
Using Generative Models in Weaviate
What are Generative Models
Generative models are machine learning models that when prompted, can generate original data guided by instructions in the prompt i.e. text, images, and other forms. This original data is derived from data it was trained on but does not mimic it like for like.
Generative Models encompass so many types of models, we will specifically focus on large language models (LLMs).
When to use Generative Models
Generative models are stars in the limelight of retrieval augmented generation (RAG) and agentic workflows. They are great for...
- Translation: Models can perform zero-shot translate text from one language to another with extremely high accuracy.
- Code Generation: Models can take high-level instructions and turn them into functional custom code.
- Image Generation: Models can consistently generate high quality images from text instructions in a prompt.
Applications of Generative Models
Large Language Models (LLMs), like Claude family by Anthropic or Gemini by Google are specialized types of generative models focused on text data. These models, like most machine learning models are typically limited to one or more modalities.
We use modality to describe the type of input or output that a machine learning model can process or interact with to run. Typically, generative modals fall into two buckets, uni-modal or multimodal.
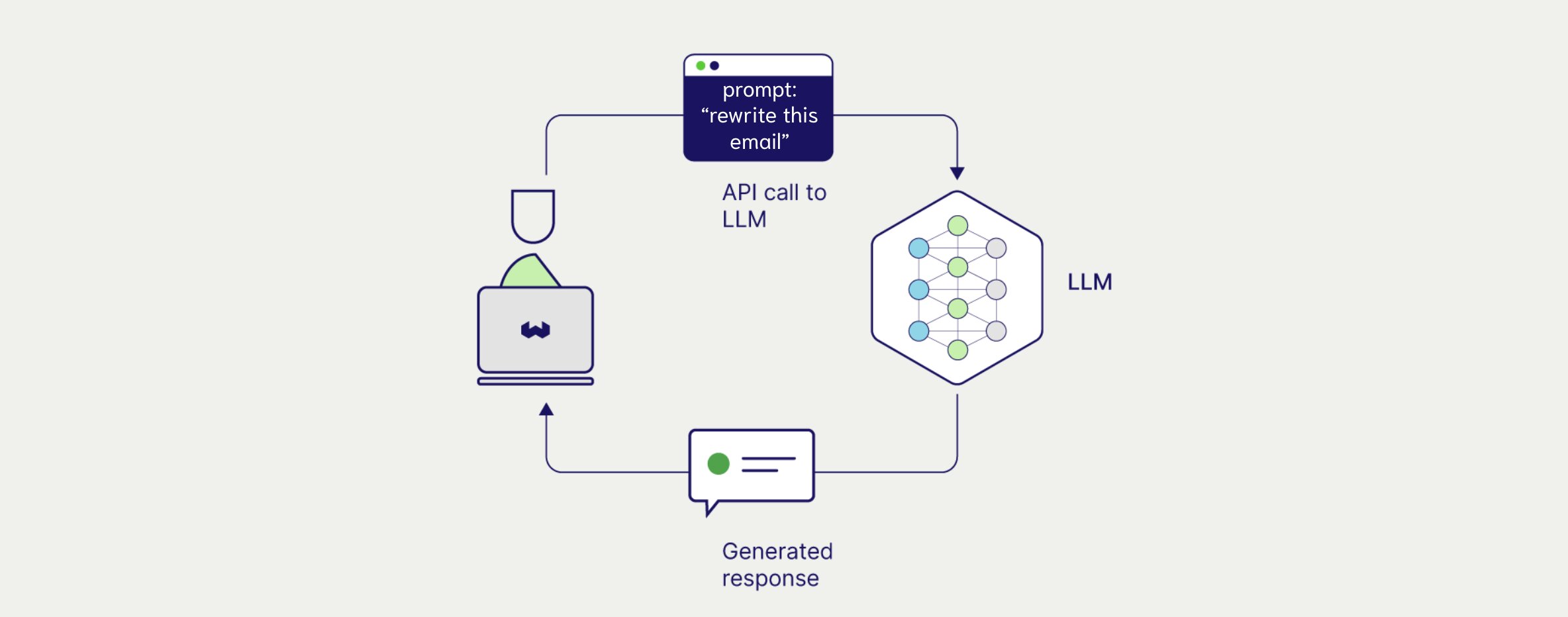
- Uni-modal Generation: In the context on LLMs, uni-modal generation defines a models ability to generate content and receive instructions in a single modality, this modality is usually text.
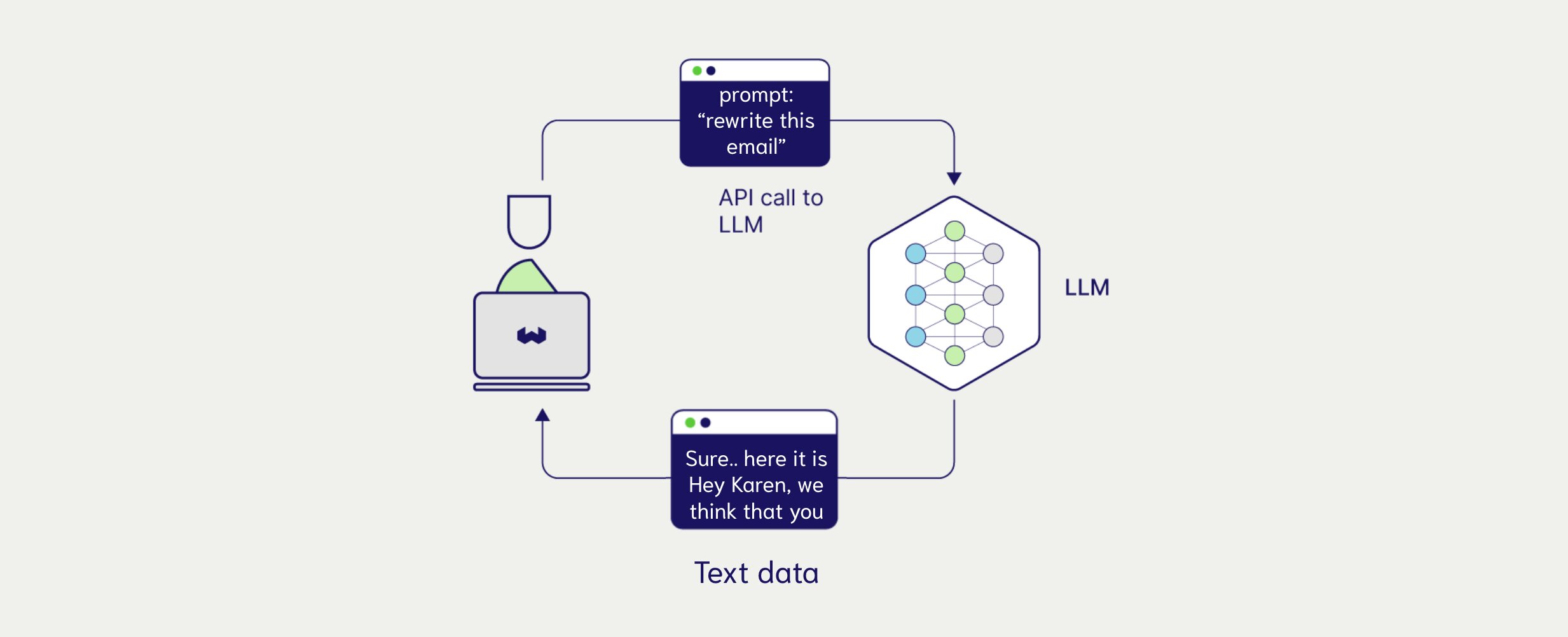
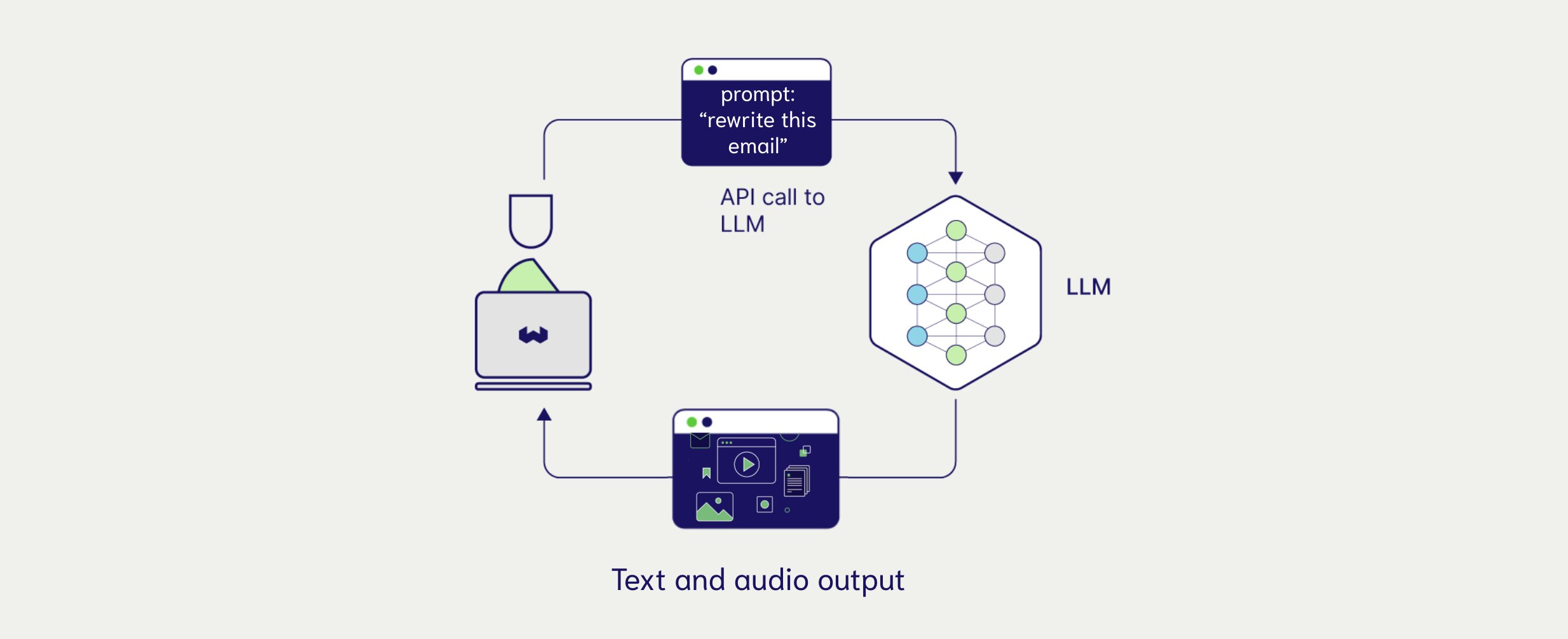
- Multimodal Generation: In the context on LLMs, multimodal generation defines a models ability to generate and receive instructions in multiple modalities. This can range from text input to generation or even image input to audio generation.
Using Generative Models in Weaviate
Weaviate is configured to support many generative models and generative model providers. You can even plug in your own generative model too depending on where in the Weaviate workflow you need generative capabilities.
In Weaviate, generative models power RAG (generative search). Lets walk through what its like to use generative models in Weaviate. We'll start by creating a free sandbox account on Weaviate Cloud. Follow this guide if you have trouble setting up a sandbox project.
Step 1: Connect to a Weaviate instance
import weaviate, { WeaviateClient, configure } from 'weaviate-client'
const weaviateURL = process.env.WEAVIATE_URL as string
const weaviateKey = process.env.WEAVIATE_API_KEY as string
const cohereKey = process.env.COHERE_API_KEY as string
// Connect to your Weaviate instance
const client: WeaviateClient = await weaviate.connectToWeaviateCloud(weaviateURL,{
authCredentials: new weaviate.ApiKey(weaviateKey),
headers: {
'X-Cohere-Api-Key': cohereKey, // Replace with your inference API key
}
}
)
Initialize your connection with Weaviate and add relevant environment variables necessary to access third party generative models.
Step 2: Define a Collection and Generative Model
await client.collections.create({
name: 'JeopardyQuestion',
properties: [
{ name: 'Category', dataType: configure.dataType.TEXT },
{ name: 'Question', dataType: configure.dataType.TEXT },
{ name: 'Answer', dataType: configure.dataType.TEXT}
],
// Define your Cohere vectorizer and generative model
vectorizers: weaviate.configure.vectorizer.text2VecCohere(),
generative: weaviate.configure.generative.cohere()
});
When creating a collection in Weaviate, we define what generative model we want to use. In this example we use a text generation model by Cohere to generate new data. This is command-r by default.
Step 3: Importing data
let jeopardyCollection = client.collections.get('JeopardyQuestion');
// Download data to import into the "JeopardyQuestion" collection
const url = 'https://raw.githubusercontent.com/weaviate/weaviate-examples/main/jeopardy_small_dataset/jeopardy_tiny.json'
const response = await fetch(url);
const jeopardyQuestions = await response.json();
// Bulk insert downloaded data into the "JeopardyQuestion" collection
await jeopardyCollection.data.insertMany(jeopardyQuestions.data)
console.log('Data Imported');
Once our collection is created, we import data. It is at import time where we interact with our embedding model. The Weaviate vectorizer sends objects to the embedding model we define during collection creation. At the end of this, we have both our data objects and their corresponding vector representations stored in our Vector Database. Now we can run semantic search queries and with a generative model defined, RAG!
Step 4: Making a Single Task Generative Search
const genResult = await myCollection.generate.nearText("african elephant in savanna", {
singlePrompt: "translate {answer} into french for me",
})
for (const item of genResult.objects) {
console.log("Single generated concept:", item.generated);
}
Here we use a singlePrompt to make n requests to the language model where n is the number of responses we get from our semantic search. We use limit to strictly define the number of responses we get. We can place responses from each response into our prompt with this format { answer } i.e we want the answer property from our search response to be translated to French.
Step 5: Making a grouped Generative Search
const groupedGenResult = await myCollection.generate.nearText("african elephant in savanna", {
groupedTask: "Summarize all the results received into a single informational paragraph?",
groupedProperties: ["answer"]
})
console.log("Grouped generated concept:", groupedGenResult.generated);
Here we use the groupedTask prompt format to group all the response from our search and send them alongside our prompt as context for what ever we are requesting. You can see with groupedProperties we only pass the answer property from all the results we get as context to the large language model, giving us control of what information will inform the models output.
Bonus Learning
Prompt engineering & Output control
Prompt engineering is the science of refining inputs or "prompts" to AI models to achieve desired or more effective outputs. It involves..
- Clear Instructions: Being specific and explicit in your requests helps the AI understand exactly what you need. Instead of "analyze this," try "provide a detailed analysis of the key themes and supporting evidence."
Context windows
The context window represents how much information an AI model can "see" and process at once. Think of it as the model's working memory for each conversation.
- Token Limits: Context windows are measured in tokens (roughly 3/4 of a word in English). Different models have different limits - from a few thousand to hundreds of thousands of tokens.
Both managing context windows and prompt engineering are a great way to begin refining your RAG implementation.
Generative models vary when it comes to performance and ability. Browse our integrations page to have a better idea of what options you can use in Weaviate.