
Product quantization
Product quantization (PQ), is a technique used to compress vectors. In Weaviate, it can be used to reduce the size of the in-memory HNSW index, which can improve performance and reduce resource requirements as well as costs.
What is product quantization?
Product quantization compresses vectors in two ways. One, by dividing them into "segments", and two, quantizing each segment to be represented by one of a "codebook" of centroids.
In the diagram below, we show a vector of L dimensions, where each dimension is a floating point number. The vector is divided into L/x segments, and each segment is quantized to be represented by one of N centroids.
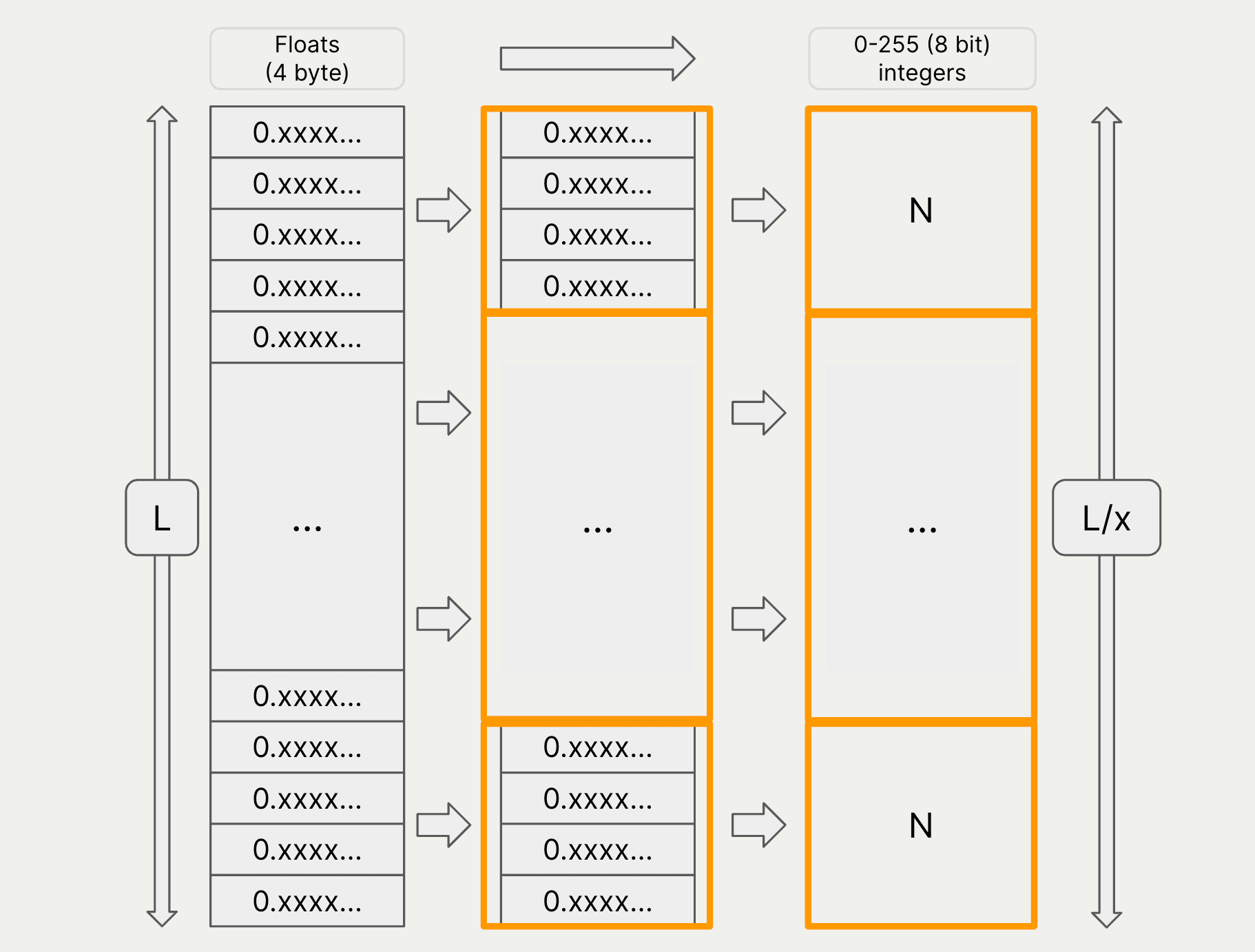
As an example, a 768-dimensional vector can be compressed into a 128-segment quantized vector of 1-byte integers.
This will reduce the length of the vector by a factor of 6, and also the size of each segment from a floating point number (4 bytes) to a byte, representing one of 256 centroids.
As a result, the size of the vector is reduced by 24 (from 768 lots of 4 byte numbers to 128 lots of 1 byte numbers).
The HNSW index can then be built on the PQ-compressed vectors, which will reduce the size of the index in memory.
Lossiness
PQ is a lossy compression technique, as the original floating point numbers are quantized to a smaller set of integers. This means that some information is lost in the compression process.
However, Weaviate compensates for this by overfetching vectors from the index, and then rescoring the vectors in the uncompressed space. In practice, we find that this compensates quite well for the lossiness of PQ.
Configure PQ
This example creates a collection with product quantization (PQ) enabled, using default settings.
from weaviate.classes.config import Configure, DataType, Property
# Client instantiation not shown
collection_name = "PQExampleCollection"
client.collections.create(
name=collection_name,
# Other configuration not shown
vector_index_config=Configure.VectorIndex.hnsw(
quantizer=Configure.VectorIndex.Quantizer.pq()
),
)
client.close()
Explain the code
This will create a collection with PQ enabled, using the default settings.
But it is important to note that the compression does not occur immediately. PQ relies on quantization of the vectors, so it is configured to wait until there are sufficient vectors to reach a "training set", by default 100,000 vectors.
The training set is used to calculate the centroids for the quantization. Once the training set is reached, the PQ compression will occur.
This type of PQ configuration is called "AutoPQ", and is available in Weaviate v1.23 or later, with asynchronous indexing enabled.
If you are using an earlier version of Weaviate, or have asynchronous indexing disabled, you will need to use a different configuration. Please refer to the PQ configuration documentation for more information.
Customize PQ
Many PQ parameters are configurable. While the default settings are suitable for many use cases, you may want to customize the PQ configuration to suit your specific requirements.
The example below shows how to configure PQ with custom settings, such as with a lower training set size, and a different number of centroids.
from weaviate.classes.config import Configure, DataType, Property
from weaviate.collections.classes.config import PQEncoderType, PQEncoderDistribution
# Client instantiation not shown
collection_name = "PQExampleCollection"
client.collections.create(
name=collection_name,
# Other configuration not shown
vector_index_config=Configure.VectorIndex.hnsw(
quantizer=Configure.VectorIndex.Quantizer.pq(
segments=512,
centroids=256,
training_limit=50000,
encoder_distribution=PQEncoderDistribution.NORMAL,
encoder_type=PQEncoderType.TILE,
)
),
)
client.close()
Please refer to the PQ configuration documentation for more information on the available settings.
Questions and feedback
If you have any questions or feedback, let us know in the user forum.