
Weaviate 1.23 is here!
Here are the release ⭐️highlights⭐️ relating to this release:

- AutoPQ - Weaviate now automatically triggers the use of Product Quantization (PQ) for vector indexing. This improves the developer experience for switching on PQ. We've also added auto
segmentsize setting. - Flat vector index + Binary Quantization - New index type for small collections, such as for multi-tenancy use cases.
generative-anyscale- Adds open-source large language model integration.- Performance improvements - Mean time to recovery (MMTR) is reduced and automatic resource limiting prevents out-of-memory errors.
- Python client beta update - Adds
1.23support and new features. - Minor changes - The
nodesendpoint adds a newminimaloutput default.
1.23 is already available on Weaviate Cloud - so try it out!
For more details, keep scrolling ⬇️!
AutoPQ
Weaviate introduced Product Quantization (PQ) earlier this year. Since then, we've improved how PQ works with your data. In v1.23 we've made it easier to get started. PQ requires a training step. We've heard that the training step was tricky to configure, so we created AutoPQ to take care of the training for you. Just enable AutoPQ in your system configuration. Then, any time you enable PQ on a new collection, AutoPQ takes care of training and initializes PQ for you.
We have other improvements too. PQ uses segments to compress vectors. In this release we have a new algorithm to determine the optimal segment size for your vectors. You can still set the segment size manually, but you shouldn't have to.
Together, AutoPQ and improved segment sizing make using PQ easier than ever.
Flat vector index + Binary Quantization
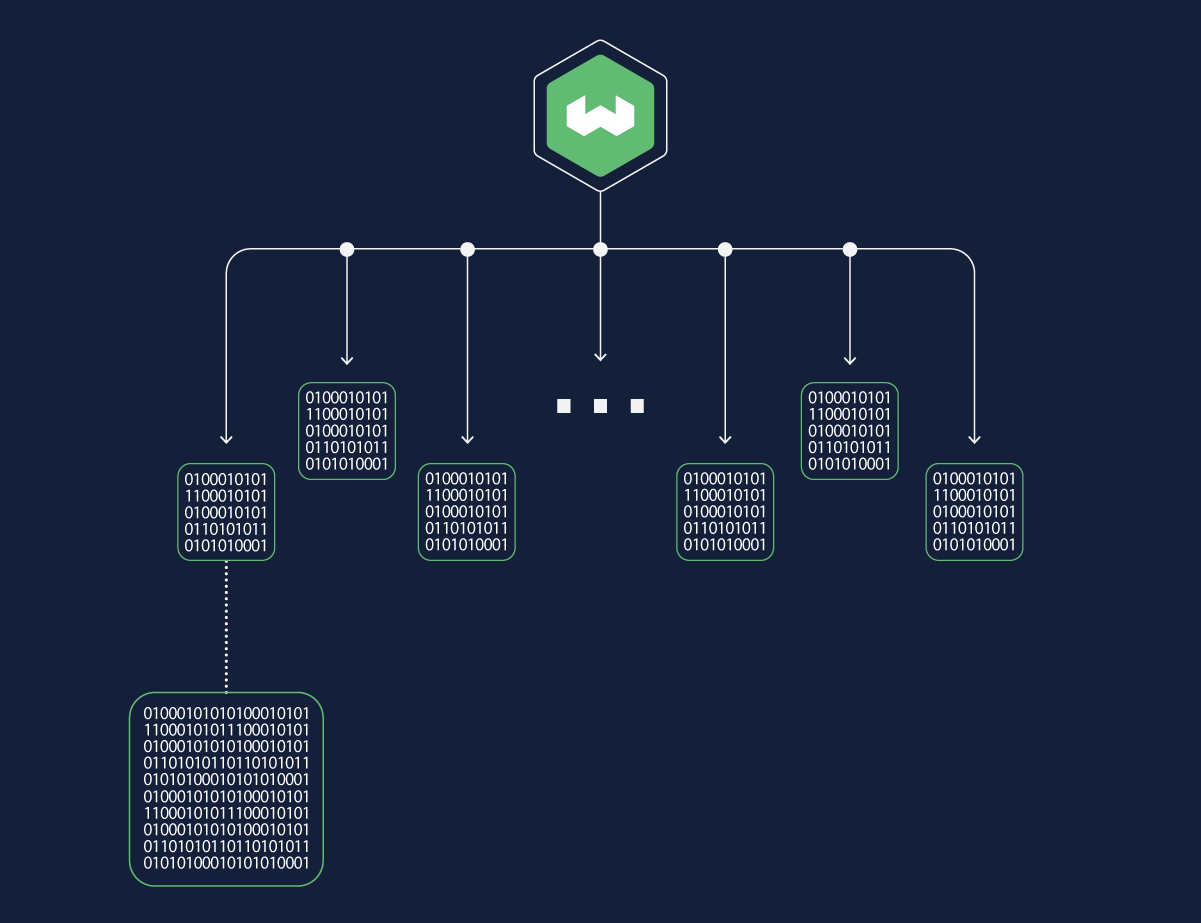
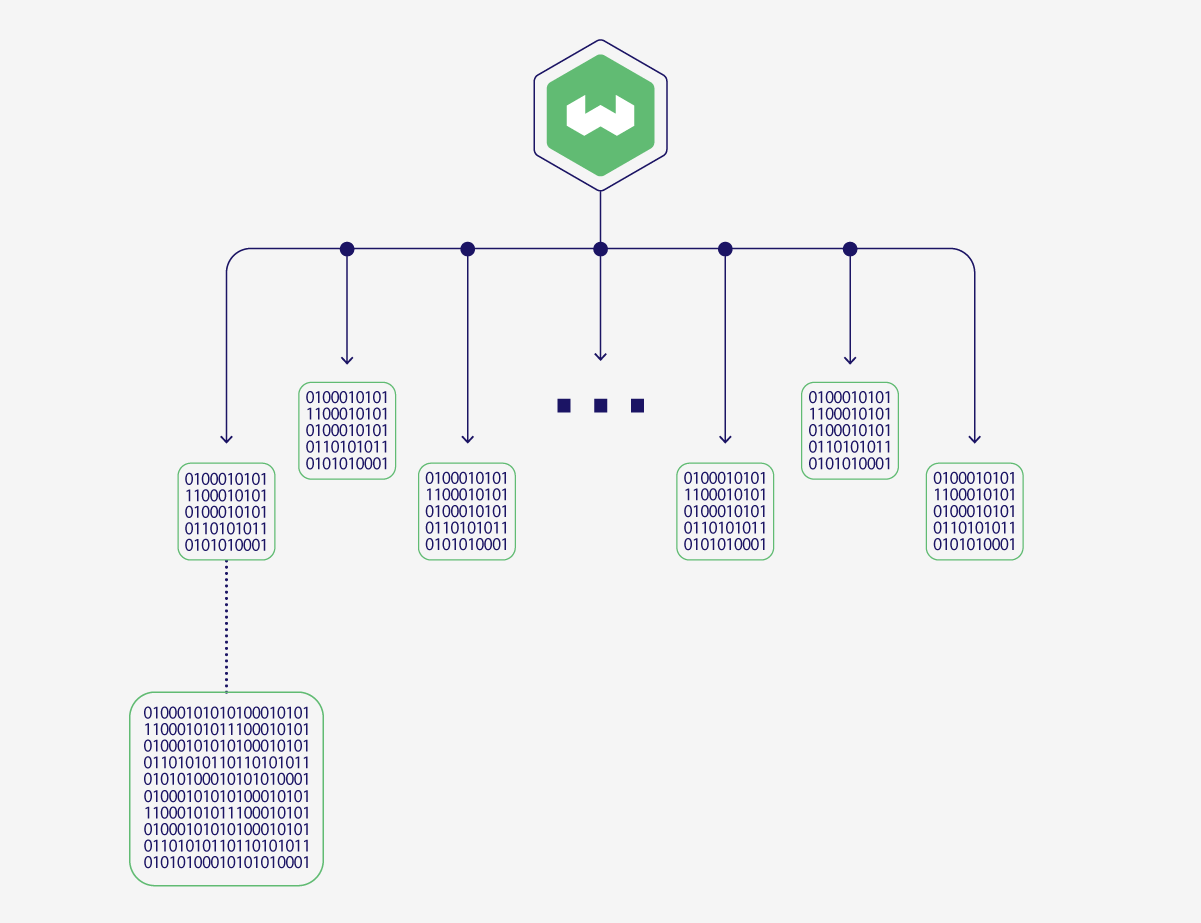
Weaviate now supports a flat vector index type in addition to the existing hnsw index.
As the name suggests, the flat index is a single layer of disk-based references to the object vectors. It therefore has a correspondingly small size and minimal memory footprint.
This index type is particularly useful for multi-tenancy use cases, where each tenant's collection is relatively small, and thus does not need the overhead that comes with building hnsw indexes.
The flat index can be optionally combined with binary quantization (BQ).
Binary quantization
Binary quantization (BQ) compression is available for the flat index type to speed up vector search.
BQ works by converting each vector to a binary representation, such as consisting of N dimensions of signs. This binary representation is then used for distance calculations, instead of the original vector.
Weaviate deals with any loss in vector similarity accuracy by conditionally over-fetching and then re-scoring the results. Anecdotally, we have seen encouraging recall with Cohere's V3 models (e.g. embed-multilingual-v3.0 or embed-english-v3.0), and OpenAI's ada-002 model with BQ enabled.
We expect that BQ will generally work better for vectors with higher dimensions. We advise you to test BQ with your own data and preferred vectorizer to determine if it is suitable for your use case.
When BQ is enabled, a vector cache can be used to improve query performance by storing the quantized vectors of the most recently used data objects. Note that it must be balanced with memory usage considerations.
- Read more about the
flatindex here.
OSS LLM integration with generative-anyscale

With the 1.23 release, it is easier to use Weaviate with many open-source large language models (LLMs) such as Llama2-70b, CodeLlama-34b or Mistral-7B-Instruct. This is made possible by the generative-anyscale module.
This module integrates Weaviate with the Anyscale service, which provides a hosted inference service for large language models. This allows Weaviate users to perform retrieval augmented generation (RAG) with open-source LLMs, without having to worry about the infrastructure required to run these models.
Currently, these models are supported:
meta-llama/Llama-2-70b-chat-hfmeta-llama/Llama-2-13b-chat-hfmeta-llama/Llama-2-7b-chat-hfcodellama/CodeLlama-34b-Instruct-hfmistralai/Mistral-7B-Instruct-v0.1mistralai/Mixtral-8x7B-Instruct-v0.1
If you have used any of the other generative modules in Weaviate, the usage pattern is identical. Make sure you supply your Anyscale API key to Weaviate, and enjoy using these models!
- Read more about the
generative-anyscalemodule here.
Python client beta update
The Weaviate Python client has been updated to support the new 1.23 features. This release also includes additional syntax changes to make the client more intuitive.
This 4.4b3 beta release is designed to be used with Weaviate 1.23. The nature of gRPC means that many changes are coupled between the server and the client. If you upgrade Weaviate to 1.23, please also update the Python client to use them together.
Some of the changes in this release include:
metadatabased filtering was added.Raw GraphQL queries can be performed through
client.graphql_raw_query().Backups for individual collections (
client.collection.backup) or the entire instance (client.backup).referencesare their own parameters inputs where applicable, and returned under their own attributes. For example:- The
client.collections.createfunction includes areferencesparameter. - Returned query results include a
referencesattribute where cross-references were queried.
- The
Native
datetimeobjects are used where applicable, such as for time-basedmetadataattributes or date properties.Read more about the
Pythonclientv4here.
Performance improvements
Lazy shard loading allows you to start working with your data sooner. After a restart, shards load in the background. If the shard you want to query is already loaded, you can get your results right away. If the shard is not loaded yet, Weaviate prioritizes loading that shard and returns a response when it is ready.
You can now enable an option to auto-limit available resources in Weaviate. In applicable systems, you can set the
LIMIT_RESOURCESenvironment variable.
Minor changes
The nodes endpoint can be used to output information about the nodes in your cluster.
This endpoint has been updated with a new output parameter that has a minimal default. This is useful for those of you with many shards or tenants, as it reduces the amount of data returned by the endpoint.
Summary
That's all from us - we hope you enjoy the new features and improvements in Weaviate 1.23. This release is already available on WCD. So you can try it out yourself on a free sandbox, or by upgrading!
Thanks for reading, and see you next time 👋!
Ready to start building?
Check out the Quickstart tutorial, or build amazing apps with a free trial of Weaviate Cloud (WCD).
Don't want to miss another blog post?
Sign up for our bi-weekly newsletter to stay updated!
By submitting, I agree to the Terms of Service and Privacy Policy.