Introduction to LLM RAG - Retrieval Augmented Generation Explained
· 19 min read
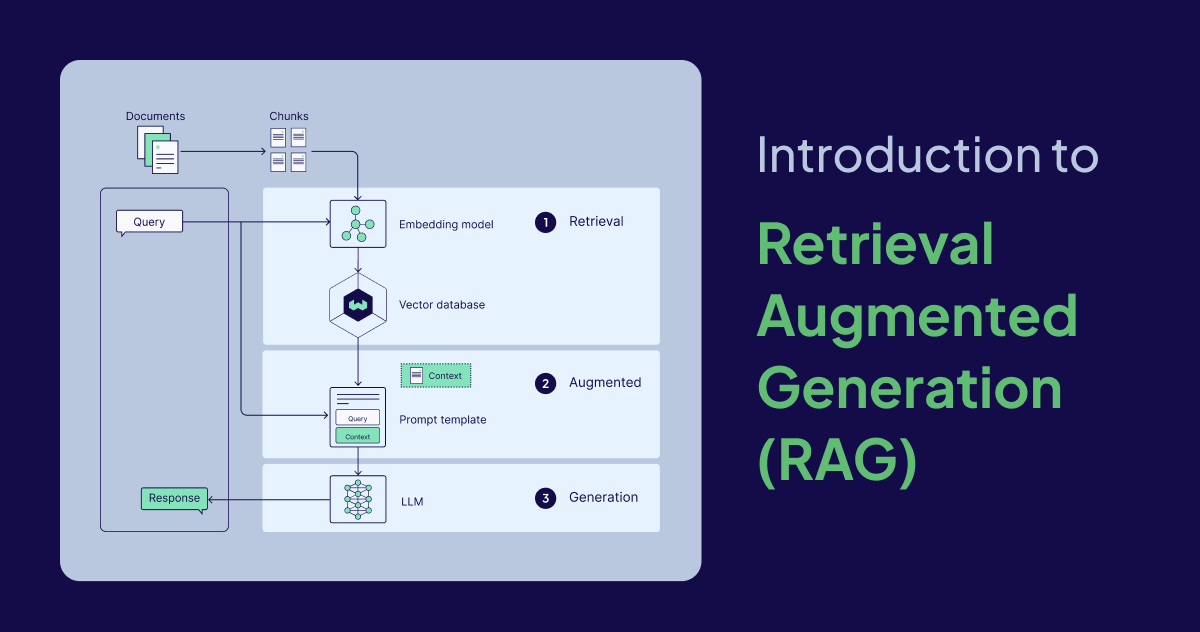
Introduction to LLM RAG - Retrieval Augmented Generation Explained
Learn what LLM RAG (Retrieval Augmented Generation) is, how RAG pipelines work, key use cases, implementation approaches, and evaluation methods.
· 18 min read