
Weaviate Python client (v4) goes GA

The v4 Weaviate Python client library has landed in GA (general availability) form. The v4 client has a brand new API that is more powerful and easier to use 🎉🥳. This is a big update, as reflected by the bump in the major version number.
It still includes the existing (v3) API for now, so you can continue to use it without any changes. But we do note and the v3 API is considered deprecated, and will be removed in the future (estimated ~6 months).
If you're keen to get on with it, just pip install it with:
pip install -U weaviate-client
But if you're curious about what's new, read on - there's a lot that we are excited about!
Key ideas
The v4 client does things a little differently than the v3 client. Two of the key ideas where it differs are:
- Collection-based interactions, and
- Default property returns to queries.
Take this query, for example:
questions = client.collections.get("JeopardyQuestion")
response = questions.query.hybrid(
query="animal",
limit=2
)
for o in response.objects:
print(o.properties) # Object properties
Here, you'll notice that the query:
- is performed on a collection (
questions), not theclientitself, and - does not specify any properties to return.
This is because the v4 client is collection-based, and will return all properties (except blobs and references) by default. We think this makes the code more concise, and easier to use.
IDE assistance / autocomplete
And writing the queries is now also much easier, with more IDE assistance and autocomplete. For example, here's a query that uses the Filter class:
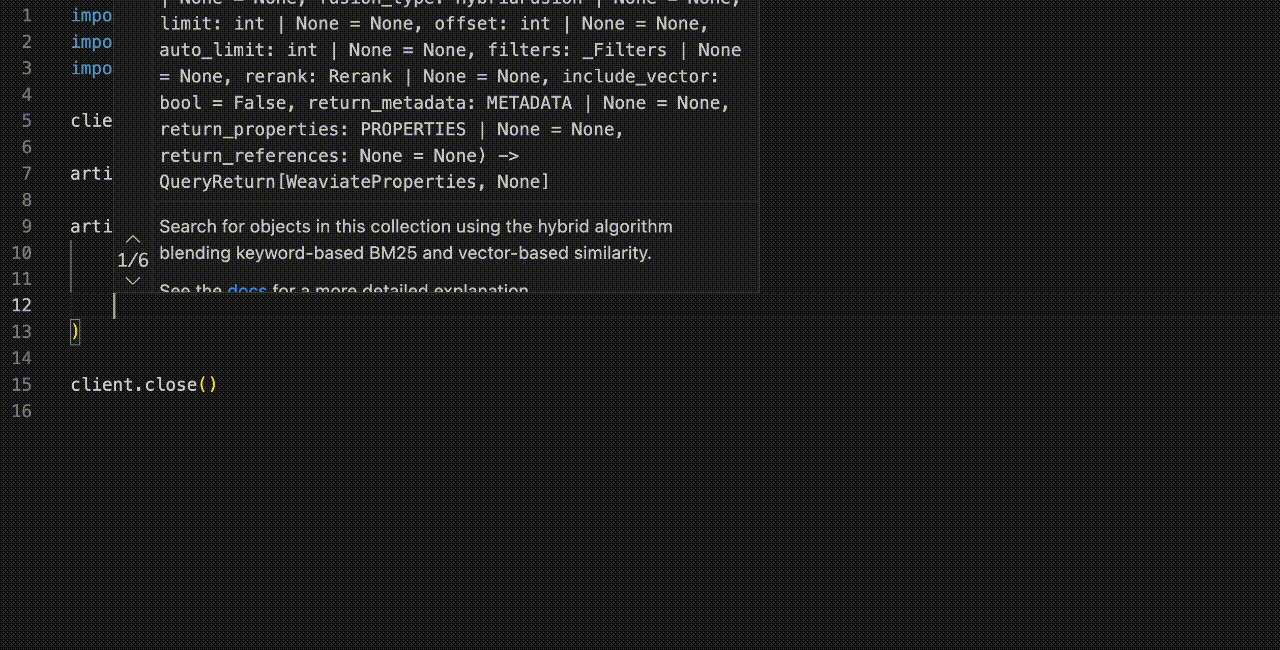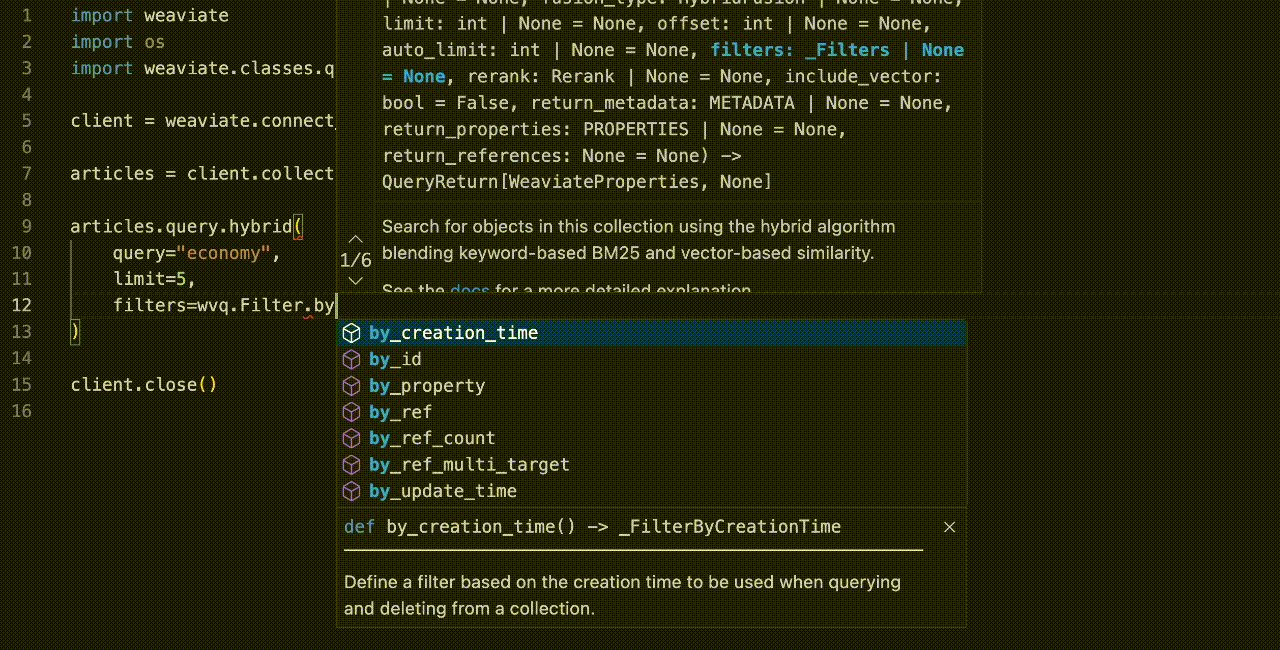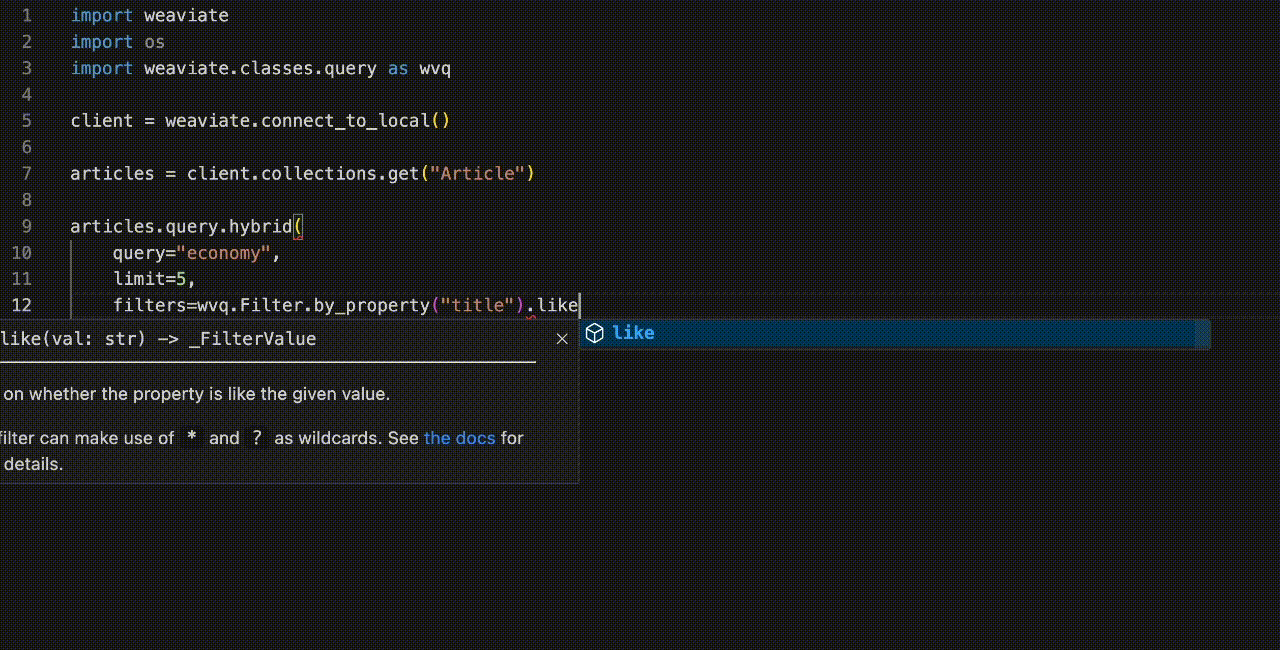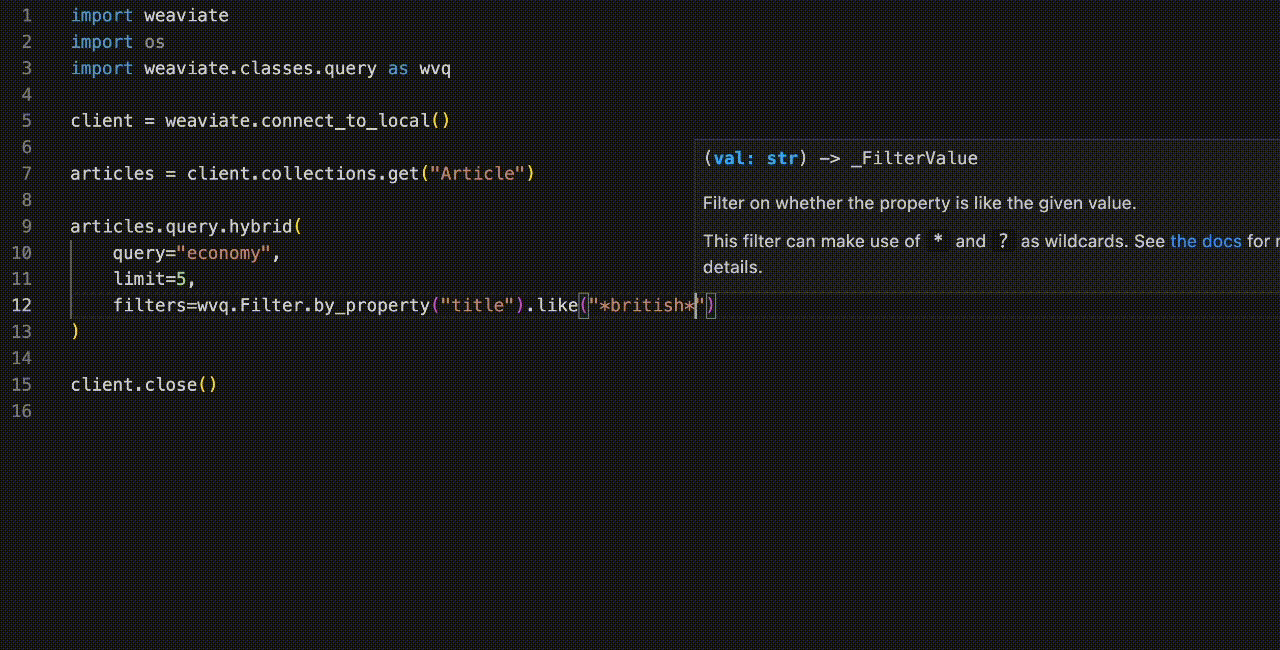
Notice all the nice autocomplete suggestions as we type! This extends to a great majority of operations, from collection creation to object insertion to query building.
Speed improvements
The new client is much faster than the v3 client, too. This is because it uses gRPC extensively under-the-hood.
The speed improvements during imports will increase along with the request size. As some rough examples, we've seen:
| Data imported | v3 client | v4 client |
|---|---|---|
ann dataset | ~50s | ~30s |
50k sphere objects | ~200s | ~120s |
Queries will also be faster with the v4 client, with ~40% - ~80% speed improvements being seen in our internal testing.
These are just some rough examples, but we think many of you will see noticeable speed improvements across the board. Also keep an eye out for a follow-up blogpost on this topic, where we'll dive into the details 😉.
Typing & type safety
Provision of these classes also means that the client is able to provide far more type hints, proving higher type safety.
For example, the like method in our Filter class example above helpfully tells you to insert the argument as a str. But if we were to use a within_geo_range method, it would tell us to use a coordinate as a GeoCoordinate instance, and a distance as a float.
This helps you to write the correct code, and also helps you to catch errors early.
Practical examples
Here are some practical examples. You'll find plenty of them throughout the Weaviate documentation - here, we present a few commonly used operations, with notes as required.
v4 vs v3 API
Here is an example that really captures the difference between the v4 and v3 APIs. Look at the difference in the code required to create a collection with properties.
- Python Client v4
- Python Client v3
from weaviate.classes.config import Property, DataType
# Note that you can use `client.collections.create_from_dict()` to create a collection from a v3-client-style JSON object
client.collections.create(
"Article",
properties=[
Property(name="title", data_type=DataType.TEXT),
Property(name="body", data_type=DataType.TEXT),
]
)
class_obj = {
"class": "Article",
"properties": [
{
"name": "title",
"dataType": ["text"],
},
{
"name": "body",
"dataType": ["text"],
},
],
}
client.schema.create_class(class_obj) # returns null on success
The v3 client API uses an untyped dictionary to specify the collection definition. It's efficient, but not very robust, and not particularly easy to use.
On the other hand, the v4 client API provides plenty of help through type hints and autocomplete suggestions as you navigate to the .create method, and use classes such as Property and DataType. It's also more robust, and easier to use.
Submodules
For discoverability, the classes that are used as arguments in function calls are arranged into submodules based on the type of operation they are used in.
Submodule details
The structure is similar to the collections structure. For example, if you are performing a query (e.g. collection.query.XXX) you'll find the needed classes in general under wvc.query.XXX. The following table shows the submodules and their descriptions.
| Module | Description |
|---|---|
weaviate.classes.config | Collection creation / modification |
weaviate.classes.data | CUD operations |
weaviate.classes.query | query/search operations |
weaviate.classes.aggregate | aggregate operations |
weaviate.classes.generic | generics |
weaviate.classes.init | initialization |
weaviate.classes.tenants | tenants |
weaviate.classes.batch | batch operations |
You can import the whole classes module, or just the classes you need. Many examples throughout the documentation use import weaviate.classes as wvc as a convention.
Client instantiation
The v4 client provide a set of helper functions, for connecting to Weaviate through its various deployment methods.
Direct instantiation with full control over the parameters is also possible, too. And, if you need an instance of the v3 style client, you can still use it.
- WCD
- Local
- Embedded
- Direct instantiation
- V3 API
import weaviate
from weaviate.classes.init import Auth
import os
# Best practice: store your credentials in environment variables
weaviate_url = os.environ["WEAVIATE_URL"]
weaviate_api_key = os.environ["WEAVIATE_API_KEY"]
openai_api_key = os.environ["OPENAI_APIKEY"]
client = weaviate.connect_to_weaviate_cloud(
cluster_url=weaviate_url, # Replace with your Weaviate Cloud URL
auth_credentials=Auth.api_key(weaviate_api_key), # Replace with your Weaviate Cloud key
headers={'X-OpenAI-Api-key': openai_api_key} # Replace with your OpenAI API key
)
import weaviate
client = weaviate.connect_to_local() # Connect with default parameters
import weaviate
client = weaviate.connect_to_embedded() # Connect with default parameters
import weaviate
from weaviate.connect import ConnectionParams
from weaviate.classes.init import AdditionalConfig, Timeout, Auth
import os
client = weaviate.WeaviateClient(
connection_params=ConnectionParams.from_params(
http_host="localhost",
http_port=8099,
http_secure=False,
grpc_host="localhost",
grpc_port=50052,
grpc_secure=False,
),
auth_client_secret=Auth.api_key("secr3tk3y"),
additional_headers={
"X-OpenAI-Api-Key": os.getenv("OPENAI_APIKEY")
},
additional_config=AdditionalConfig(
timeout=Timeout(init=30, query=60, insert=120), # Values in seconds
),
skip_init_checks=False
)
client.connect() # When directly instantiating, you need to connect manually
import weaviate
client = weaviate.Client(
url="http://localhost:8080",
)
Just remember that with the new WeaviateClient instances (i.e. v4 API), you should close the connection when you're done with it, as shown in the examples below. (This is still not necessary with the v3 API.)
- Try / Finally
- Context Manager
import weaviate
client = weaviate.connect_to_local() # Connect with default parameters
try:
pass # Do something with the client
finally:
client.close() # Ensure the connection is closed
import weaviate
with weaviate.connect_to_local() as client:
# Do something with the client
pass
# The connection is closed automatically when the context manager exits
Batch operations
The new client provides a set of methods to configure batching. These methods help you to control the batching behavior - including a handy rate_limit() method to avoid going past any third-party API rate limits.
| Method | Description | When to use |
|---|---|---|
dynamic | The batch size is dynamically calculated by Weaviate. | Recommended starting point. |
fixed_size | The batch size is fixed to a size specified by a user. | When you want to control the batch size. |
rate_limit | The number of objects sent to Weaviate is rate limited (specified as n_objects per minute). | When you want to avoid hitting third-party vectorization API rate limits. |
- Dynamic
- Fixed size
- Rate limit
import weaviate
client = weaviate.connect_to_local()
try:
with client.batch.dynamic() as batch: # or <collection>.batch.dynamic()
# Batch import objects/references - e.g.:
batch.add_object(properties={"title": "Multitenancy"}, collection="WikiArticle", uuid=src_uuid)
batch.add_object(properties={"title": "Database schema"}, collection="WikiArticle", uuid=tgt_uuid)
batch.add_reference(from_collection="WikiArticle", from_uuid=src_uuid, from_property="linkedArticle", to=tgt_uuid)
finally:
client.close()
import weaviate
client = weaviate.connect_to_local()
try:
with client.batch.fixed_size(batch_size=100, concurrent_requests=4) as batch: # or <collection>.batch.fixed_size()
# Batch import objects/references - e.g.:
batch.add_object(properties={"title": "Multitenancy"}, collection="WikiArticle", uuid=src_uuid)
batch.add_object(properties={"title": "Database schema"}, collection="WikiArticle", uuid=tgt_uuid)
batch.add_reference(from_collection="WikiArticle", from_uuid=src_uuid, from_property="linkedArticle", to=tgt_uuid)
finally:
client.close()
import weaviate
client = weaviate.connect_to_local()
try:
with client.batch.rate_limit(requests_per_minute=600) as batch: # or <collection>.batch.rate_limit()
# Batch import objects/references - e.g.:
batch.add_object(properties={"title": "Multitenancy"}, collection="WikiArticle", uuid=src_uuid)
batch.add_object(properties={"title": "Database schema"}, collection="WikiArticle", uuid=tgt_uuid)
batch.add_reference(from_collection="WikiArticle", from_uuid=src_uuid, from_property="linkedArticle", to=tgt_uuid)
finally:
client.close()
Error handling in batch operations
The v4 client introduces additional error handling operations. You can now monitor the number of errors in an ongoing batching operation, or simply review the errors after the operation has completed.
- During batching
- After completion
import weaviate
client = weaviate.connect_to_local()
max_errors = 500
try:
with client.batch.rate_limit(requests_per_minute=600) as batch:
# Insert objects here
if batch.number_errors > max_errors: # Monitor
pass # Do something (e.g. break)
finally:
client.close()
import weaviate
client = weaviate.connect_to_local()
try:
with client.batch.rate_limit(requests_per_minute=600) as batch:
pass # Batch import objects/references
# Note these are outside the `with` block - they are populated after the context manager exits
failed_objs_a = client.batch.failed_objects # Get failed objects from the batch import
failed_refs_a = client.batch.failed_references # Get failed references from the batch import
finally:
client.close()
Insertion methods
There's also single insertion methods, of course. And to that, we've added a insert_many method which is a convenience method for inserting a list of objects.
insert_many vs batchinsert_many sends one request for the entire function call. For requests with a large number of objects, consider using batch imports.
- Batch
- Insert many
- Single insert
# Option 1: Collection-level batching
questions = client.collections.get('JeopardyQuestion')
with questions.batch.dynamic() as batch:
pass # Batch import objects/references
# Option 2: Client-level batching
with client.batch.dynamic() as batch:
pass # Batch import objects/references
questions = client.collections.get("JeopardyQuestion")
# Build data objects - e.g. with properties, references, and UUIDs
data_objects = list()
for i in range(5):
properties = {"question": f"Test Question {i+1}"}
data_object = wvc.data.DataObject(
properties=properties,
# Add `references`, `vector` or `uuid` as needed
)
data_objects.append(data_object)
# Actually insert the data objects
response = questions.data.insert_many(data_objects)
questions = client.collections.get("JeopardyQuestion")
new_uuid = questions.data.insert(
properties={
"question": "This is the capital of Australia."
},
references={ # For adding cross-references
"hasCategory": target_uuid
}
)
Queries
Various types of queries are available for each collection. The query submodule is for single-object based queries, while the generate submodule is for RAG queries and aggregate for aggregation.
You can use different methods such as hybrid, near_text and so on within each submodule.
We've tried to keep methods as consistent as possible. So after you've tried object queries, you can enhance it to RAG queries by switching to the generate submodule, and provide any additional parameters as required for the prompts!
This makes it easy to switch between the different query types, and to discover the different query types available.
- Hybrid
- NearText
- NearText + RAG
- Aggregate + Filter
questions = client.collections.get("JeopardyQuestion")
response = questions.query.hybrid(
query="animal",
limit=2
)
for o in response.objects:
print(o.properties) # Object properties
The search query returns a parsed response, with the .objects property containing the retrieved Weaviate objects.
questions = client.collections.get("JeopardyQuestion")
response = questions.query.near_text(
query="animal",
limit=2
)
for o in response.objects:
print(o.properties) # Object properties
The search query returns a parsed response, with the .objects property containing the retrieved Weaviate objects.
questions = client.collections.get("JeopardyQuestion")
response = questions.generate.near_text(
query="animal",
limit=2,
grouped_task="What do these animals have in common?",
single_prompt="Translate the following into French: {answer}"
)
print(response.generated) # Generated text from grouped task
for o in response.objects:
print(o.generated) # Generated text from single prompt
print(o.properties) # Object properties
The RAG query is very similar to the equivalent search query, but using methods in the generate submodule.
from weaviate.classes.query import Filter
questions = client.collections.get("JeopardyQuestion")
response = questions.aggregate.over_all(
filters=Filter.by_property(name="question").like("*animal*"),
total_count=True
)
print(response.total_count)
This example retrieves a count of objects that match the filter criteria.
Returned data
As mentioned before, the default behavior now is to return all properties (except blobs and references) by default, as well as object uuids.
For less-often used attributes such as cross-references, metadata (previously under _additional) and vectors must be requested specifically. This is done through the return_references, return_metadata and include_vector parameters.
Note in the example below how the MetadataQuery and QueryReference classes reduce the amount of syntax memorization required to request metadata or cross-referenced data.
- Specify returns
- Default returns
questions = client.collections.get("JeopardyQuestion")
response = questions.query.bm25(
query="animal",
include_vector=True,
return_properties=["question"],
return_metadata=wvc.query.MetadataQuery(distance=True),
return_references=wvc.query.QueryReference(
link_on="hasCategory",
return_properties=["title"],
return_metadata=wvc.query.MetadataQuery(creation_time=True)
),
limit=2
)
for o in response.objects:
print(o.properties) # Selected properties only
print(o.references) # Selected references
print(o.uuid) # UUID included by default
print(o.vector) # With vector
print(o.metadata) # With selected metadata
questions = client.collections.get("JeopardyQuestion")
response = questions.query.bm25(
query="animal",
limit=2
)
for o in response.objects:
print(o.properties) # All properties by default
print(o.references) # References not returned by default
print(o.uuid) # UUID included by default
print(o.vector) # No vector
print(o.metadata) # No metadata
Responses
Responses from Weaviate are now parsed into instances of custom classes. For example, each query response will have a list of objects in the objects attribute, and each object will have a set of attributes itself. Responses for RAG queries will include a generated attribute at the top level for grouped_task query, and each object will also have a generated attribute for single_prompt queries.
Iterator
The client includes an iterator to make convenient use of the cursor API. This is useful for retrieving large numbers of objects, such as when manually exporting or migrating a collection.
- Default
- Selected properties
- Get metadata
all_objects = [question for question in questions.iterator()]
all_object_answers = [question for question in questions.iterator(return_properties=["answer"])]
all_object_ids = [question for question in questions.iterator(return_metadata=wvc.query.MetadataQuery(creation_time=True))] # Get selected metadata
len
You can even get the size of the collection by using the built-in len function - like this!
articles = client.collections.get("Article")
print(len(articles))
How to get started
As you can see - we are very excited about the release, and we hope you are, too. To get started with the client, just pip install it with:
pip install -U weaviate-client
Then, we have a few resources to help you get started:
| Title | Description |
|---|---|
| Weaviate Quickstart | New to Weaviate? Start here. |
| Python client library page | An overview of the client library |
| How-to: Manage data | CUD (create/update/delete) operation examples, including collection creation |
| How-to: Search | Search/query operation examples |
| References: Search | Reference documentation for searches; more detailed than the How-to guides |
| References: REST | Reference documentation for using the REST API |
Ready to start building?
Check out the Quickstart tutorial, or sign up for a free Weaviate Cloud account.
Don't want to miss another blog post?
Sign up for our bi-weekly newsletter to stay updated!
By submitting, I agree to the Terms of Service and Privacy Policy.