

We are happy to announce the release of Weaviate 1.18, which brings a set of great features, performance improvements, and fixes.
The Brief
If you like your content brief and to the point, here is the TL;DR of this release:
- Faster Filtering with Roaring Bitmaps – modern data structure that dramatically boosts the speed for filtered searches
- HNSW-PQ – enables great performance at a fraction of the previous RAM requirements
- Improvements to BM25 and Hybrid Search – faster scoring with the WAND implementation and added filter support
- Replication – two new replication features: tunable consistency for all read and write REST operations, and repair on read
- Cursor API – simple way to export every object from Weaviate
- Azure Storage backup module – extends our cloud-native backup capabilities further by introducing the
backup-azuremodule.
Read below to learn more about each of these points in more detail.
Faster Filtering with Roaring Bitmaps

This release introduces a compact, modern data structure to Weaviate called “Roaring bitmaps” that will replace the internals of the inverted index. The new Roaring bitmap indexing dramatically speeds up filtered searches, and we’ve seen it provide up to 1000(!) times faster performance in some cases.
Motivation
At Weaviate, we've been on a journey to keep up with the growing needs of our users. As more and more vectors are added to Weaviate instances, the "allow list" of pre-filtered items can reach tens, or hundreds of millions of objects. This can result in long retrieval times that are far from ideal from a user perspective. The introduction of Roaring Bitmaps is another step that will help us and our users scale to the next level.
Roaringly fast filtering
With the introduction of the natively-implemented RoaringSet data type in 1.18, speeds will be dramatically improved, especially for large allow lists. In our internal testing, we've seen queries that used to take 3-4 seconds execute in just 3-4 milliseconds.
The extra efficiencies are due to various strategies that Roaring Bitmaps employ, where it divides data into chunks and applies an appropriate storage strategy to each one. This enables high data compression and set operations speeds, resulting in much improved filtering speeds for Weaviate.
Weaviate version 1.18 and onwards will include this feature, and our team will be maintaining our underlying Roaring Bitmap library to address any issues and make improvements as needed. To read more about pre-filtering read the documentation here
What this means for you
From your perspective, the only visible change will be the a one-time process to create the new index. Once your Weaviate instance creates the Roaring Bitmap index, it will operate in the background to speed up your work.
We note that the current implementation is not yet applicable to filtering text and string data types, which is an area that we aim to tackle in the future.
If you are already dealing with a large dataset, this will likely improve your performance significantly. And if you are dealing with a growing dataset, you can be assured that Weaviate will stay performant even as your dataset grows.
HNSW-PQ

Weaviate is a very performant and robust vector database but it does require RAM to perform well and with 1.18 we are introducing a new feature that aims to give users the same performance they have come to expect from Weaviate but at a fraction of the previous RAM requirements! Currently, the two big RAM costs of Weaviate come, firstly, from needing to store neighborhood graphs which allow us to conduct approximate nearest neighbors search algorithms like HNSW, and secondly from having to store the entire vectors themselves in memory.
Introduction of Product Quantization
With Weaviate 1.18 we are alleviating these high RAM requirements by now allowing users to keep a compressed representation of the vectors in memory. This allows users to maintain a similar performance but at a fraction of the RAM requirements of previous versions.
More specifically, in 1.18 we implemented the solution proposed in DiskANN whereby we combined our HNSW indexing with vectors that have been compressed using product quantization (PQ). PQ is a lossy compression algorithm that allows us to significantly reduce vector representation size at the cost of a bit of recall. But how does it actually work, you ask !?
How does PQ work?

To understand how PQ compression works, imagine every vector you want to store is a unique house address. A unique house address allows you to precisely locate where someone lives including country, state, neighborhood, street number, and even the house number details. The price you pay for this pin-point accuracy is that each address takes up more storage space. Now, imagine instead of storing a unique address for each house we store just the neighborhood name the house is located in. With this representation, you can no longer precisely differentiate between houses that are all in the same neighborhood but you know approximately where the houses are. The advantage however is that you require less memory to store the neighborhood data - this is why it’s a lossy algorithm, we lose information as a result of the compression. You trade accuracy for storage space. Want to save more space? Zoom out further and represent each house instead with the state it’s located in. Require more recall? Zoom in and represent the address on a more accurate scale.
Similarly in PQ compression instead of storing the exact vectors, we replace them in memory with a code that represents the general region in which the vector can be found. Now imagine you conduct this compression for millions or even billions of vectors and the memory savings become quite significant. Using these PQ compressed vectors stored in RAM we now start our search from our root graph quickly conducting broad searches over PQ compressed vector representations to filter out the best nearest neighbor candidates in memory and then drill down by exploring these best candidates when needed. Read more about HNSW+PQ in the documentation here. If you want to learn how to configure Weaviate to use PQ refer to the docs here.
Improvements to BM25 and Hybrid Search

In Weaviate 1.17 we introduced BM25, which was great for small to medium-scale use cases. However, the initial implementation was not optimal for large-scale use cases due to high query-time latencies. We have identified and implemented a solution to this problem, the WAND algorithm!
The WAND algorithm reduces the number of required distance calculations when running a BM25 query. In short, the algorithm retrieves the best top-k scoring documents without scoring all documents. This dramatically improves latency time for BM25 queries in large-scale use cases.
To use WAND for your application, upgrade your Weaviate instance to 1.18. No other changes are necessary for you to see the speed up.
Filters for BM25 and Hybrid Search
The where filter allows you to narrow down your data based on specified conditions. Search operators are applied to GraphQL queries on the class level. We have added where filters to BM25 and hybrid search!
The implementation is the same as how you would add a filter to any other search operator. To begin using filters with BM25 and hybrid, simply upgrade your Weaviate instance to 1.18.
An example of adding a filter to your hybrid search looks like this:
{
Get {
Article (
hybrid: { query: "How to catch an Alaskan Pollock" }
where: { path: ["wordCount"], operator: LessThan, valueInt: 1000 }
){
title
}
}
}
Check out the documentation for more information on how to add filters to BM25 and hybrid.
Stopword Removal
In 1.17, stopwords were not indexed, which led to zero results if you were searching for "the" or “us.” Now with 1.18, stopwords are indexed, but are skipped in BM25. Meaning, stopwords are included in the inverted index, but when the BM25 algorithm is applied, they are not considered for relevance ranking.
For example, take the query: "Where is the nearest fast food chain?" This query has the following stopwords: [“where”, “is”, “the”]. The query is then treated the same as: "Nearest fast food chain".
Stopwords can now be configured at runtime, whereas previously this could only be done at import time. You can update your class after your data has been indexed by using the RESTful API.
Below is an example request for updating the list of stopwords:
import weaviate
client = weaviate.Client("http://localhost:8080")
class_obj = {
"invertedIndexConfig": {
"stopwords": {
"preset": "en",
"additions": ["where", "is", "the"]
}
}
}
client.schema.update_config("Article", class_obj)
For more information on how to update a class using the RESTful API, check out the documentation.
Ongoing Fixes and Improvements
Although BM25 and Hybrid Search were released in Weaviate 1.17, we continued to make fixes and improvements. Here are a list of the patch releases related to BM25/Hybrid:
1.17.1:- Fix BM25/Hybrid over-fetching issue
- This patch corrected hybrid search from returning too many results
- Fix BM25/Hybrid over-fetching issue
1.17.2:- Resolve hybrid search cross-references
- Enhance the
Get{ }query hybrid searches by resolving the cross-references found in the result set.
- Enhance the
- Use different tokenization for text and string
- This patch ensures the correct tokenization is used for each property
- Resolve hybrid search cross-references
1.17.4:- Fixes searching in multi-node setups where sometimes empty results were returned.
- Fixes wrong scores when one of the searched properties was empty.
For more detailed information on the patch releases, you can check out the release notes for 1.17.1, 1.17.2, and 1.17.4.
Replication

Weaviate version 1.18 introduces two new replication features: tunable consistency for all read and write REST endpoints, and repair-on-read.
Tunable consistency
As a distributed database subject to the CAP theorem, Weaviate favors availability over consistency for data, and is strictly consistent when it comes to schema operations. Tunable consistency allows you to decide between three levels of consistency vs. availability:
ONE- reads/writes return the result from the first node that respondsQUORUM- reads/writes succeed after a majority of nodes (replication_factor/2 + 1) respondALL- all replicas must respond
Depending on the desired tradeoff between consistency and speed, below are three common consistency level pairings for write / read operations. These are minimum requirements that guarantee eventually consistent data:
QUORUM/QUORUM=> balanced write and read latencyONE/ALL=> fast write and slow read (optimized for write)ALL/ONE=> slow write and fast read (optimized for read)
Read operations with the consistency level set to QUORUM or ALL return the most recent objects out of those returned by the majority of nodes, based on timestamps.
Version 1.17 supported tunable consistency for fetching by id. Weaviate 1.18 adds tunable consistency support for all read and write REST operations, including batching and cross-references. GraphQL queries do not support tunable consistency yet.
This version also ships with an optimization for fetching multiple objects: the coordinator node only waits to receive a full result set from one of the nodes, and verifies it has the correct objects using digest responses sent by the other nodes. Since Weaviate uses a leaderless setup, the coordinator itself sends a response, which most often will arrive before the full responses sent by the other nodes, but the digests will confirm it is the correct result set.
Repair-on-read
Weaviate 1.18 introduces a repair-on-read feature that uses the "last write wins" policy for conflict resolution.
When the replication coordinator node receives different versions of objects for a read request from the nodes in the replica set, that means that at least one node has old (stale) objects. The repair-on-read feature means that the coordinator node will update the affected node(s) with the latest version of the object(s). If a node was lacking an object entirely (e.g. because a create request was only handled by a subset of the nodes due to a network partition), the object will be replicated on that node.
Consider a scenario in which a request to delete objects was only handled by a subset of nodes in the replica set. On the next read that involves such a deleted object, the replication coordinator may determine that some nodes are missing that object - i.e. it doesn’t exist on all replicas. v1.18 introduces changes that enable the replication coordinator to determine the reason why an object was not found (i.e. it was deleted, or it never existed), along with the object itself. Thus, the coordinator can determine if the object:
never existed in the first place (so it should be propagated to the other nodes), or
was deleted from some replicas but still exists on others. In this latter case, the coordinator returns an error because it doesn’t know if the object has been created again after it was deleted, which would lead to propagating the deletion to cause data loss.
Cursor API
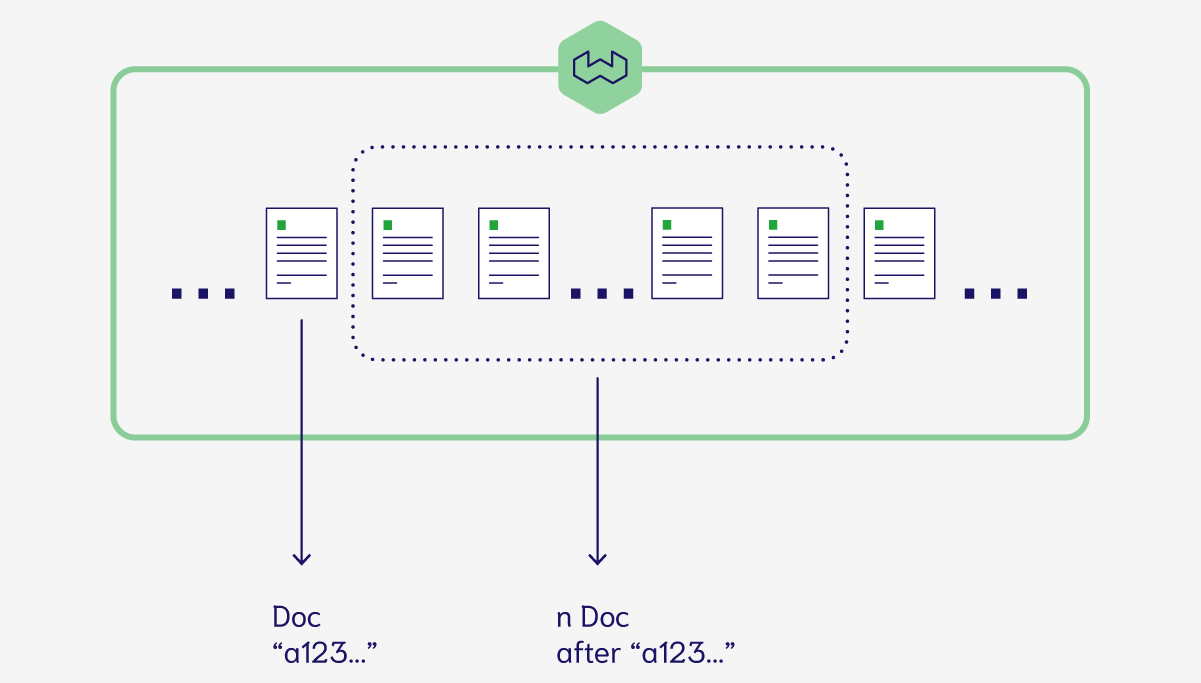
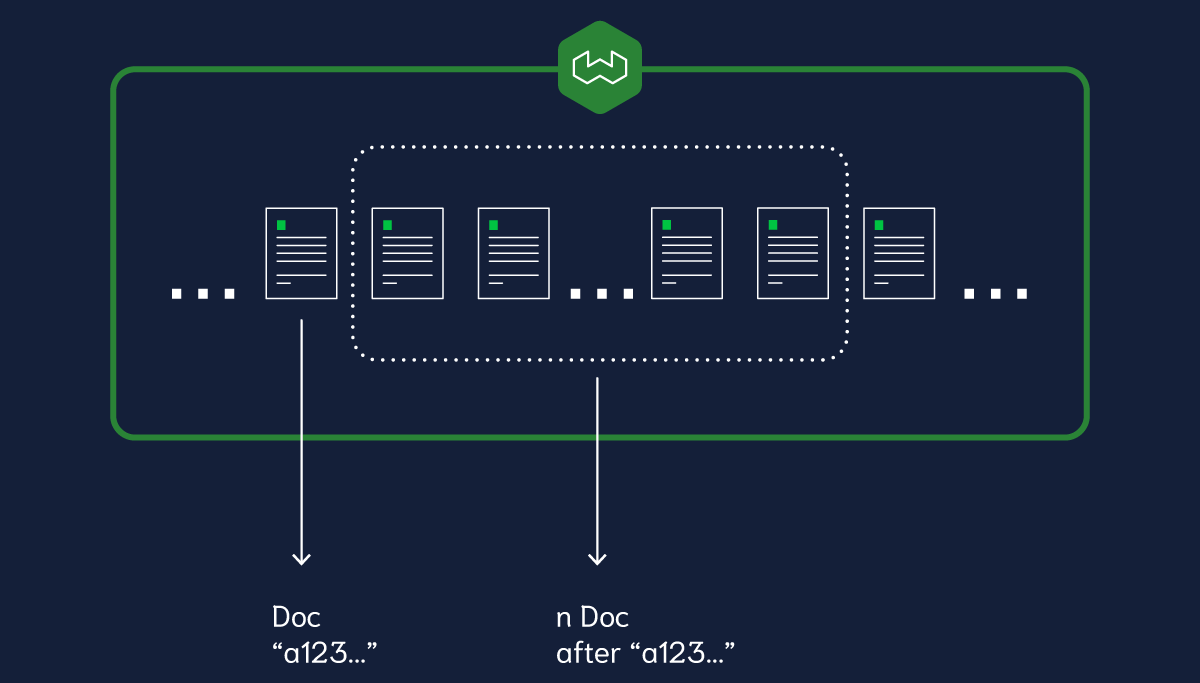
We have added an object ID-based after cursor to both the REST and GraphQL APIs in this release. This enhancement makes it easy for you to systematically retrieve all objects in a class from Weaviate.
How to use
To use cursors with the objects REST endpoint, provide an object uuid via the after parameter in the GET request. The syntax looks like this:
<WEAVIATE_INSTANCE>/v1/objects?class=<CLASS_NAME>&limit=<N_OBJECTS>&after=<UUID>
Where:
<WEAVIATE_INSTANCE>is the Weaviate URL (e.g.https://yoursandbox.weaviate.io),<CLASS_NAME>is the class (e.g.Article) being retrieved (this MUST be set),<N_OBJECTS>is the number of objects to be retrieved in that request, and<UUID>is the last object ID retrieved (e.g.f81bfe5e-16ba-4615-a516-46c2ae2e5a80) (optional; without it, the results will be from the first object).
Or, you can use the cursor API with the GET function in a GraphQL query.
{
Get {
<CLASS_NAME>(
after: "<UUID>",
limit: <N_OBJECTS>,
) {
<PROPERTIES>
}
}
}
All parameters here are the same as in the above REST request example, and the only additional parameter is <PROPERTIES> to specify the properties to be retrieved.
Notes
- The
aftercursor relies on the order of object IDs as stored in Weaviate. Accordingly, it is not applicable to any queries involving a search or a filter. In other words, if the query involves operators such aswhere,near<Media>,bm25,hybrid, etc.,aftercannot be used. You should use theoffsetparameter for these. - The
aftercursor cannot be used in conjunction withoffset. - The
aftercursor is available on both single-shard and multi-shard set-ups.
Learn about the Cursor API in the documentation.
Azure Storage backup module

This releases extends our cloud-native backup capabilities (added in the 1.15 release) further by introducing the backup-azure module.
Backup options
Now Weaviate users can enjoy even more choice for cloud-native backup providers with Azure Storage joining the ranks of S3-compatible storage as well as Google Cloud Storage. This new module will be especially convenient for our users who are in the Azure ecosystem already.
Supported authentication methods
The module supports Azure’s Storage Connections strings, as well as name-and-key based authentication into the storage box. Please refer to our documentation here for information on how to configure it.
Enjoy
We hope you enjoy the replication features, the Cursor API, the Azure module, the performance improvements, and the fixes that made this the best Weaviate release yet!🔥
Ready to start building?
Check out the Quickstart tutorial, or build amazing apps with a free trial of Weaviate Cloud (WCD).
Don't want to miss another blog post?
Sign up for our bi-weekly newsletter to stay updated!
By submitting, I agree to the Terms of Service and Privacy Policy.