
Using Embedding models in Weaviate
What are Embedding Models
Embedding models are machine learning models trained to represent information as an array of numbers, frequently referred to as vector embeddings. Vectors or vector embeddings are numeric representations of data that represent certain properties or features. This representation can be used to efficiently search through objects in a vector space.
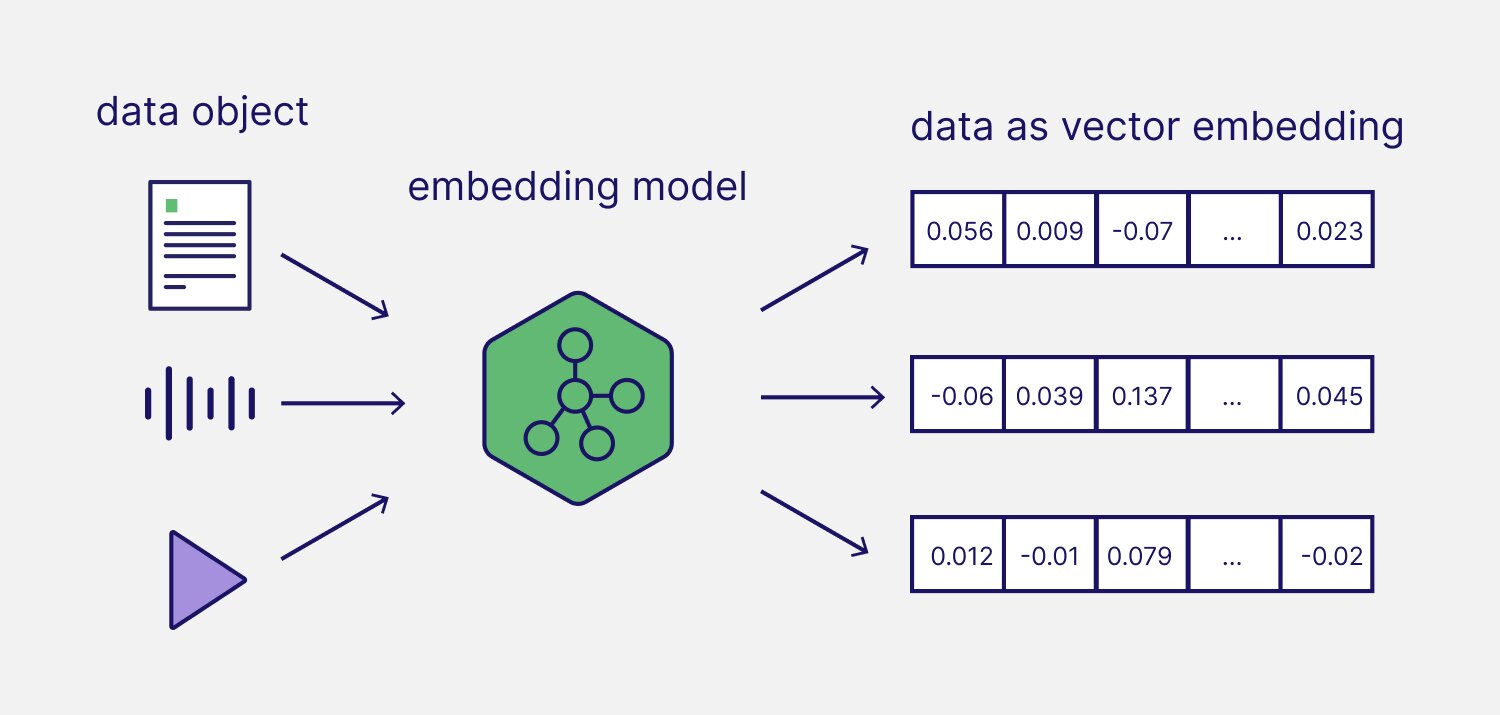
When to use Embedding Models
Embeddings are the worker horses behind modern search and Retrieval-Augmented Generation (RAG) applications. They are great for..
- Search: Results of searches are ranked by the distance from an input query vector.
- Classification: Items are classified by what category their vector representation is closest to.
- Recommendations: Items with similar vector representations are recommended to users.
Applications of Embedding Models
Embedding models, like most machine learning models are typically limited to one or more modalities.
We use modality to describe the type of input or output that a machine learning model can process or interact with to run. Typically, embedding modals fall into two buckets, uni-modal or multimodal.
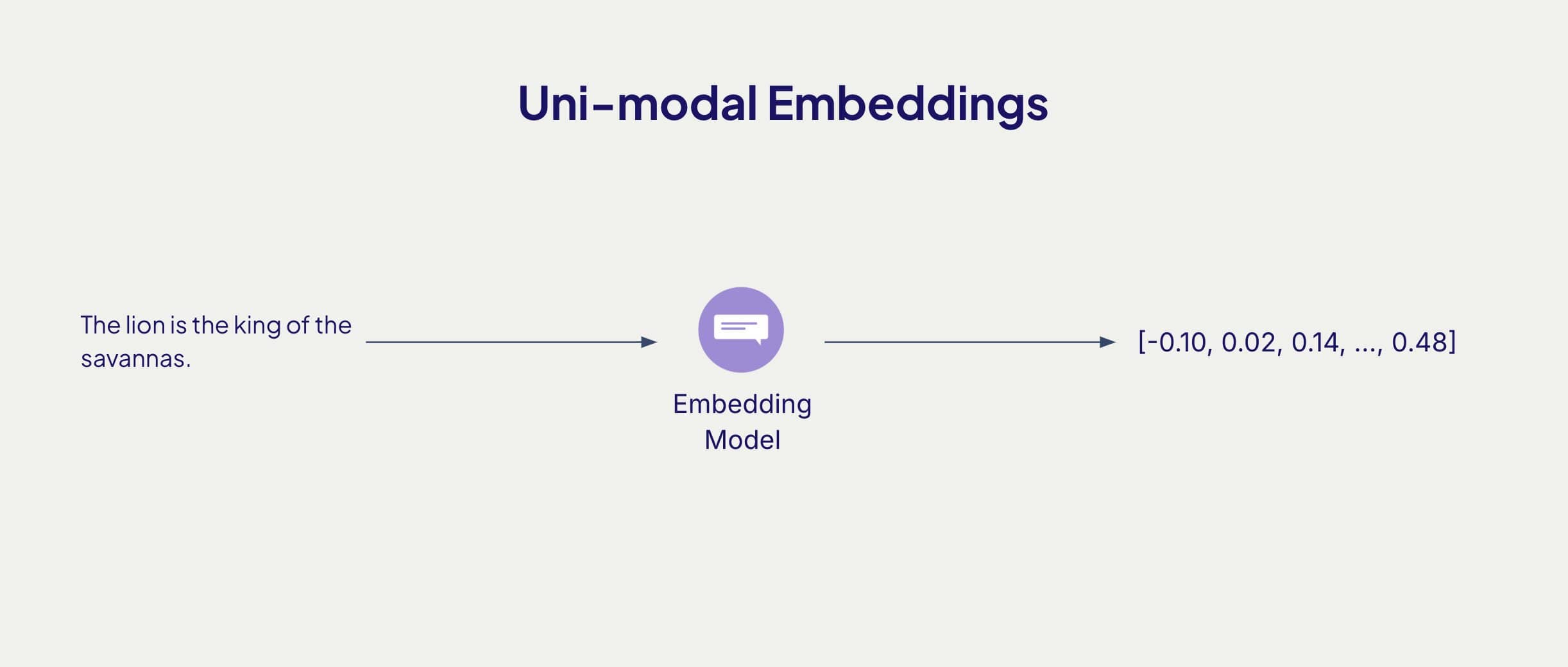
- Uni-modal Embeddings: These embeddings represents a single modality in a multi-dimensional vector space. Examples of these are embed-multilingual-v3.0 a text embedding model by Cohere or marengo 2.7 a video embedding models by Twelve Labs.
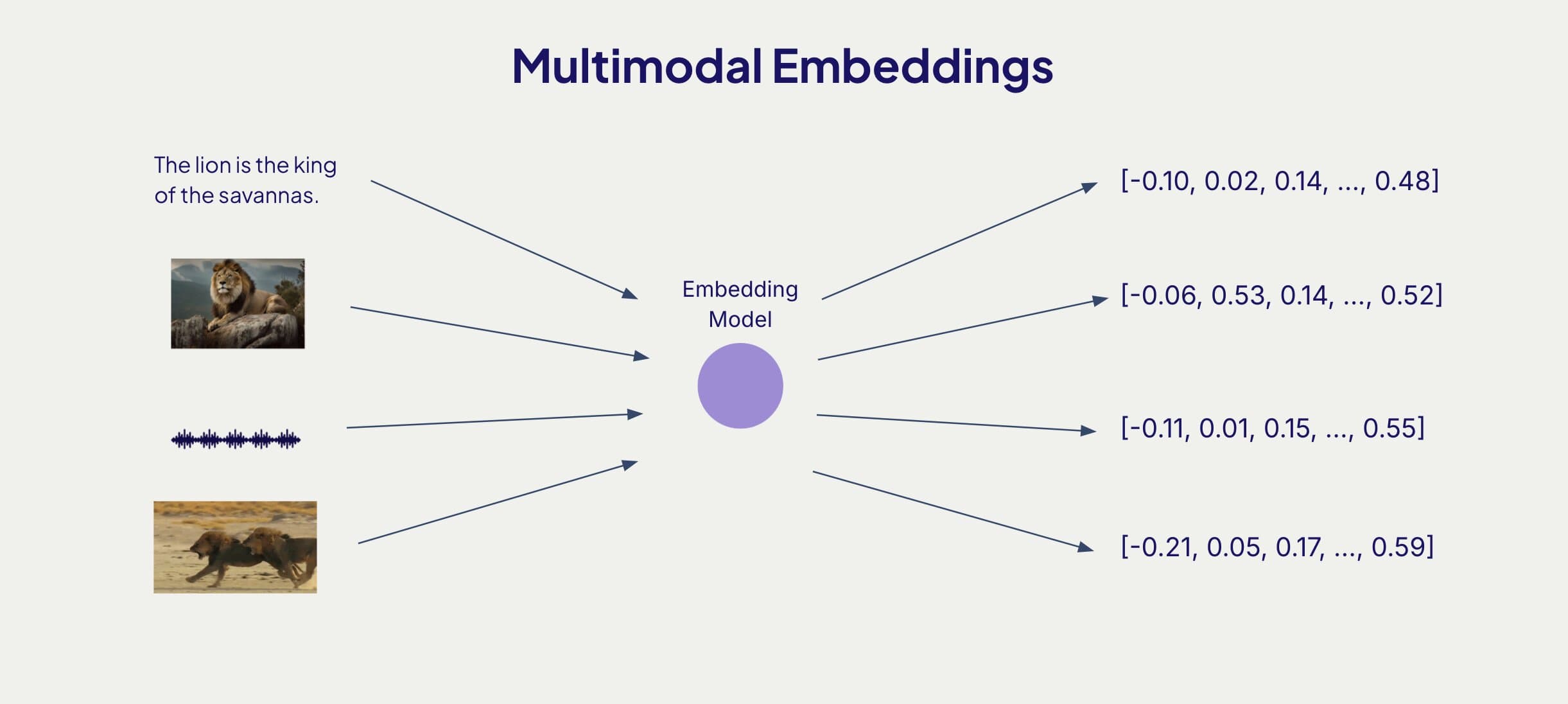
- Multimodal Embeddings: These embeddings represent multiple modalities in a multi-dimensional space. Allowing cross modal retrieval and clustering. CLIP is a popular multimodal model that can create embeddings of text, audio and video data.
Using Embedding Models in Weaviate
Weaviate takes most of the complexity of generating and managing embeddings away! Weaviate is configured to support many different vectorizer models and vectorizer service providers. It also gives you the option of providing your own vectors.
In Weaviate, vector embeddings power hybrid and semantic search.
Lets walk through the process to configure embedding models in Weaviate and make a semantic search. We'll start by creating a free sandbox account on Weaviate Cloud. Follow this guide if you have trouble setting up a sandbox project.
Step 1: Connect to a Weaviate instance
import weaviate, { WeaviateClient, configure } from 'weaviate-client'
const weaviateURL = process.env.WEAVIATE_URL as string
const weaviateKey = process.env.WEAVIATE_API_KEY as string
const cohereKey = process.env.COHERE_API_KEY as string
// Connect to your Weaviate instance
const client: WeaviateClient = await weaviate.connectToWeaviateCloud(weaviateURL,{
authCredentials: new weaviate.ApiKey(weaviateKey),
headers: {
'X-Cohere-Api-Key': cohereKey, // Replace with your inference API key
}
}
)
Initialize your connection with Weaviate and add relevant environment variables necessary to access third party embedding models.
Step 2: Define a Collection and Embedding Model
await client.collections.create({
name: 'JeopardyQuestion',
properties: [
{ name: 'Category', dataType: configure.dataType.TEXT },
{ name: 'Question', dataType: configure.dataType.TEXT },
{ name: 'Answer', dataType: configure.dataType.TEXT}
],
// Define your Cohere vectorizer and generative model
vectorizers: weaviate.configure.vectorizer.text2VecCohere({
sourceProperties: ["Question", "Answer"]
}),
});
When creating a collection in Weaviate, we define what embedding model we want to use. In this example we use a text embedding model by Cohere to create vector embeddings our data. This is embed-multilingual-v3.0 when we use the text2vecCohere() module.
Step 3: Importing data
let jeopardyCollection = client.collections.get('JeopardyQuestion');
// Download data to import into the "JeopardyQuestion" collection
const url = 'https://raw.githubusercontent.com/weaviate/weaviate-examples/main/jeopardy_small_dataset/jeopardy_tiny.json'
const response = await fetch(url);
const jeopardyQuestions = await response.json();
// Bulk insert downloaded data into the "JeopardyQuestion" collection
await jeopardyCollection.data.insertMany(jeopardyQuestions.data)
Once our collection is created, we import data. It is at import time where we interact with our embedding model. The Weaviate vectorizer sends objects to the embedding model we define during collection creation. At the end of this, we have both our data objects and their corresponding vector representations stored in our Vector Database. Now we can run semantic search queries.
Step 4: Running a Semantic Search
const jeopardyCollection = client.collections.get('JeopardyQuestion');
const searchResults = await jeopardyCollection.query.nearText(['question about animals'], {
limit: 3,
returnMetadata: ['distance'], // Return the distance of results from the query vector
includeVector: false // Change to true to include objects' vectors in your response
})
console.log("Near Text objects for:", JSON.stringify(searchResults, null, 2));
Here we make a query and set return as true so we can see the objects' vectors in our response. Read more about search here.
Bonus Learning
Vector Representations
Vector representations are the fundamental output of embedding models. They translate complex data (text, images, etc.) into fixed-length arrays of numbers that capture semantic meaning.
Dimensionality: Typically ranges from 384 to 1536 dimensions, depending on the model. A larger dimensionality usually means more accuracy but also a higher memory footprint for generated vectors.
Format: Vectors are typically floating point numbers, usually normalized to a specific range.
Distance metrics
Distance metrics quantify the similarity between vector embeddings. Weaviate uses cosine similarity as the default distance metric for semantic similarity.
Embedding models vary when it comes to performance and ability, read through this article so you have an idea of what to think about decide between various models.