speed of the search depends crucially on the performance capabilities of the vector database.
What are vector embeddings?
Vectors or vector embeddings are numeric representations of data that capture certain features of the data. They are mathematical representations of objects in a continuous vector space that are used to capture the semantic meaning or properties of these objects in a way that can be efficiently searched.
Vector embeddings example
For example, in the case of text data, “cat” and “kitty” have similar meaning, even though the words “cat” and “kitty” are very different if compared letter by letter. For semantic search to work effectively, embedding representations of “cat” and “kitty” must sufficiently capture their semantic similarity. This is where vector representations are used, and why their derivation is so important.
In practice, vector embeddings are arrays of real numbers, of a fixed length (typically from hundreds to thousands of elements), generated by machine learning models. The process of generating a vector for a data object is called vectorization. Weaviate generates vector embeddings using integrations with model providers (OpenAI, Cohere, Google PaLM etc.), and conveniently stores both objects and vector embeddings in the same database. For example, vectorizing the two words above might result in the following word embeddings:
cat = [1.5, -0.4, 7.2, 19.6, 3.1, ..., 20.2]
kitty = [1.5, -0.4, 7.2, 19.5, 3.2, ..., 20.8]
These two vectors have a very high similarity. In contrast, vectors for “banjo” or “comedy” would not be very similar to either of these vectors. To this extent, vectors capture the semantic similarity of words.
Now that you’ve seen what vectors are, and that they can represent meaning to some extent, you might have further questions. For one, what does each number represent? That depends on the machine learning model that generated the vectors, and isn’t necessarily clear, at least in terms of our human conception of language and meaning. But we can sometimes gain a rough idea by correlating vectors to words with which we are familiar.
Vector-based representation of meaning caused quite a stir a few years back, with the revelation of mathematical operations between words. Perhaps the most famous result was that of “king − man + woman ≈ queen”
It indicated that the difference between “king” and “man” was some sort of “royalty”, which was analogously and mathematically applicable to “queen” minus “woman”. Jay Alamar provided a helpful visualization around this equation. Several concepts (“woman”, “girl”, “boy” etc.) are vectorized into (represented by) an array of 50 numbers generated using the GloVe model. In vector terminology, the 50 numbers are called dimensions. The vectors are visualized using colors and arranged next to each word:
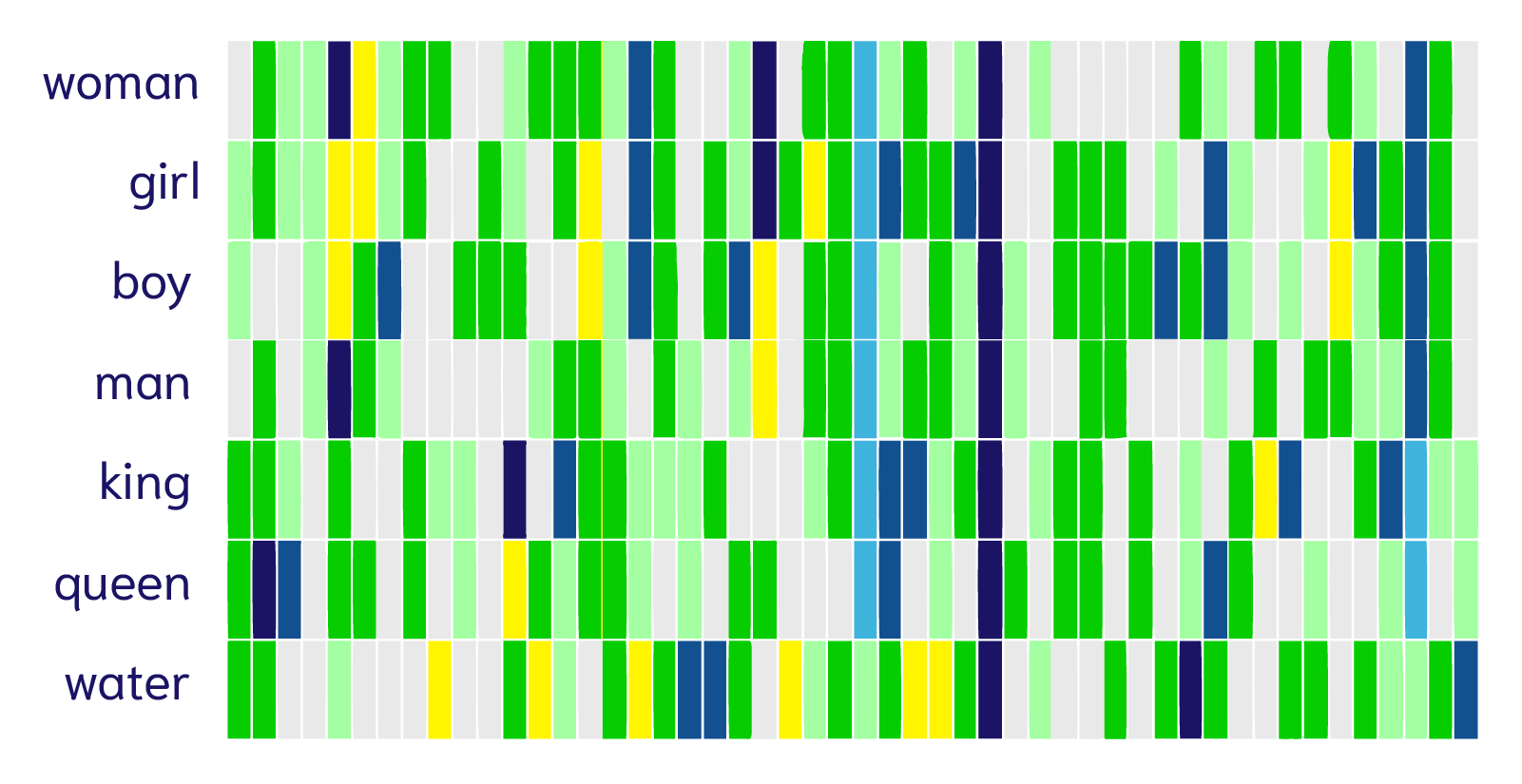
Credit: Jay Alamar
We can see that all words share a dark blue column in one of the dimensions (though we can’t quite tell what that represents), and the word “water” looks quite different from the rest, which makes sense given that the rest are people. Also, “girl” and “boy” look more similar to each other than to “king” and “queen” respectively, while “king” and “queen” look similar to each other as well. So we can see that these vector embeddings of words align with our intuitive understanding of meaning. And even more amazingly, vector embeddings are not limited to representing meanings of words.
Types of vectorizable data
Effective vector embeddings can be generated from any kind of data object. Text data is the most common, followed by images, then audio data (this is how Shazam recognizes songs based on a short and even noisy audio clip), but also time series data, 3D models, video, molecules etc. Embeddings are generated such that two objects with similar semantics will have vectors that are "close" to each other, i.e. that have a "small" distance between them in vector space. That distance can be calculated in multiple ways, one of the simplest being "The sum of the absolute differences between elements at position i in each vector" (recall that all vectors have the same fixed length). Let's look at some numbers (no math, promise!) and illustrate with another text example:
Objects (data): words including cat, dog, apple, strawberry, building, car
Search query: fruit
A set of simplistic vector embeddings (with only 5 dimensions) for the objects and the query could look something like this:
| Word | Vector embedding |
|---|---|
| cat | [1.5, -0.4, 7.2, 19.6, 20.2] |
| dog | [1.7, -0.3, 6.9, 19.1, 21.1] |
| apple | [-5.2, 3.1, 0.2, 8.1, 3.5] |
| strawberry | [-4.9, 3.6, 0.9, 7.8, 3.6] |
| building | [60.1, -60.3, 10, -12.3, 9.2] |
| car | [81.6, -72.1, 16, -20.2, 102] |
| Query: fruit | [-5.1, 2.9, 0.8, 7.9, 3.1] |
If we look at each of the 5 elements of the vectors, we can see quickly that cat and dog are much closer than dog and apple (we don’t even need to calculate the distances). In the same way, fruit is much closer to apple and strawberry than to the other words, so those will be the top results of the “fruit” query.
But where do these numbers come from? That’s where the real magic is, and where advances in modern deep learning have made a huge impact.
How to create vector embeddings?
The magic of vector search resides primarily in how the embeddings are generated for each entity and the query, and secondarily in how to efficiently search within very large datasets (see our “Why is Vector Search so Fast” article for the latter). As we mentioned, vector embeddings can be generated for various media types such as text, images, audio and others. For text, vectorization techniques have evolved tremendously over the last decade, from the venerable word2vec (2013), to the state-of-the-art transformer models era, spurred by the release of BERT in 2018.
Word-level dense vector models (word2vec, GloVe, etc.)
word2vec is a family of model architectures that introduced the idea of “dense” vectors in language processing, in which all values are non-zero. Word2vec in particular uses a neural network model to learn word associations from a large corpus of text (it was initially trained by Google with 100 billion words). It first creates a vocabulary from the corpus, then learns vector representations for the words, typically with 300 dimensions. Words found in similar contexts have vector representations that are close in vector space, but each word from the vocabulary has only one resulting word vector. Thus, the meaning of words can be quantified - “run” and “ran” are recognized as being far more similar than “run” and “coffee”, but words like “run” with multiple meanings have only one vector representation. As the name suggests, word2vec is a word-level model and cannot by itself produce a vector to represent longer text such as sentences, paragraphs or documents. However, this can be done by aggregating vectors of constituent words, which is often done by incorporating weightings such that certain words are weighted more heavily than others. However, word2vec still suffers from important limitations:
- it doesn’t address words with multiple meanings (polysemantic): “run”, “set”, “go”, or “take” each have over 300 meanings (!)
- it doesn’t address words with ambiguous meanings: “to consult” can be its own antonym, like many other words
Which takes us to the next, state-of-the-art, models.
Transformer models (BERT, ELMo, and others)
The current state-of-the-art vector embedding models are based on what’s called a “transformer” architecture as introduced in this paper. Transformer models such as BERT and its successors improve search accuracy, precision and recall by looking at every word’s context to create full contextual embeddings (though the exact mechanism of BERT’s success is not fully understood). Unlike word2vec embeddings which are context-agnostic, transformer-generated embeddings take the entire input text into account—each occurrence of a word has its own embedding that is modified by the surrounding text. These embeddings better reflect the polysemantic nature of words, which can only be disambiguated when they are considered in context. Some of the potential downsides include:
- increased compute requirements: fine-tuning transformer models is much slower (on the order of hours vs. minutes)
- increased memory requirements: context-sensitivity greatly increases memory requirements, which often leads to limited possible input lengths
Despite these downsides, transformer models have been wildly successful. Countless text vectorizer models have proliferated over the recent past. Plus, many more vectorizer models exist for other data types such as audio, video and images, to name a few. Some models, such as CLIP, are capable of vectorizing multiple data types (images and text in this case) into one vector space, so that an image can be searched by its content using only text.
Vector embedding visualization
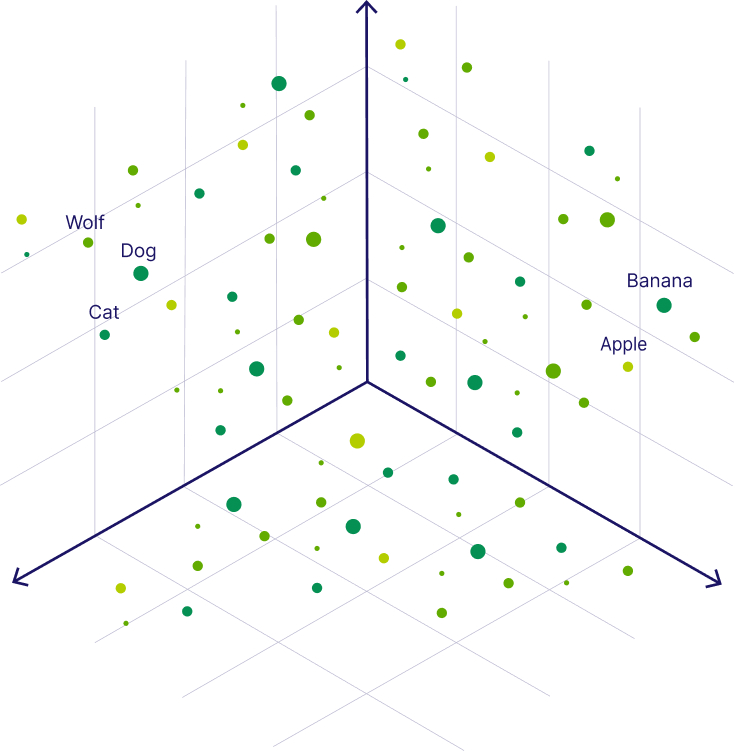
Below we can see what vector embeddings of data objects in a vector space could look like. The image shows each object embedded as a 3-dimensional vectors for ease of understanding, realistically a vector can be anywhere from ~100 to 4000 dimensions.
In the following image, you can see the vectors for the words “Wolf” and “Dog” are close to each other because dogs are direct descendants of wolves. Close to the dog, you can see the word “Cat,” which is similar to the word “Dog” because both are animals that are also common pets. But further away, on the right-hand side, you can see words that represent fruit, such as “Apple” or “Banana”, which are close to each other but further away from the animal terms.
Storing and using vector embeddings with a Weaviate vector database
For this reason, Weaviate is configured to support many different vectorizer models and vectorizer service providers. You can even bring your own vectors, for example if you already have a vectorization pipeline available, or if none of the publicly available models are suitable for you.
For one, Weaviate supports using any Hugging Face models through our text2vec-huggingface module, so that you can choose one of the many sentence transformers published on Hugging Face. Or, you can use other very popular vectorization APIs such as OpenAI or Cohere through the text2vec-openai or text2vec-cohere modules. You can even run transformer models locally with text2vec-transformers, and modules such as multi2vec-clip can convert images and text to vectors using a CLIP model.
But they all perform the same core task—which is to represent the “meaning” of the original data as a set of numbers. And that’s why semantic search works so well.
Summary
This blog explained the concept and definition of vector embeddings, which are at the core of vector databases and enable a modern search technique called vector search.
To summarize, vector embeddings are the numerical representation of unstructured data of different data types, such as text data, image data, or audio data. Depending on the data type, vector embeddings are created using machine learning models that are able to translate the meaning of an object into a numerical representation in a high dimensional space. Thus, there are a variety of machine learning models able to create a variety of different types of vector embeddings, such as word embeddings, sentence embeddings, text embeddings, or image embeddings.
Vector embeddings capture the semantic relationship between data objects in numerical values and thus, you can find similar data points by determining their nearest neighbors in the high dimensional vector space. This concept is also called similarity search and can be applied in different applications, such as text search, image search, or recommendation systems.
Now that you have a good understanding of what vector embeddings are and how vector embeddings are created, you might also be interested in the following articles:
- What is a vector database?
- Distance metrics for nearest neighbor search
- Why is vector search so fast?
Last Updated On: August 27th, 2024
Ready to start building?
Check out the Quickstart tutorial, or build amazing apps with a free trial of Weaviate Cloud (WCD).
Don't want to miss another blog post?
Sign up for our bi-weekly newsletter to stay updated!
By submitting, I agree to the Terms of Service and Privacy Policy.