
How to import data
Overview
So far, you've learned that data in Weaviate is represented by objects, which belong to a class, and have a set of properties. In the previous section on the schema, you learned how to create a framework for this structure.
In this section, you will learn how to import data into Weaviate, including our recommended best practices, and some key considerations. Once you're done with this section, you will be ready to import a real dataset into Weaviate by putting together what we've learned about the schema and imports.
Imports: A high-level view
Object creation
To create a Weaviate object, you must:
- Load your source data,
- Build a data object with any desired properties, and
- Add it to your desired class in Weaviate.
Optionally, you can manually specify:
- An object ID, and
- A vector
- An object ID is required. So, if one is not specified, Weaviate will create one.
- If a vector is not specified, Weaviate will create one if a vectorizer is set for the class.
We'll cover these in more detail later on.
Use batch imports
Weaviate offers a "batch import" process to maximize the import speed. Take a look at this diagram that shows the object creation process:
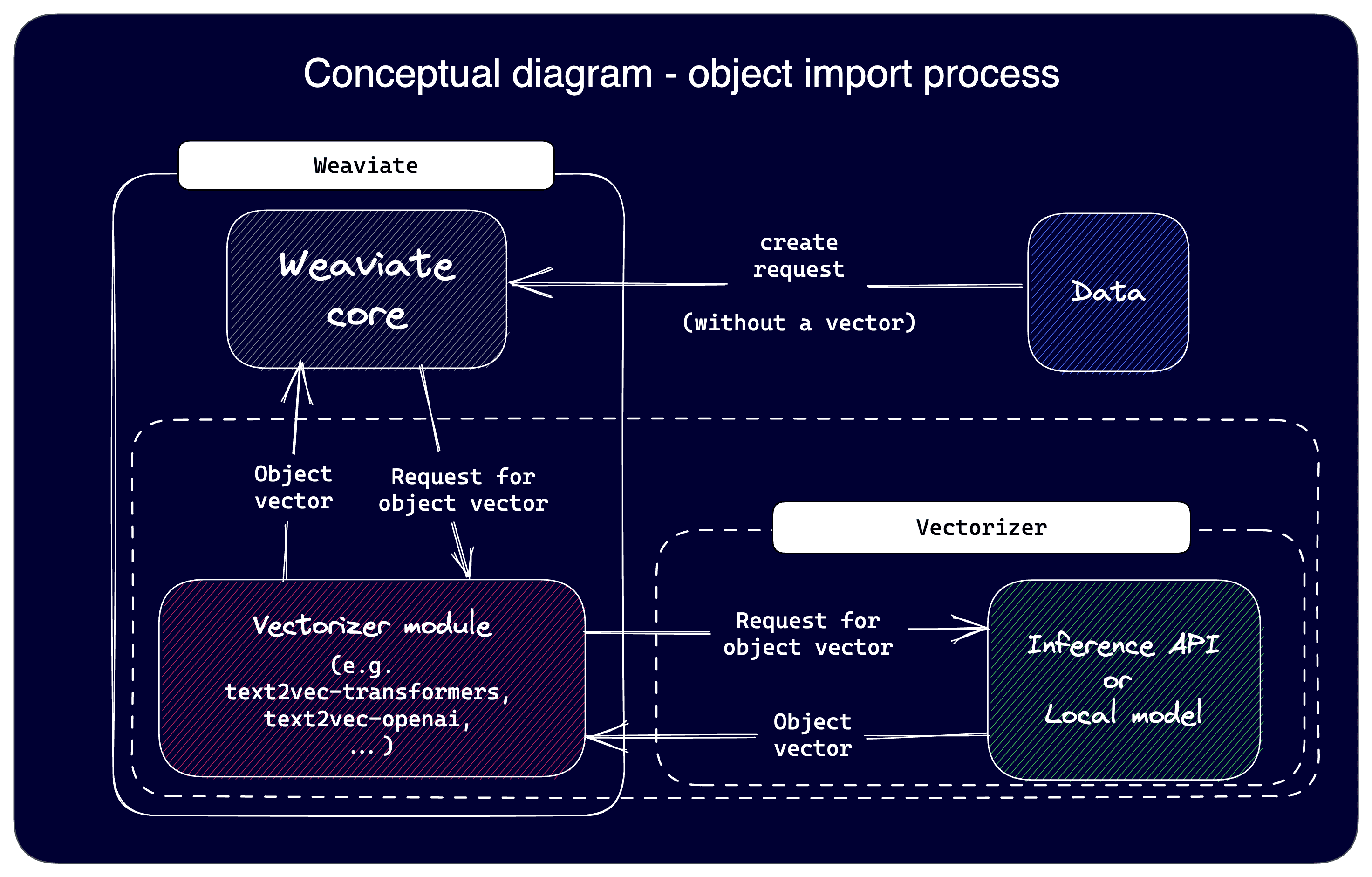
In the figure, a request is made to create an object based on the provided data.
If the vector is not provided and a vectorizer is specified, Weaviate (core) will send a request to the vectorizer module for a vector embedding. If that module is an inference-API based module, such as text2vec-cohere, it must then contact the inference API to request the appropriate vector.
You can imagine that in such a configuration, the network latencies may add a significant amount of time for large datasets, or become a bottleneck.
A batch import significantly reduces the impact of network latencies by processing multiple objects per request, and our clients (e.g. the Python client) can parallelize the process as well. You should use batch imports unless you have a good reason not to, as it will significantly improve the speed of data ingestion.
Batch import syntax
The batch syntax is shown below, with some of the parameters:
- Python
with client.batch(
batch_size=batch_size, # Specify batch size
num_workers=num_workers, # Parallelize the process
dynamic=True, # Enable/Disable dynamic batch size change
timeout_retries=n_retries, # Number of retries if a timeout occurs
connection_error_retries=n_retries, # Number of retries if a connection error occurs
) as batch:
for data_object in data_objects:
batch.add_data_object(
data_object,
class_name=target_class
)
Note that here, each data_object would be a Python dictionary whose keys correspond to the class properties.
data_objectVectors should be specified separately so that Weaviate knows it to be the object vector and it can be indexed. See below for the right syntax on how to specify the vector.
Error handling
The batch import process is configured to handle errors at a batch level, and at individual object level.
Batch-level errors
Any batch-level errors are indicated via the HTTP response code for the batch request.
- A 200 response code indicates that batch was successfully sent, connected and processed.
- A 4xx status code indicates that the request was malformed.
Object-level errors
Since a batch contains multiple objects, individual errors may occur during import even when the request was successful.
Accordingly, object-level errors are returned as a part of the response the batch creation requests.
Error handling syntax
If there are any object-level errors during import, they will be visible in the returned responses to batch.create_objects() or batch.create_references().
In the response, each object's result["result"]["errors"] value can be inspected to see if there were any errors.
A convenient way to do so is to define a callback function and specifying it while initializing the batch:
- Python
def check_batch_result(results: dict):
"""
Check batch results for errors.
Parameters
----------
results : dict
The Weaviate batch creation return value.
"""
if results is not None:
for result in results:
if "result" in result and "errors" in result["result"]:
if "error" in result["result"]["errors"]:
print(result["result"])
with client.batch(
batch_size=batch_size, # Specify batch size
num_workers=num_workers, # Parallelize the process
dynamic=True, # Enable/Disable dynamic batch size change
timeout_retries=n_retries, # Number of retries if a timeout occurs
connection_error_retries=n_retries, # Number of retries if a connection error occurs
callback=check_batch_result,
) as batch:
for data_object in data_objects:
batch.add_data_object(
data_object,
class_name=target_class,
uuid=uuid,
vector=object_vector,
)
This pattern would capture and print any object-level errors found during the import process.
Optional parameters
ID
Each object in Weaviate has a unique identifier. This ID must be a UUID, and can be user-provided, but if not, Weaviate will generate a random UUID.
Weaviate does not check if a duplicate object is being created. As a result, using a deterministic uuid may prevent accidental creation of duplicate objects.
Vector
Each object in Weaviate can have a vector embedding to represent it, although this is not mandatory.
- If a vector is specified at creation time, Weaviate will use that vector to represent the object.
- If a vector is not specified, Weaviate will check to see if a vectorizer setting applies to the relevant class.
- If so, Weaviate will send a request to that vectorizer module for a vector embedding.
- If not, the object will not have a vector representation.
- If a vectorizer was set in the schema for the class, this vectorizer will be used.
- If not, Weaviate will check for a default vectorizer setting for that Weaviate instance.
It is possible to both upload your own vectors and specify a vectorizer for Weaviate. For example, if you are importing a large dataset and have vectorized the data using a vectorizer that is also available through Weaviate, this may be a useful approach. This will allow you to use Weaviate to vectorize any updates to the dataset, as well as to vectorize queries as necessary.
We will explore these options in more detail in another unit.
Example with id & vector
To manually specify the object ID and vector, the syntax is as follows.
- Python
with client.batch(
batch_size=batch_size, # Specify batch size
num_workers=num_workers, # Parallelize the process
dynamic=True, # Enable/Disable dynamic batch size change
timeout_retries=n_retries, # Number of retries if a timeout occurs
connection_error_retries=n_retries, # Number of retries if a connection error occurs
) as batch:
for data_object in data_objects:
batch.add_data_object(
data_object,
class_name=target_class,
uuid=uuid,
vector=object_vector,
)
With these parameters, you have the option of manually specifying the object ID and vector.
Review
Review exercise
- After studying the batch import process, try to explain it in your own words.
- Include in your explanation what the batch import process is, why it is used, and how it improves the speed of data ingestion.
- Can you recall which parameters were optional in the object creation process?
- Can you imagine scenarios in which you might want to, or not want to, specify these parameters?
Key takeaways
- To create a Weaviate object, you need to build a data object with properties, and add it to your desired class.
- Use batch imports to maximize import speed and minimize network latency. Batch import processes multiple objects per request, and clients can parallelize the process.
- Error handling during import can be done at the batch level or individual object level.
- You can manually specify an object ID and vector for each object in Weaviate.
- If an ID is not specified, Weaviate will create one.
- If a vector is not specified, Weaviate will create one if a vectorizer is specified.
- The vectorizer setting can be set in the schema.
Questions and feedback
If you have any questions or feedback, let us know in the user forum.