
Weaviate 1.26 Release
Weaviate 1.26 is here!
Here are the release ⭐️highlights⭐️!

- Improved Range Queries
- Async Replication
- Anthropic integration
- Bulk enable API-based modules
- Multi target vector search
- Tenant states changed
- Tenant offload to cloud storage
- Async Python client
- Scalar Quantization
- Dashboards for async indexes
- Korean tokenizer
- Additional changes
Improved Range Queries
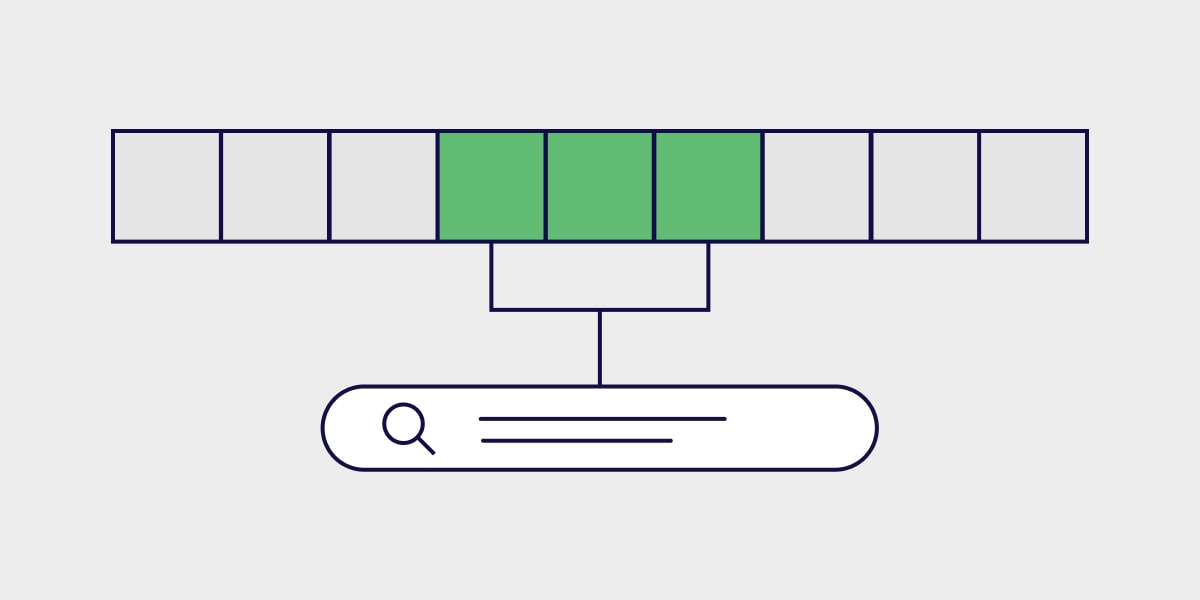
The rangeable index is a powerful new tool for quantitative comparisons.
Object properties in Weaviate can be indexed for faster filtering. In earlier releases, range queries are computationally expensive. The new rangeable index (indexRangeFilters) provides a more efficient way to quickly filter ranges of data.
When you anticipate using numerical comparisons over ranges of values, enable the new rangeable index in your collection schema. The rangeable index is available for int, number, and date data types.
The rangeable index can be enabled alone or with the filterable index. Efficient range filters can be combined with other filters, such as the Equal filter, to quickly narrow your searches to the most relevant information.
Internally, rangeable indexes are implemented as roaring bitmap slices. This is an exciting data structure that combines several clever ideas to reduce memory requirements while improving processing speeds.
This feature is only available for new properties and new collections.
Async Replication
Data consistency is an important consideration for multi-node clusters. Weaviate v1.18 introduces a repair-on-read feature that finds and fixes problems at read time. The current release adds another powerful tool, async replication. Async replication works in the background, checking and updating your data to keep it consistent.
Weaviate uses the Raft algorithm to manage schema replication, while using repair-on-read and async replication to manage object replication.
The async replication mechanism uses an efficient algorithm to monitor and compare nodes within a cluster. If the algorithm identifies an inconsistency, it resyncs the data on the inconsistent node.
Async replication is more effective than repair-on-read when there are many inconsistencies between nodes. If, for example, an offline node misses a series of updates, async replication quickly restores consistency for all of the objects when the node returns to service. Under a repair-on-read approach, the missing updates might not be noticed for a long time.
For details, see async replication.
Anthropic integration
An Anthropic generative AI integration is available in Weaviate. This integration allows you to use the Claude family of models from Anthropic to perform retreval augmented generation on your data. The integration includes support for the latest models, such as Claude 3.5 Sonnet.
The Anthropic integration is enabled by default on Weaviate Cloud WCD instances.
To enable the Anthropic integration on a local deployment, add generative-anthropic to the ENABLE_MODULES environment variable, or set the ENABLE_API_BASED_MODULES environment variable to true.
For details, see the Anthropic integration page.
Bulk enable modules
Experimental This feature is experimental and may change in future releases.
To enable all API-based model provider integrations, set the ENABLE_API_BASED_MODULES environment variable to true.
This means you do not have to enable individual API-based modules in the ENABLE_MODULES environment variable.
ENABLE_API_BASED_MODULES and ENABLE_MODULES are additive. Set ENABLE_API_BASED_MODULES to true to enable API based modules. Use ENABLE_MODULES to configure additional modules such as text2vec-ollama, generative-ollama, and backup-s3.
When ENABLE_API_BASED_MODULES is true, the GraphQL Explore feature is unavailable.
Multi target vector search
Weaviate 1.24 introduced objects with multiple vector embeddings. Each vector may come from a different vectorizer, or be derived using different source properties. This release introduces multi target vector search. Starting in 1.26, you can make a single query that combines results from across multiple target vectors.
When you perform a multi-target vector search, add a list of target vectors to the query instead of a single, named vector. Weaviate automatically combines the results from all of the target search vectors. The mechanism is conceptually similar to the hybrid fusion algorithm in hybrid search.
This allows you to tune your multi vector search to balance the target vectors in a way that reflects your application needs.
For details, see multi target vector search.
Tenant states changed
Tenant activity status is used to manage resource usage.
The old status names change to ACTIVE and INACTIVE in Weaviate 1.26 to better reflect the tenant status. The status definitions are the same as before.
ACTIVEtenants are available for read and write operations.INACTIVEtenants are not available for read or write operations.
In earlier versions, INACTIVE tenants are marked as COLD, and ACTIVE tenants are marked as HOT.
This release also adds a new status, OFFLOADED. (See below.)
Tenant offload to cloud storage
Weaviate 1.26 introduces the ability to offload INACTIVE tenants to cloud storage. This feature gives you the flexibility to store tenants on disk or in cloud storage, which helps you to manage costs. Move INACTIVE tenants to lower-cost cloud storage when they aren't in use, and reload the tenants onto the local device when you need them.
A tenant that is in cloud storage is marked as OFFLOADED and is not available for read or write operations. While the tenant is in process of offloading to cloud storage, its status is OFFLOADING. The tenant's status is ONLOADING while it is reloaded from cloud storage.
Currently, tenant offload is supported for AWS S3 storage. Additional cloud storage providers are coming in future releases.
This feature is only available for self-hosted instances and Weaviate Enterprise Cloud. It is not available for Weaviate Cloud serverless instances.
For details, see tenant activity statuses and the s3-offload module.
Async Python client
The Weaviate Python client library adds a WeaviateAsyncClient object and a new API that supports asynchronous operations. Highly concurrent applications can use the new API for more efficient processing.
For detailed information on the new async client API, see Async API. The async API is very similar to the synchronous client API. The helper methods to connect to the aysnc API are analogous to the sync connection methods:
use_async_with_localuse_async_with_weaviate_clouduse_async_with_custom
For code examples, see async usage examples.
FastAPI is a popular asynchronous web framework for creating modular, web API microservices. For sample application code that uses the async client with FastAPI, see the application example.
Scalar Quantization
This release introduces a new vector compression technique called scalar quantization (SQ). SQ is a powerful technique that reduces the storage space required for each dimension of a vector. In Weaviate, vector dimensions are typically stored using 32 bit floating point numbers. With scalar quantization, each dimension is converted into an 8 bit integer. This transformation effectively cuts the size of vectors by 75% since 8 bit representations only need a quarter of the original 32 bits.
Image color depth is a helpful analogy. An image that has a deep palette uses many bits of information to capture shades of a color. An image with low bit-depth has a more limited number of colors (256 values for 8 bits). The scene is still clearly visible. Even though there may be visual artifacts, the lower bit-depth significantly reduces the storage space required.
Practically speaking, scalar quantization provides a fourfold reduction in vector size with about a 5% loss in retrieval recall. Techniques such as over-fetching and rescoring mitigate the reduction and improve recall.
Scalar quantization offers a compelling trade-off between storage efficiency and retrieval accuracy. This makes SQ an essential tool for optimizing vector storage in Weaviate. Look for more details on SQ and SQ related experiments in a deep dive blog post that's coming soon!
Dashboards for async indexes
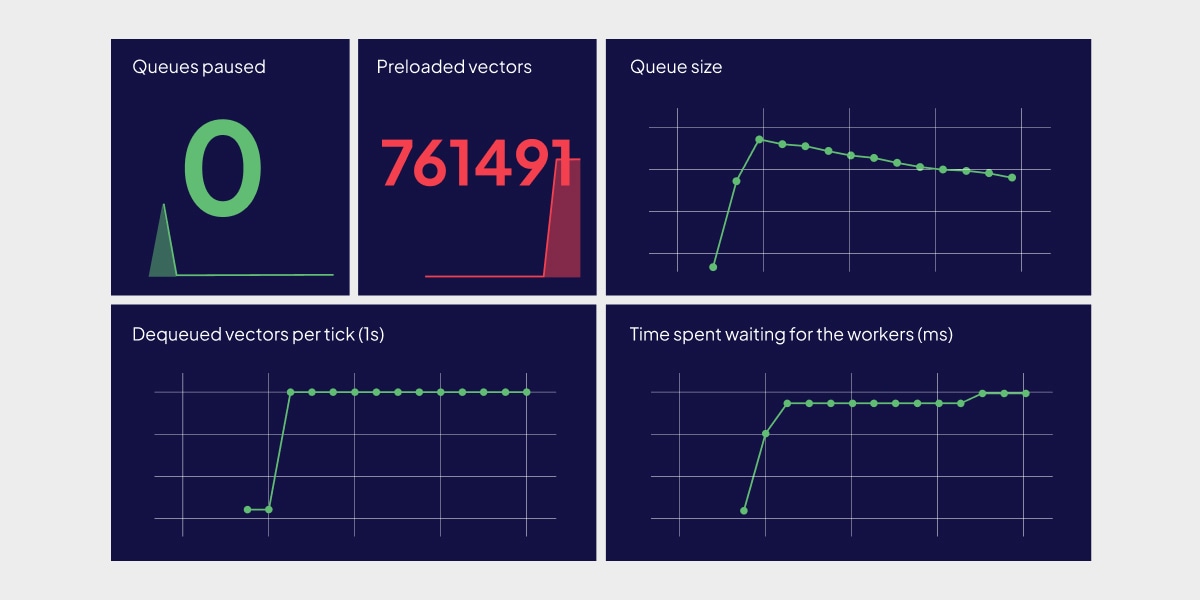
Weaviate can gather metrics that are compatible with the open-source Prometheus monitoring and alerting system. The v1.26 Weaviate release adds new metrics that monitor aysnc indexing queues.
Use these metrics with Prometheus and Grafana to monitor your Weaviate instance.
If you don't see a metric that you need, you can extend Weaviate to add new metrics. To suggest a new metric, or to get started writing your own, see the contributor guide.
Korean tokenizer
Experimental This feature is experimental and may change in future releases.
A new Korean tokenizer is available in Weaviate 1.26 (and 1.25.7). This tokenizer is based on the kagome library and a Korean MeCab dictionary.
To enable the Korean tokenizer, set the ENABLE_TOKENIZER_KAGOME_KR environment variable to true, and set the tokenization method for the relevant properties to kagome_kr.
Additional changes
-
Starting in Helm chart version 17.0.1, constraints on module resources are commented out to improve performance. To constrain resources for specific modules, add the constraints in your
values.yamlfile. -
The HNSW
maxConnectionsvalue is updated. Instead of 64 connections, the HNSW graph now defaults to 32 connections.The lower value works better with modern ANN datasets that have high dimensionality. Testing shows that the QPS/recall curves improve with lower
maxConnectionsvalues. The best values are in the 16-32 range, depending on dataset size. To improve target recall,efcan be increased.
Summary
Enjoy the new features and improvements in Weaviate 1.26. This release is available as a docker image and is coming soon to Weaviate Cloud WCD.
Thanks for reading, see you next time 👋!
Ready to start building?
Check out the Quickstart tutorial, or build amazing apps with a free trial of Weaviate Cloud (WCD).
Don't want to miss another blog post?
Sign up for our bi-weekly newsletter to stay updated!
By submitting, I agree to the Terms of Service and Privacy Policy.