
Weaviate 1.17 release

We are happy to announce the release of Weaviate 1.17, which brings a set of great features, performance improvements, and fixes.
The brief
If you like your content brief and to the point, here is the TL;DR of this release:
- Replication - configure multi-node replication to improve your database resilience and performance
- Hybrid Search - combine dense and sparse vectors to deliver the best of both search methods
- BM25 - search your data with bm25
- Faster Startup and Imports - enjoy Weaviate, that is up and running faster than ever before with more speedy data imports
- Other Improvements and Bug Fixes – enjoy a more stable Weaviate experience, courtesy of fixes and improvements delivered in nine installments since 1.16.0.
Read below to learn more about each of these points in more detail.
Replication
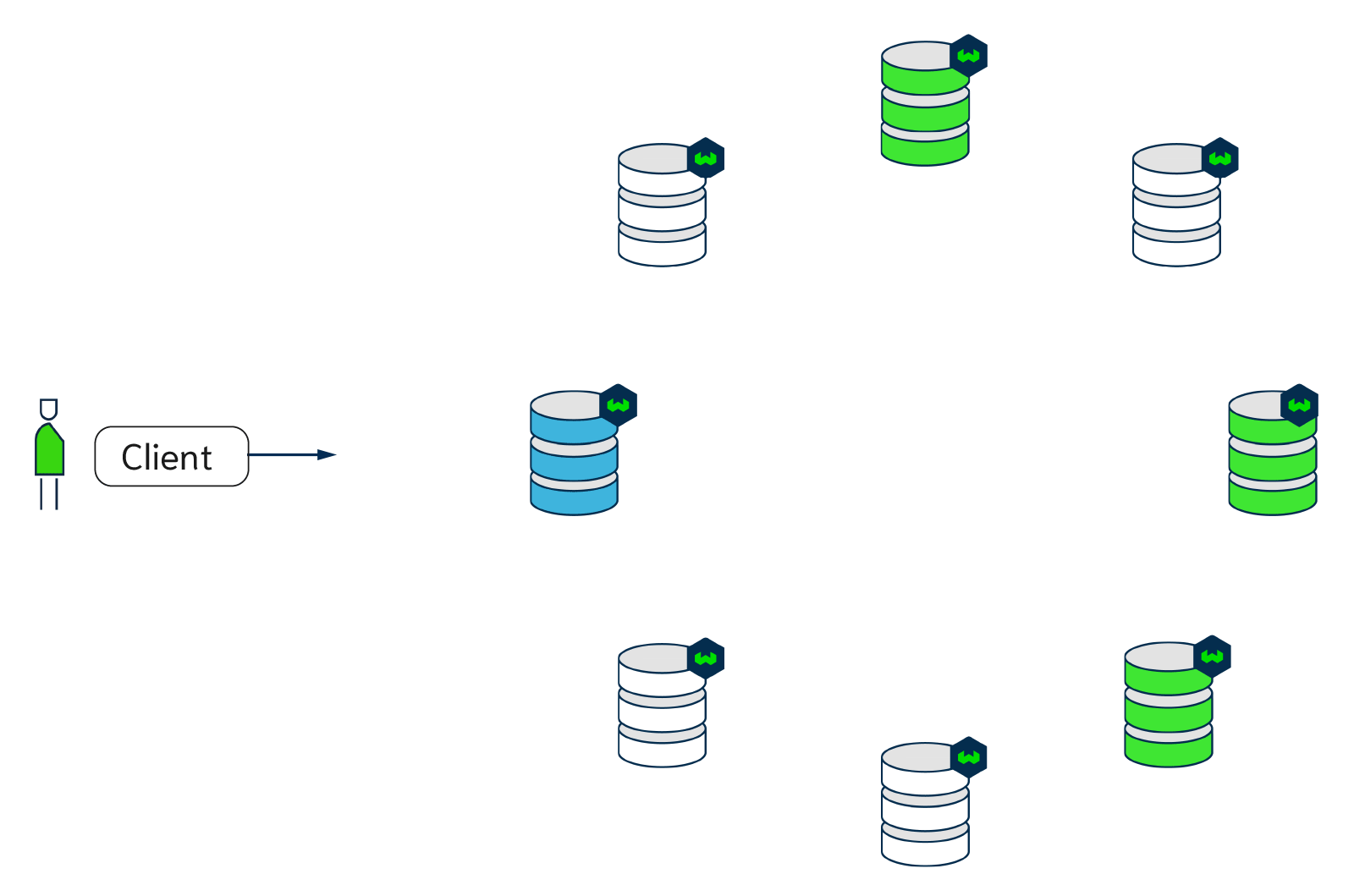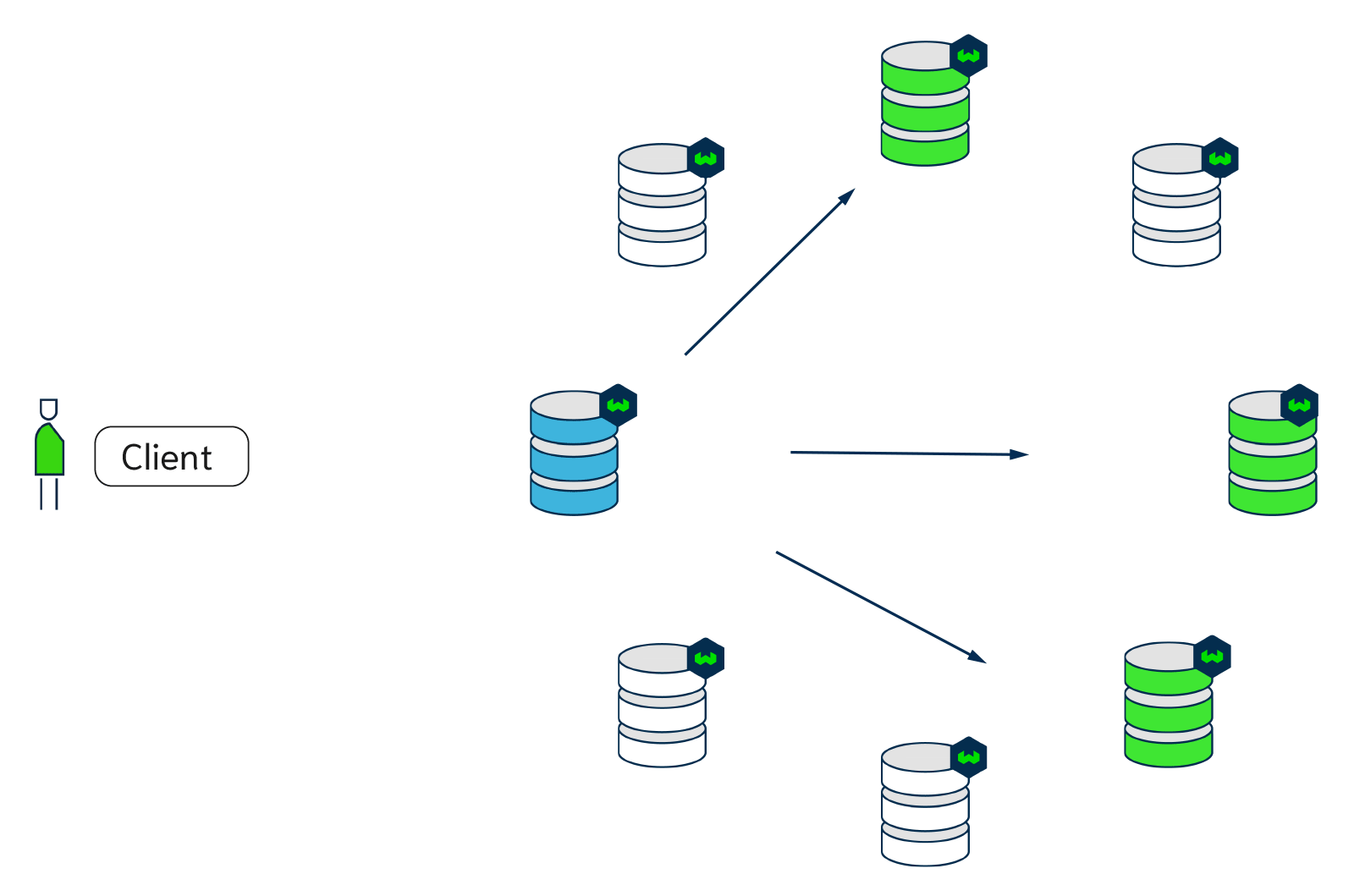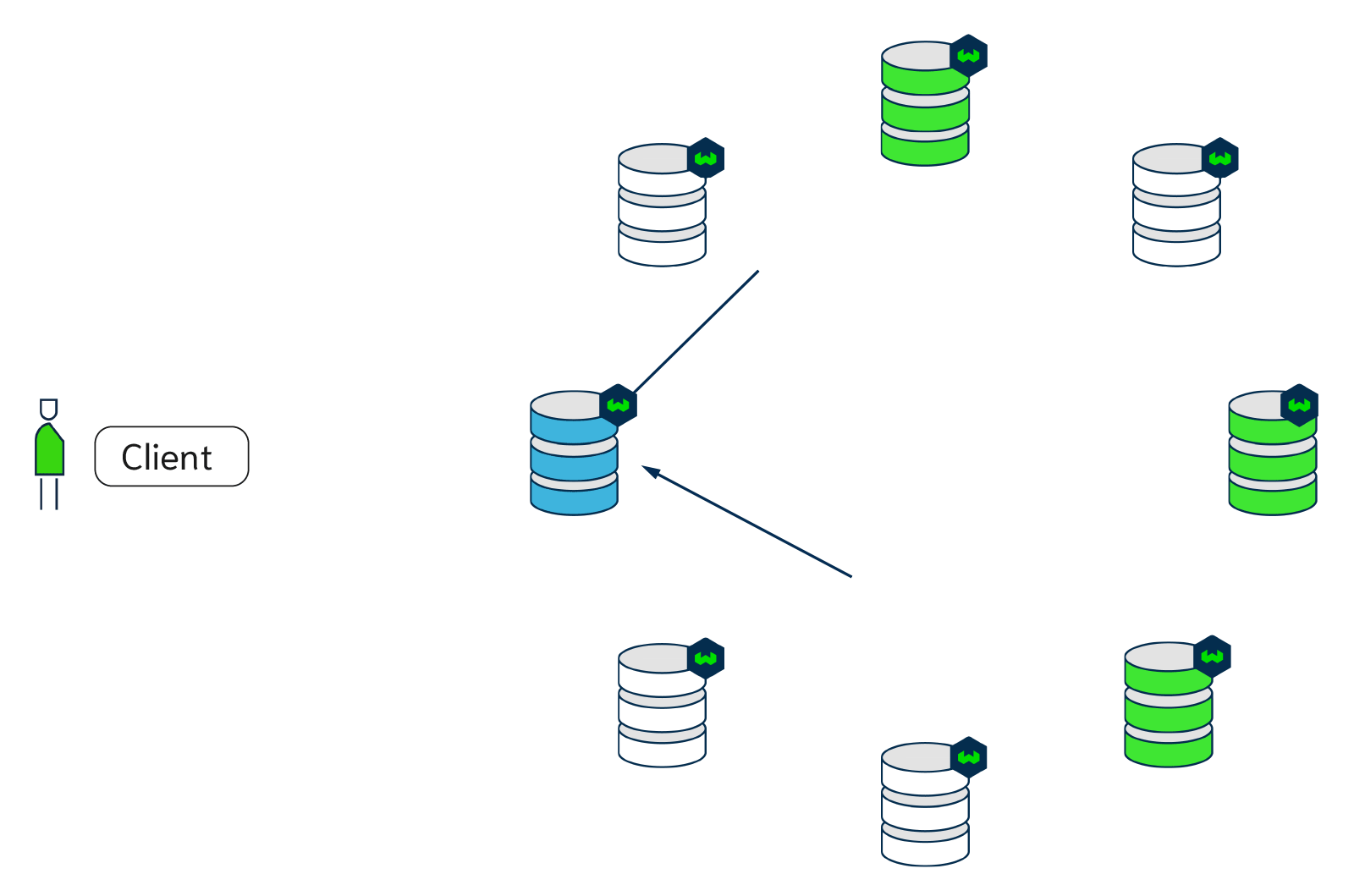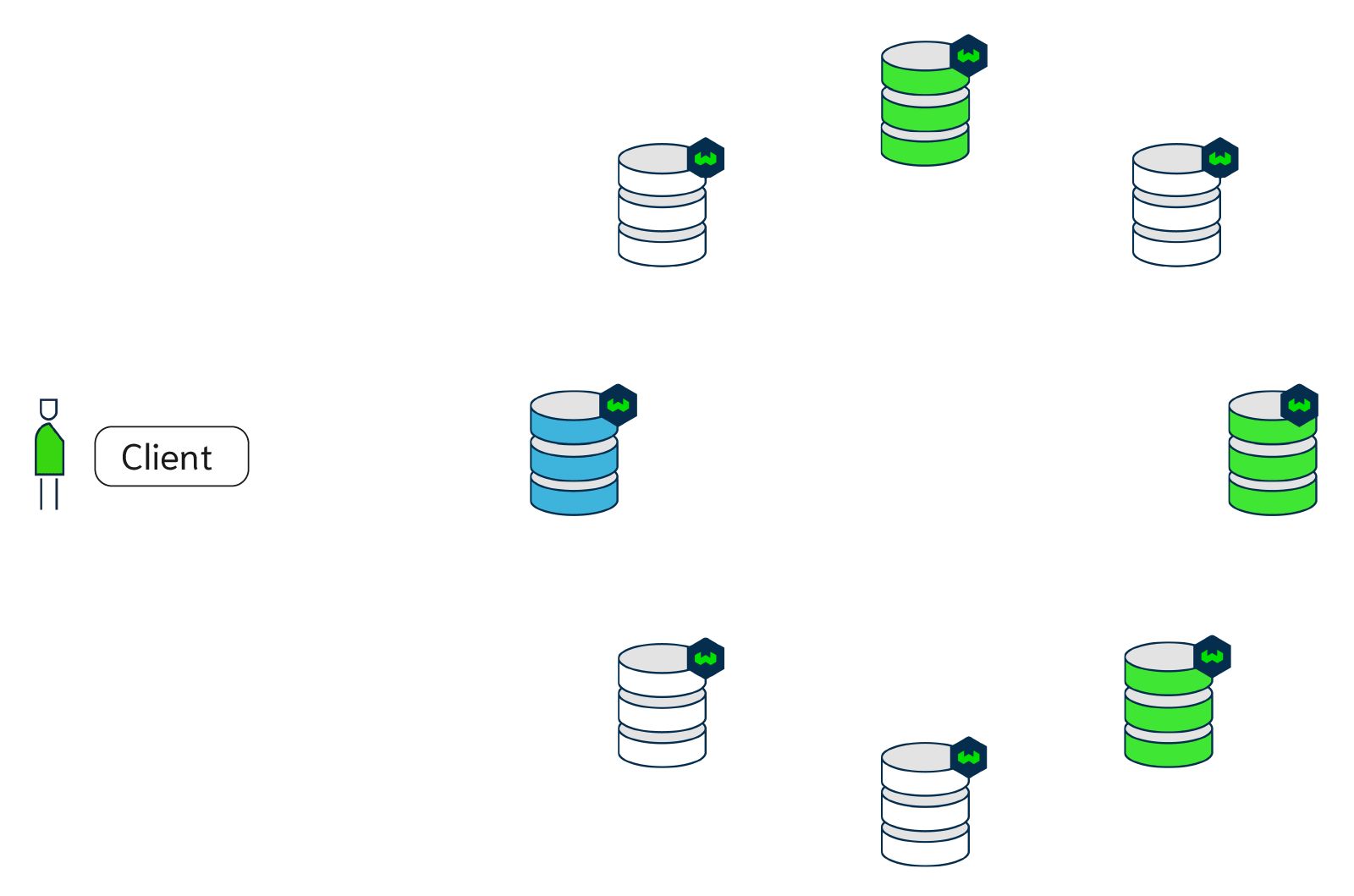
Weaviate's v1.17 release introduces replication. Replication enables you to set up your Weaviate environment in a cluster with multiple server nodes. Weaviate will automatically replicate data across nodes in the background.
Use Cases
This enables a variety of use cases. For example, if a Weaviate node goes down, another node can shoulder the load without losing availability or data. Data in Weaviate will thus have a higher availability for its users.
Secondly, Replication can improve the throughput of read requests, as you can use all additional nodes to spread the load of queries. Adding extra database nodes can serve more users simultaneously.
Thirdly, database replication enables zero downtime upgrades, because only a single node has to stop at a time while other replicas can continue serving.
A final motivation for using database replication is regional proximity. With Multi-DataCenter replication, you can put Weaviate servers in different locations, which can decrease latency for users spread out geographically. The Multi-DataCenter feature is not implemented yet, but we are already working on it.
Replication Design in Weaviate
Replication in Weaviate is modeled after how users typically use Weaviate. Most use cases are very-large-scale, which aim for low latency and high availability.
It is often tolerable if data is temporarily out of sync, as long as consistency is reached eventually. Keeping the CAP Theorem trade-offs in mind, Weaviate's replication architecture prefers availability over consistency.
Nevertheless, both read and write consistency will become fully tunable from v1.18 (read consistency is partly tunable from v1.17).
Weaviate has a leaderless replication design, so there is no distinction between primary and secondary nodes, thereby removing all single points of failures.
Roadmap
With v1.17, the foundations of replication are built into Weaviate. In v1.18 and later releases, more features will be added:
| Weaviate version | Expected release | Feature |
|---|---|---|
v1.17 | Live | * Leaderless Replication * Tunable Read Consistency for Get-by-ID requests |
v1.18 | Feb 2023 | * Tunable Write Consistency * Tunable Read Consistency for all requests * Repairs – Read-Repairs or Background/Async Repairs |
| TBD | TBD | * Multi-Data center replication (upvote it here) |
Learn More
To learn more, visit the documentation pages for Replication Architecture and/or Usage, where all concepts are explained in detail, supported by illustrations!
Hybrid Search

Hybrid search is a search functionality that combines the best features of both keyword-based search algorithms with vector search techniques. In hybrid search, sparse and dense vectors are used to represent the meaning and context of search queries and documents. Sparse embeddings are generated from models like BM25 and SPLADE. Dense embeddings are generated from machine learning models like GloVe and Transformers.
Using both sparse and dense search methods combines the power of keyword matching with contextual semantics. For example, in the query "How to catch an Alaskan Pollock?", the semantic meaning of "catch" is revealed to be related to fishing from the context; this is where dense vectors thrive. Sparse methods on their own would not be able to associate "catch" with fishing any differently from catching a baseball or a cold. On the other hand, sparse methods can capture specific entities such as "Alaskan Pollock". This query illustrates an example where hybrid search combines the best of both sparse and dense vectors.
Hybrid Search Query
Here is an example of how to run a hybrid search query in GraphQL:
{
Get {
Corpus (
hybrid: {
query: "How to catch an Alaskan Pollock?",
alpha: 0.5,
})
{
document
}
}
}
Similar to how you use nearText, hybrid is passed as an argument to a Weaviate class object. hybrid has two parameters: query and alpha. query is fairly straightforward, whereas alpha is a new idea. alpha describes the weighting between dense and sparse search methods. An alpha closer to 0 weighs sparse search more than dense, and an alpha closer to 1 weighs dense search more than sparse. Additionally, if alpha is set to 0, it only uses sparse search, and if alpha equals 1, then it uses dense search only.
What's next in Hybrid
Work on hybrid search is not over! We will continue to make improvements and introduce new features in the future. For example, there is already something in the backlog to add where filters to hybrid search (give it a thumbs up while you're there). 🙂
Learn More
The hybrid operator is available through GraphQL, REST and all Weaviate client languages. Check out the documentation for more information and learn how to write the query in the other client programming languages.
BM25

BM25 ("Best Match #25" - it took quite a few iterations to arrive at the current state of the art 😉) is a family of ranking functions that is widely used in information retrieval to score and rank documents based on their relevance to a given search query.
BM25 Operator
In Weaviate v1.17, we introduce a search operator called bm25, which performs a case-insensitive keyword search, then ranks the results using the BM25F ranking function - Best Match 25 with Extension to Multiple Weighted Fields, a variant of BM25 that can take into account different weights for different properties (fields) of the document, in order to produce more accurate results.
Core Concept
The basic idea behind BM25 is to score a document based on the number of times a particular term appears in the document, as well as the overall length of the document - one occurrence in a tweet is much more significant than one occurrence in a book. Essentially, this is done using a combination of term frequency (TF - the more times the term appears, the higher the score) and inverse document frequency (IDF - if a term occurs rarely in the documents in the corpus, then whenever it does occur, that occurrence is probably significant).
TF-IDF is in fact the name of a ranking function upon which BM25 builds. The idea has been refined to codify numerous information retrieval intuitions such as, if a term appears three times in a document and six times in another, that doesn't automatically mean the second document is twice as relevant.
When to use BM25
BM25 is best used when an exact match for the query keywords is desired (and the order of the words in the query is not important) and in out-of-domain searches (when the model is not specifically trained on the corpus of documents). If stemming or semantic similarity are desired, Weaviate's vector search will be better suited.
BM25 Query Example
The bm25 operator takes one required parameter, a string query, and an optional properties parameter - an array of property names, each of which being optionally weighted by a factor placed after a ^ character.
Here is a GraphQL example using the bm25 argument:
{
Get {
Article(
bm25: {
query: ["fox"],
properties: ["title^2", "url"]
}
) {
title
_additional {
score
}
}
}
}
The response contains the score in the _additional object.
Learn More
The bm25 operator is available through GraphQL, REST and all Weaviate client languages. Check out the documentation for more information.
Faster Startup and Imports

With Weaviate v1.17 come faster startup times as a result of persisting computations on disk that were previously being computed every time at startup. For example the startup time with the Wikipedia dataset has improved from ~5 mins to now ~1min. To dig a little deeper, as a part of the initialization of the LSM store segment we build a bloom filter for the segment, the runtime for which is proportional to the segment size, and we also calculate the "count net additions" (CNAs). Both of these operations which were previously computed every time in-memory during the initialization phase are now persisted on-disk after the first startup allowing for faster subsequent startup times. For more details around this fix please read more here. It's important to note that this change is fully backward compatible, however after upgrading to v1.17 during the first startup the files cannot be read from disk because they don't yet exist. After the first startup they will be persisted on-disk and you should notice speedier subsequent startups.
Adjust Memtable Size Dynamically
Another contributor to the faster startup times in v1.17 is that now the size of the memtable (the in-memory portion of the LSM store) is adjusted dynamically. Previously the memtable was fixed at 10MB and on large clusters with parallel imports this 10MB was inadequate and would act as a bottleneck since it would fill up so quickly that it would constantly need to be flushed. Now, with this change, the memtable starts off at 10MB but can be increased in size every time the last flush duration is less than a specific threshold which allows it to dynamically adjust its capacity over time. You can read more about this change here.
Improve Batch Import Latency
We also introduced a series of fixes as a result of which you'll see fewer latency spikes when importing large datasets. The main problem here was that when importing large datasets over time compactions would take longer and longer which ended up blocking the import. Due to this, previously some batches could block for minutes on very large imports. You can read all about the fixes in detail here.
In summary, the main benefits you should see as a result of all the changes above in v1.17 are faster startup times with speedier imports and less latency spikes.
Other Improvements and Bug Fixes

There haven't been any new fixes that are exclusive to v1.17. However, there have been six patch releases between v1.16 and v1.17, below we highlight the fixes contained in those patches:
- Fix filters with len() in path in #2340
- Fix concurrent Write / Read Performance Regression (introduced in v1.16.0) in #2352
- Fix SEGFAULT error (a race between reads and compaction) in #2349
- Fix "stuck API" (deadlock situation) in #2349
- Fix another potential SEGFAULT issue during compactions in #2363
- Fix length and null state filtering for empty arrays in #2367
- Prevent IndexNullState and IndexPropertyLength to be updated in #2368
- Remove obsolete invertedIndexConfig.cleanupIntervalSeconds in #2376
- Self-Service Docker Images in #2369
- Adjusts batch size to decrease test execution time in #2372
- Update Dependencies to fix known vulnerabilities in #2378
- Provide alternative to OpenAI deprecation of "Answers" endpoint through qna-openai module in #2346
- Skips re-vectorize objects on PATCH if not necessary in #2383
- Fix potential deadlock by releasing the index lock in case of error in #240
- Additional tokenization tests in #2339
- Fix group with nearVector in #2423
- Improve defaults for DefaultCohereModel and DefaultTruncate in #243
For a more detailed breakdown of the fixes please see the release notes: v1.16.1, v1.16.2, v1.16.3, v1.16.4, v1.16.5, v1.16.6, v1.16.7.
Enjoy
We hope you enjoy all the new features, new operators, performance improvements, and bug fixes that made this the best Weaviate release yet!🔥