
Agents Simplified: What we mean in the context of AI
· 21 min read

Agents Simplified: What we mean in the context of AI
What is an AI Agent? Learn how AI agents work, the benefits of using AI agents and more
· 21 min read
What is an AI Agent? Learn how AI agents work, the benefits of using AI agents and more

Learn about the hybrid search feature that enables you to combine dense and sparse vectors to deliver the best of both search methods!

Learn about vector search, a technique that uses mathematical representations of data to find similar items in large data sets.
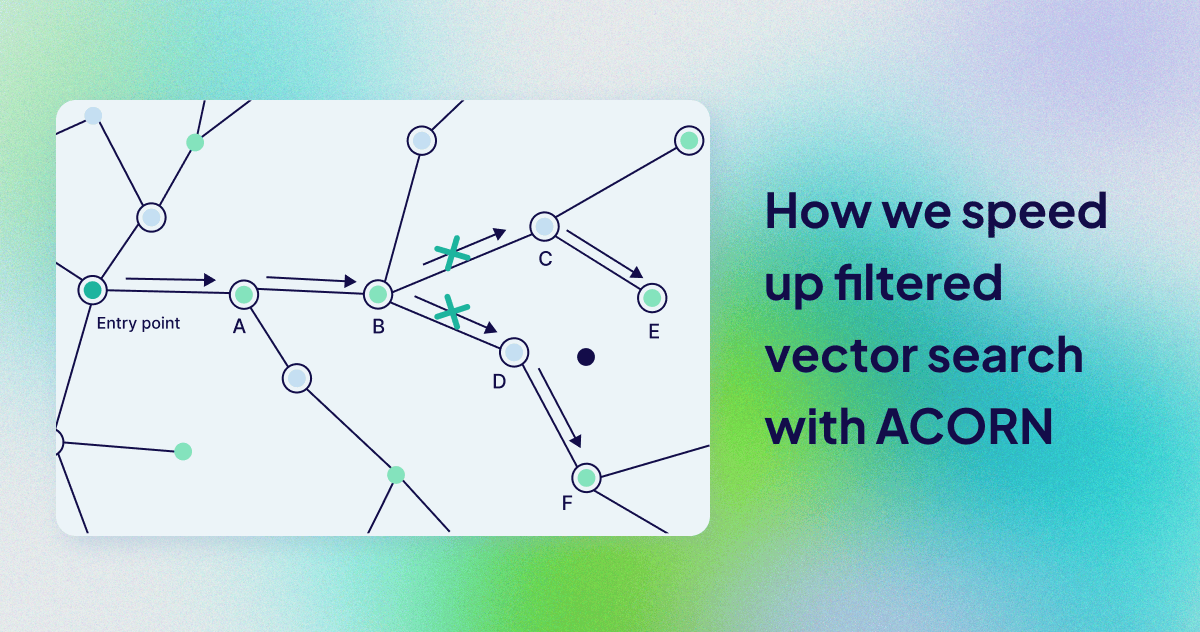
Learn about the challenges of filtered vector search and how Weaviate tackles them with ACORN.
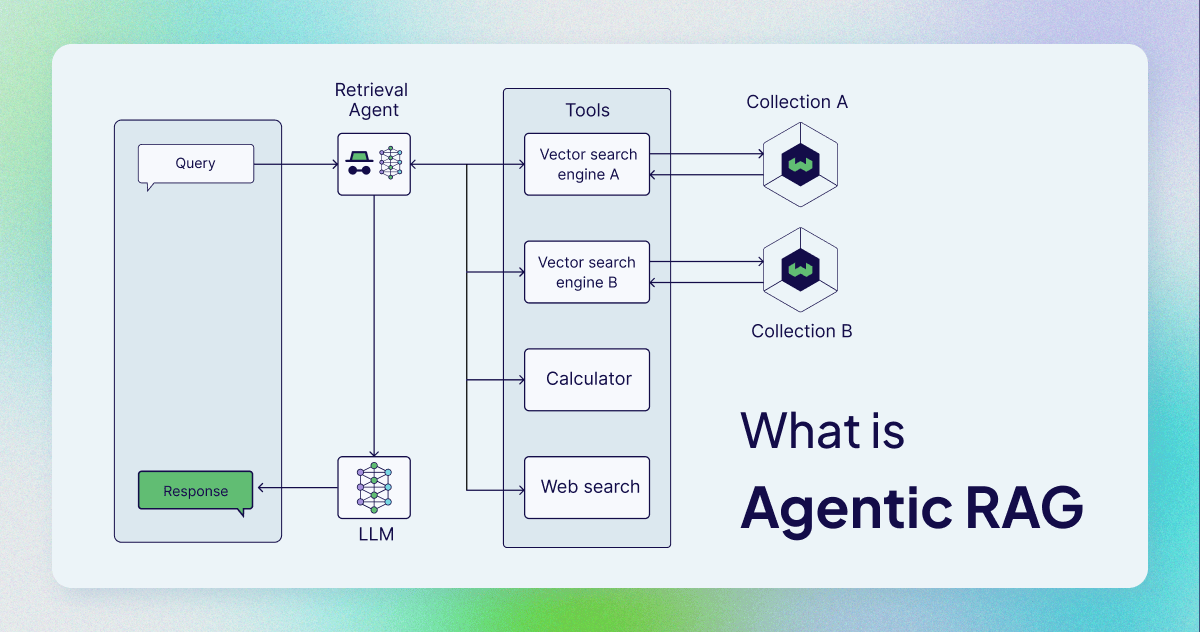
Learn what Agentic RAG is and how AI agents improve LLM RAG pipelines with tool use, multi-step retrieval, validation, and memory.
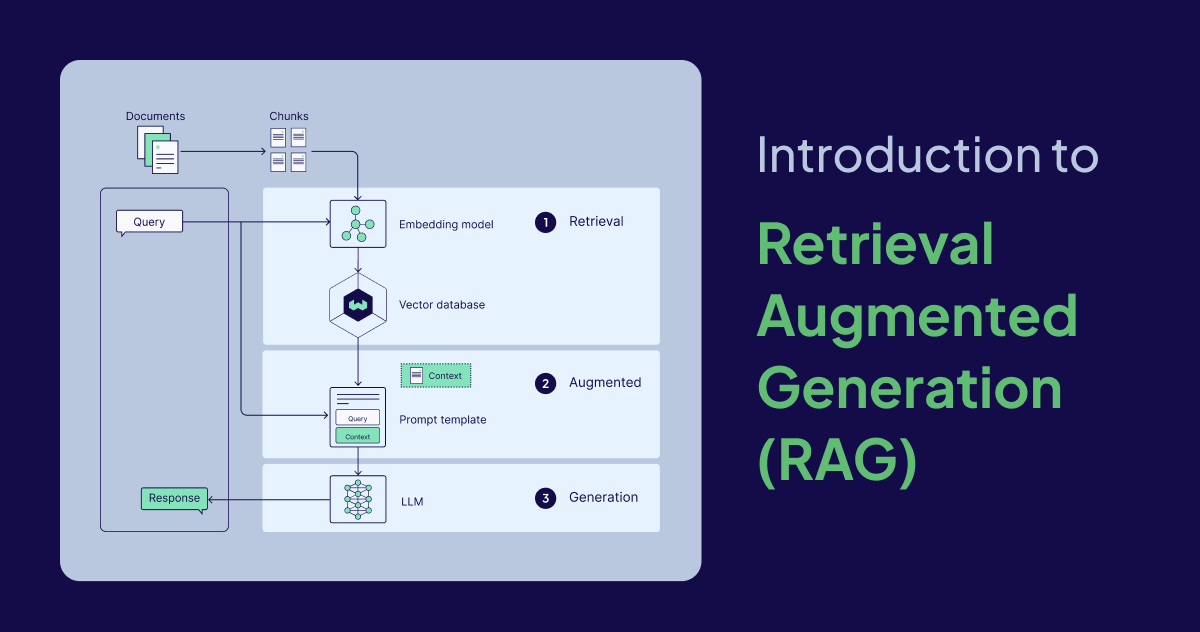
Learn what LLM RAG (Retrieval Augmented Generation) is, how RAG pipelines work, key use cases, implementation approaches, and evaluation methods.

Dive into how AI enables better eCommerce experiences with a focus on one critical component; Search.

Learn about Late Chunking and how it may be the right fit for balancing cost and performance in your long context retrieval applications

Learn about the power of generics and typing systems in Python and how they can improve your codebase.

Learn how to improve the individual indexing, retreival and generation parts of your RAG pipeline!

How to use OpenAI's embedding models trained with Matryoshka Representation Learning in a vector database like Weaviate
