Context Engineering - LLM Memory and Retrieval for AI Agents
· 22 min read
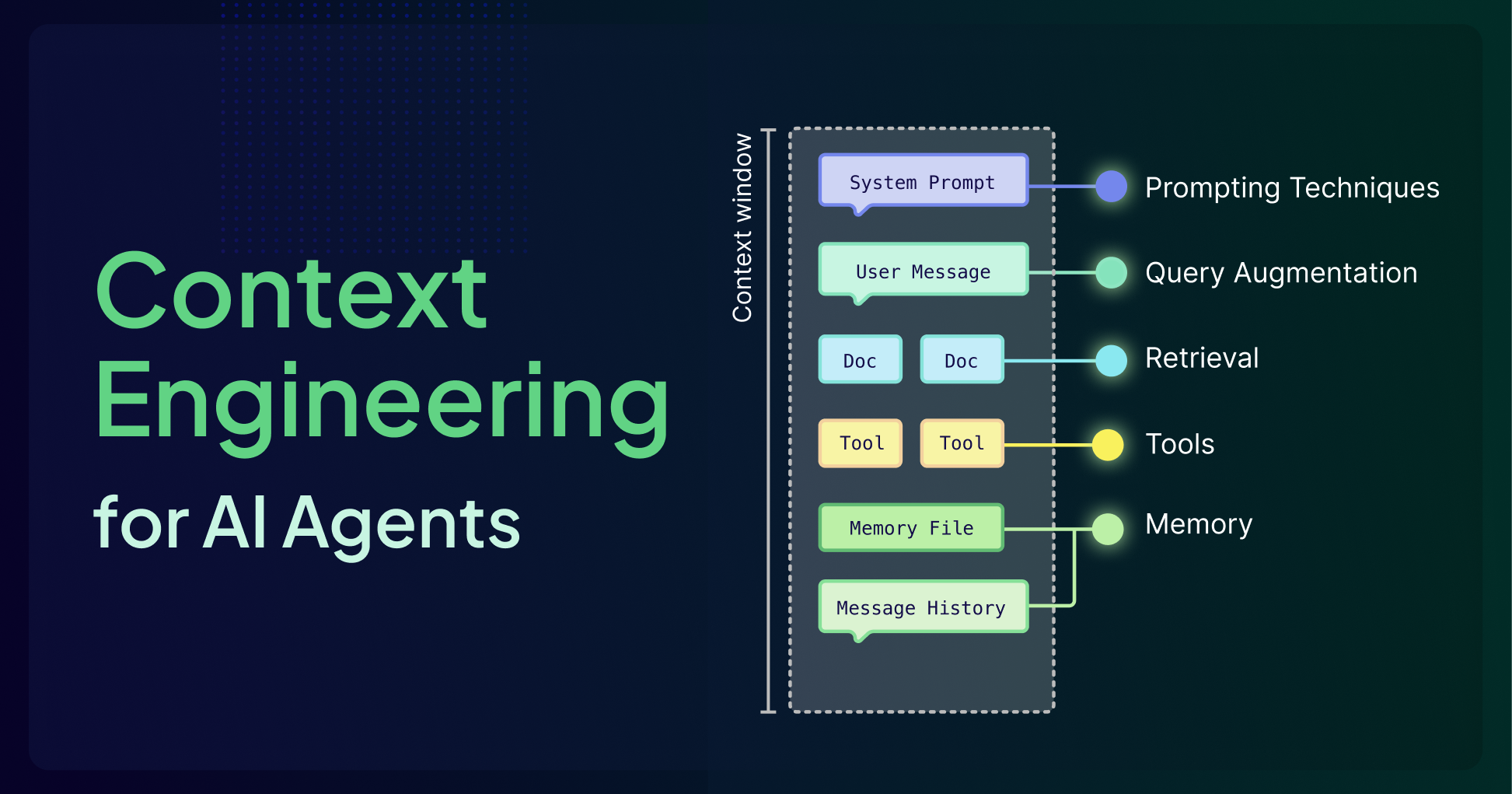
Context Engineering - LLM Memory and Retrieval for AI Agents
Context engineering is how AI agents manage LLM memory—selecting, retrieving, and organizing context from short-term and long-term memory to improve reliability in production.
· 21 min read