
Generative AI models
Weaviate integrates with many generative models so that they can be used conveniently in conjunction with the stored data, such as for generating summaries from retrieved data. In many ways, much of the details you see in this module are abstracted away when you use Weaviate.
Many of us may use AI models through a chat-type application such as Claude.ai, ChatGPT or Meta AI. These applications are also powered by deep learning models. Models such as claude-3.5, gpt-4 and llama-3 models respectively.
This type of model is generally called “generative AI”, or a “generative model”.
How generative AI models work
In the previous section, we saw how deep learning models work. Here is a reminder:
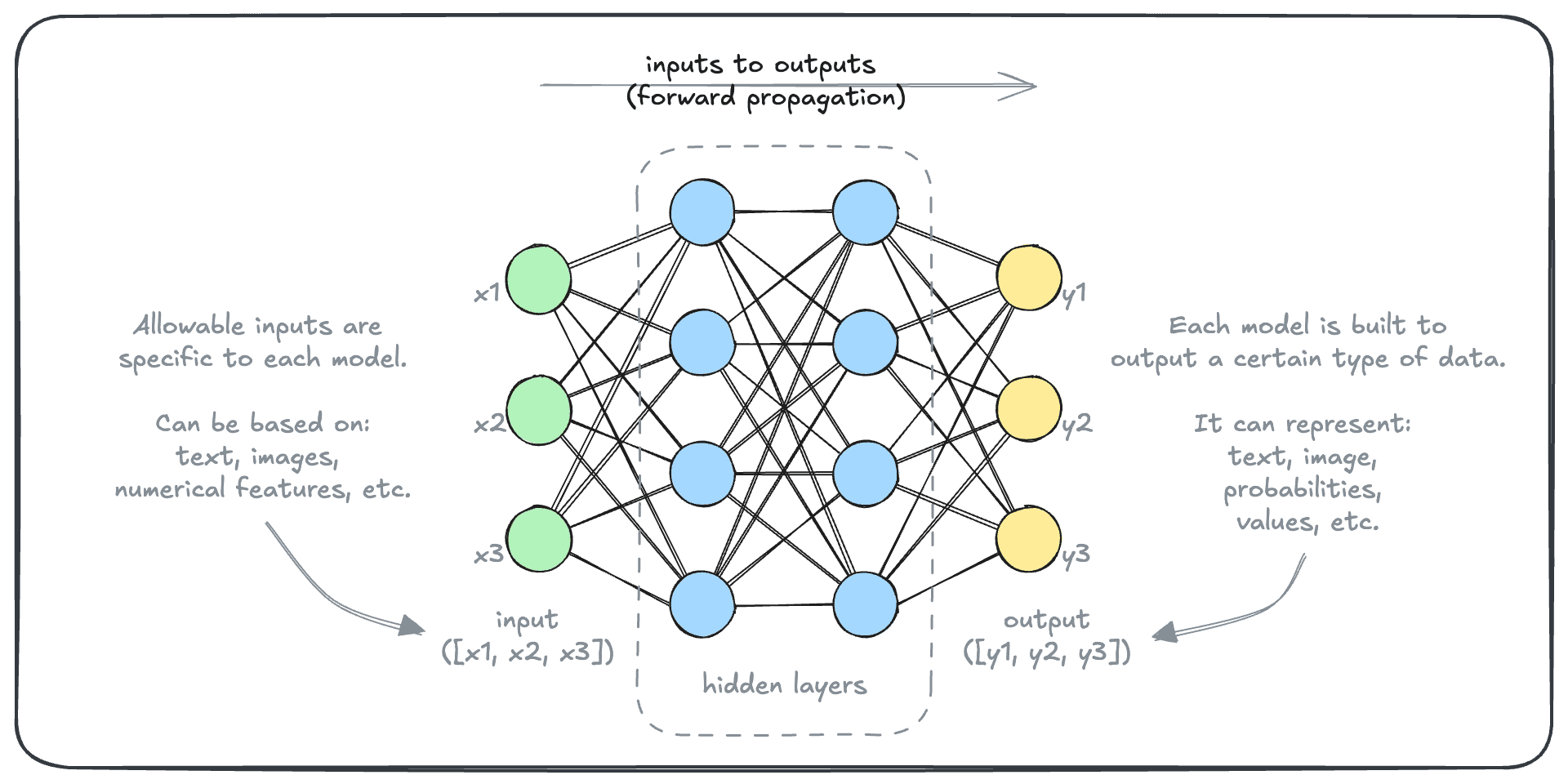
Deep learning models take a numerical input, transform it through its “hidden layers”, and produce a numerical output. But generative models turn input texts into output texts - seemingly a very different task.
There are two very important factors that allow generative models to do this. One is tokenization, and the other is auto-regressive generation.
Tokenization
Inputs to deep learning models are numerical while generative models take text inputs. Tokenization is the first step in converting text into a series of numerical values.
Take an input such as Explain tokenization like I am five.. A generative model may “tokenize” this input like so:

Each part is a unique “token”, which can be thought as a minimum unit of understanding for the model. The model can then replace each token with a unique integer. Once it adds a special token at the start and the end of the input, that sequence becomes the model’s input. The input might be:
[200264, 176289, 6602, 2860, 1299, 357, 939, 6468, 13, 200265]
Keep in mind that each model will have its own tokenizer that behaves differently.
Auto-regressive generation
At the opposite end, a generative model is configured to output one token. The architecture of a generative model thus looks like this:
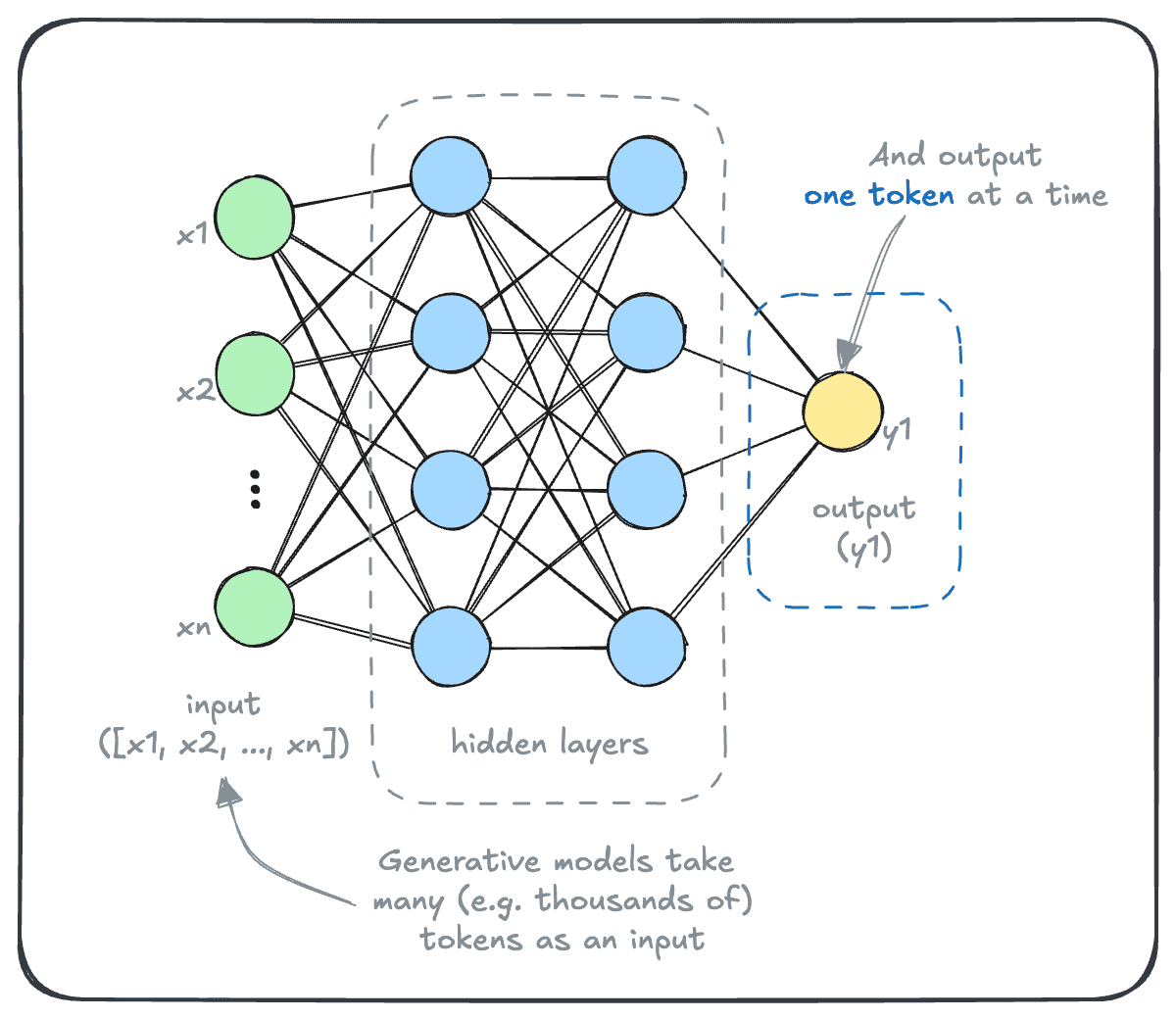
But, they don’t seem that way when we interact with them. Generative models can output texts of varying lengths.
How do generative models go from producing one token at a time, to seemingly producing a coherent sequence of text? As it turns out, most (text) generative models achieve this like how many of us perform difficult tasks - by putting one foot token in front of the other, as shown in the next diagram.
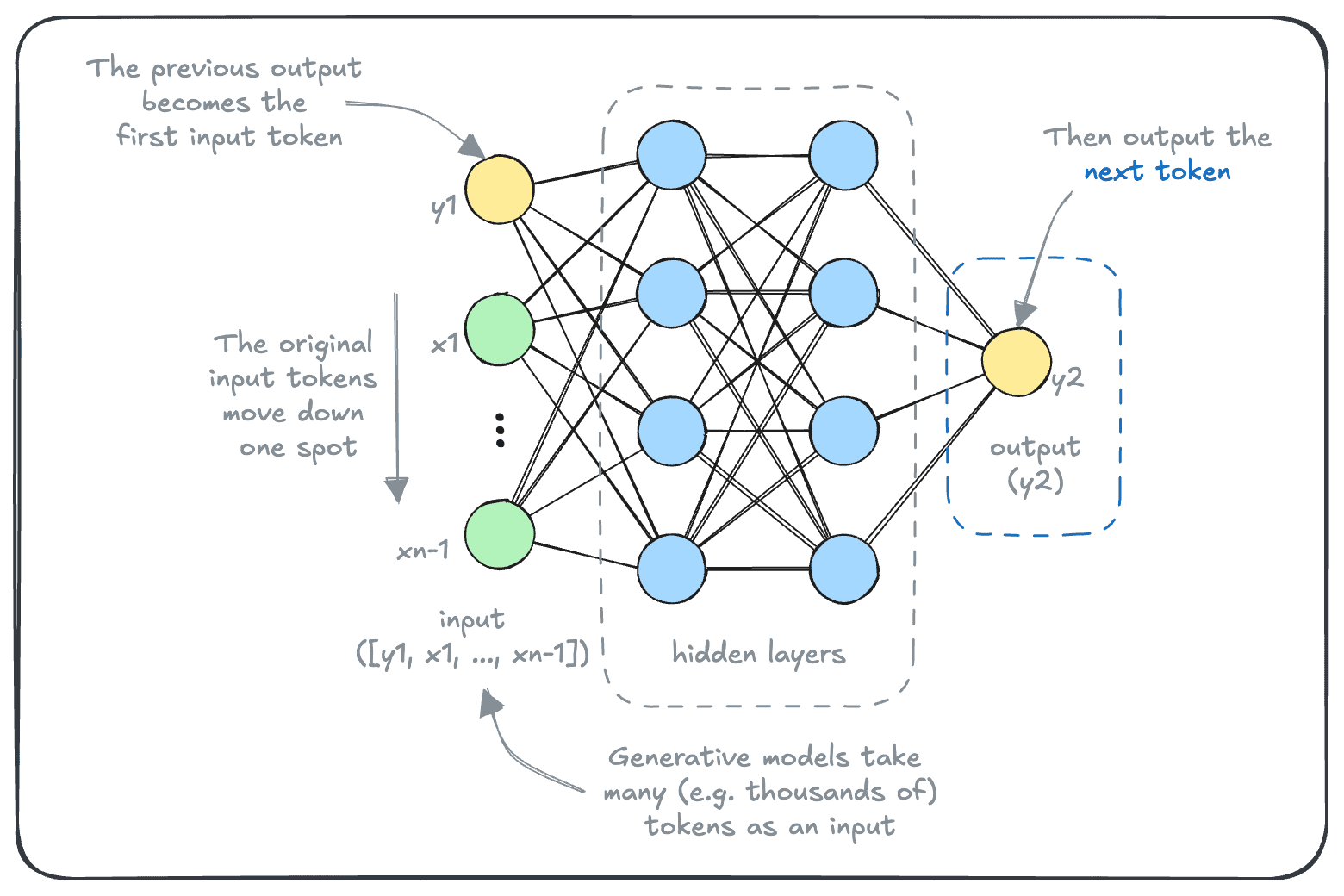
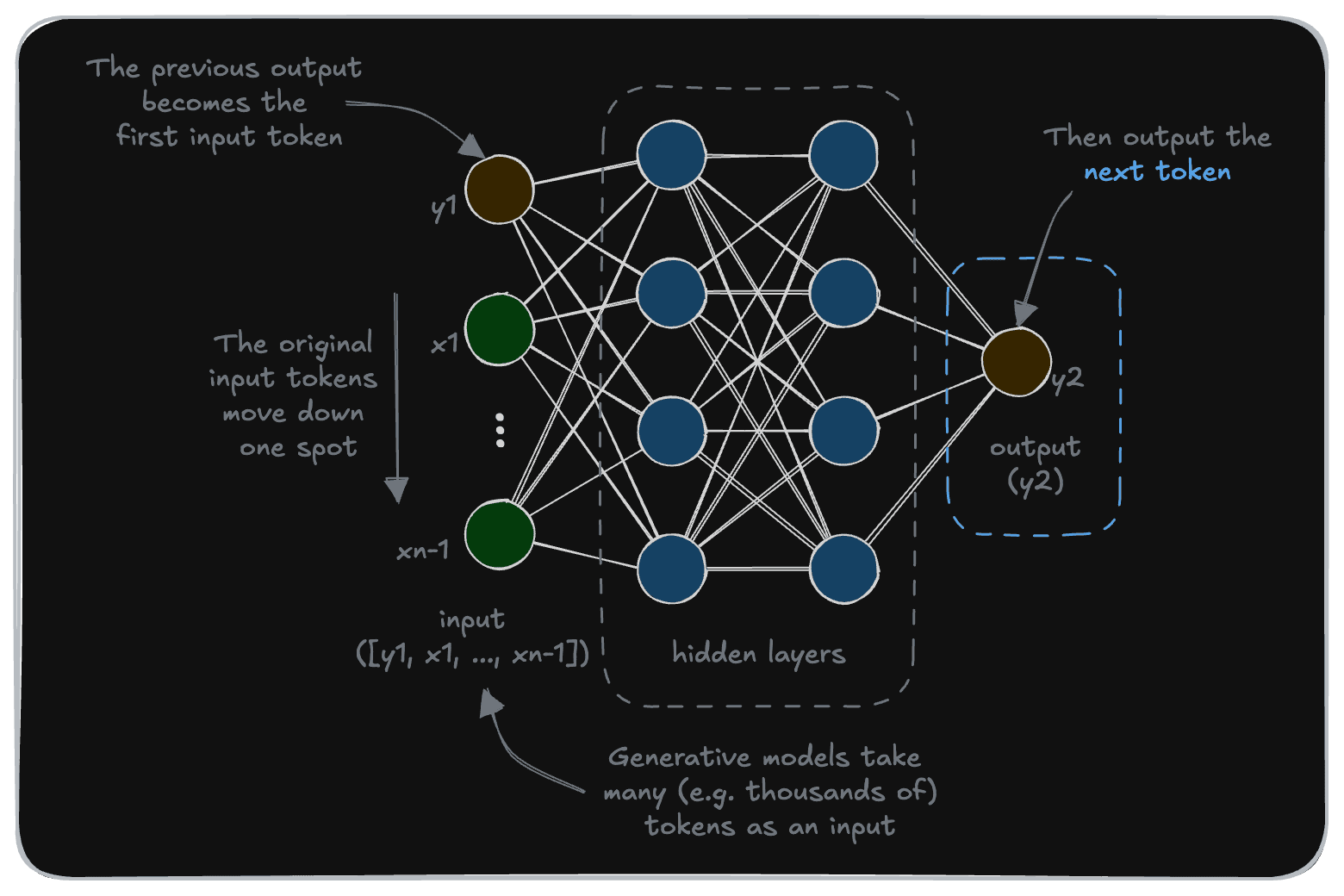
In a generative model, each generated token becomes a part of the input sequence, while the previous input sequence moves down by one spot (and the last one dropped). This continues onwards, until the model generates a special token indicating that it is finished generating.
This is how a model like gpt-4 can generate coherent answers to a question. Each token is based on the user input and all of the tokens generated up to that point.
So, when a model is said to have an allowable “context length”, it refers to the maximum length of input tokens ([x1, x2, …, xn]). And in many cases, the output length is also limited. This is so that the output tokens don’t cause the model to “forget” the initial input, as the autoregression part of the input grows larger.
Why use generative models?
By performing this simple task of generating one token in front of the other, generative models can perform a remarkable set of tasks at a very high level.
We’ve seen generative models demonstrate generalized capabilities across domains, such as:
- Write and debug code in multiple programming languages
- Converse with nuanced understanding
- Summarize complex documents or translate between languages
- Explain difficult concepts at various levels of complexity
- Create content from stories to marketing copy
Additionally, generative models can perform "zero-shot" or "few-shot" learning, meaning they can tackle tasks they weren't explicitly trained for with minimal or no examples.
This allows generative models to be used in place of specialized models in some cases, short-cutting lengthy model development processes.
Somewhat unbelievably, all these abilities are derived from the single goal that a generative mode has - to predict the next token.
As users of generative models, it is important to keep in mind that the model is simply performing pattern-matching, regardless of how impressive or complex it is, using its billions of parameters. This can help us to not imbue models with unwarranted magical qualities and to treat its outputs with healthy skepticism.
That is the basics of a generative model. We will learn more about these models later, such as discussing examples of these models, as well as model evaluation and selection. For now, let’s move on to learn about a different type of model, called an embedding model.
In this section, we largely talked about aspects related to large language models, where a text input is used to generate text outputs.
Many modern generative models are actually multi-modal. There are "vision language models" that can take not just text, but also images as parts of their inputs. And other types of generative models such as Stable Diffusion, or Sora can produce visual outputs, such as images or videos.
These models fundamentally work similarly to what was described above, but with modality-specific aspects that allow them to go even further.
Questions and feedback
If you have any questions or feedback, let us know in the user forum.