
Strengths of each search type
Overview
These different search types are offered because they each have different characteristics, and therefore different strengths.
Let's explore the relative strengths of each search type.
Strengths of vector search
Robustness
A vector is a numerical representation of the underlying object's meaning. As a result, a vector search is robust to any changes that don't affect the meaning of the object.
More concretely, a vector of "cat", for example, will be similar to a vector of "kitten", "feline", and "pet", even though their spellings are very different.
See this in action below, where we search for "cat" and "kitten" using vector search.
- Python
for query in ["cat", "kitten"]:
questions = client.collections.get("JeopardyQuestion")
response = questions.query.near_text(
query=query,
limit=1,
return_metadata=wvc.query.MetadataQuery(distance=True),
return_properties=["question", "answer"]
)
for o in response.objects:
print(f"\n===== Search results for {query} =====")
print(f"Distance: {o.metadata.distance:.3f}")
print(json.dumps(o.properties, indent=2))
You see that the results for "cat" and "kitten" are very similar.
In other words, the vectors for "cat" and "kitten" are similar in meaning, because the model can "understand" meaning.
===== Search results for cat =====
Distance: 0.170
{
"answer": "Fat cat",
"question": "A flabby tabby"
}
===== Search results for kitten =====
Distance: 0.150
{
"answer": "Fat cat",
"question": "A flabby tabby"
}
Similarly, a vector of "cat" is similar to the vector of "cat" with a spelling mistake, such as "caat", or "catt".
- Python
for query in ["cat", "catt", "caat"]:
questions = client.collections.get("JeopardyQuestion")
response = questions.query.near_text(
query=query,
limit=1,
return_metadata=wvc.query.MetadataQuery(distance=True),
return_properties=["question", "answer"]
)
for o in response.objects:
print(f"\n===== Search results for {query} =====")
print(f"Distance: {o.metadata.distance:.3f}")
print(json.dumps(o.properties, indent=2))
Here, the results are basically identical.
===== Search results for cat =====
Distance: 0.170
{
"answer": "Fat cat",
"question": "A flabby tabby"
}
===== Search results for catt =====
Distance: 0.177
{
"answer": "Fat cat",
"question": "A flabby tabby"
}
===== Search results for caat =====
Distance: 0.184
{
"answer": "Fat cat",
"question": "A flabby tabby"
}
This robustness is a key strength of vector search, as it means that the searcher does not need to know the exact words used in the dataset. This is particularly useful when the concepts being searched for are not well-defined, or when the searcher is not familiar with the dataset.
Versatility
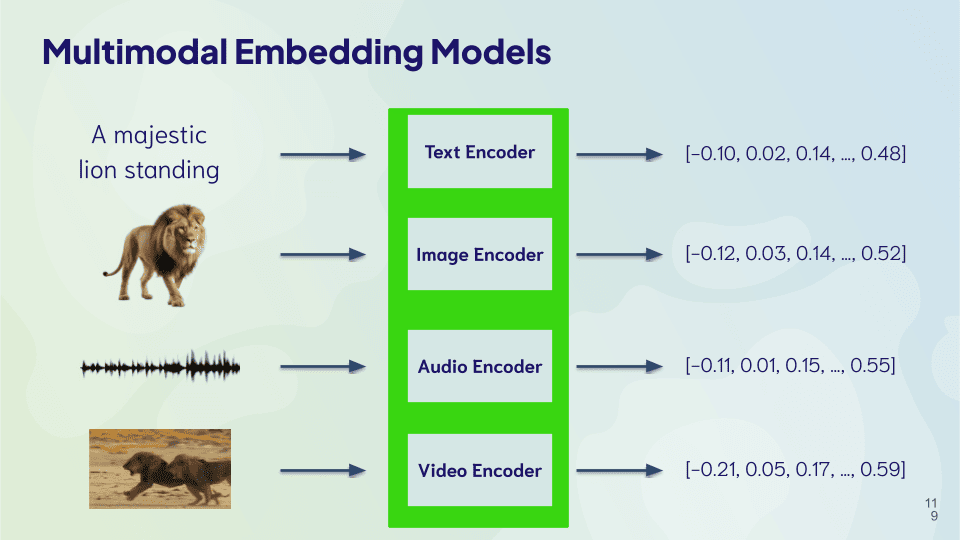
A vector search is also versatile. It can be used to search multiple data modalities (e.g. text, images, audio, etc.), and across multiple languages.
This is because the vector is a numerical representation of the underlying object's meaning, and therefore the same vector can be used to represent the same meaning, regardless of the data modality or language.
In fact, some models are capable of search across multiple data modalities, or multiple languages (or both!). This is made possible by using a model that can convert the data into comparable vectors, regardless of the data modality or language.
Strengths of keyword search
Exactitude
Keyword search is ideal for situations where locating precise matches are required. This is particularly useful in scenarios where there exist exact terms to search for, such as academic research, searches through domain-specific data or technical troubleshooting.
The ability to return results that precisely match the search terms ensures that users receive the most relevant information for their specific queries.
More concretely, take a look at the example below, where we search for "imaging".
- Python
questions = client.collections.get("JeopardyQuestion")
response = questions.query.bm25(
query="imaging", # Your query string
return_properties=["question", "answer"],
limit=2
)
for o in response.objects:
print(o.uuid)
print(json.dumps(o.properties, indent=2))
And when we inspect the results:
49fe3d7c-61a5-5916-99bb-052d07c7c251
{
"answer": "magnetic resonance imaging",
"question": "MRI, which stands for this, cannot be used on patients with pacemakers or artificial metal joints"
}
A search for "imaging" using a keyword search returns the one result that contains that specific word.
Strengths of hybrid search
A key strength of hybrid search is its resiliency. Let's explore this in more detail.
Resiliency
A hybrid search is resilient as it combines top results from both vector and keyword search. This helps to mitigate either search's shortcomings.
Take a look at the hybrid search example below.
- Python
questions = client.collections.get("JeopardyQuestion")
response = questions.query.hybrid(
query="imaging", # Your query string
return_properties=["question", "answer"],
limit=2
)
for o in response.objects:
print(o.uuid)
print(json.dumps(o.properties, indent=2))
We can inspect the results here:
49fe3d7c-61a5-5916-99bb-052d07c7c251
{
"answer": "magnetic resonance imaging",
"question": "MRI, which stands for this, cannot be used on patients with pacemakers or artificial metal joints"
}
9041bce6-b5d1-5637-bcbe-2ebb8a689fe0
{
"answer": "X-rays",
"question": "These electromagnetic rays used to take pictures of your insides were originally known as Roentgen rays"
}
You can see that as well as the keyword search result above (for "imaging"), we get a semantically relevant result (for "X-rays").
Because hybrid search combines the results of both vector and keyword search, it will find objects that score well on at least one of the search types. This approach has the effect of complementing each search type.