
AI models in general
A big percentage of modern AI models are deep learning models. Many generative and embedding models fit into this category, as do many regression models or classification models.
So, let’s take a look at some of their common features.
Deep learning models
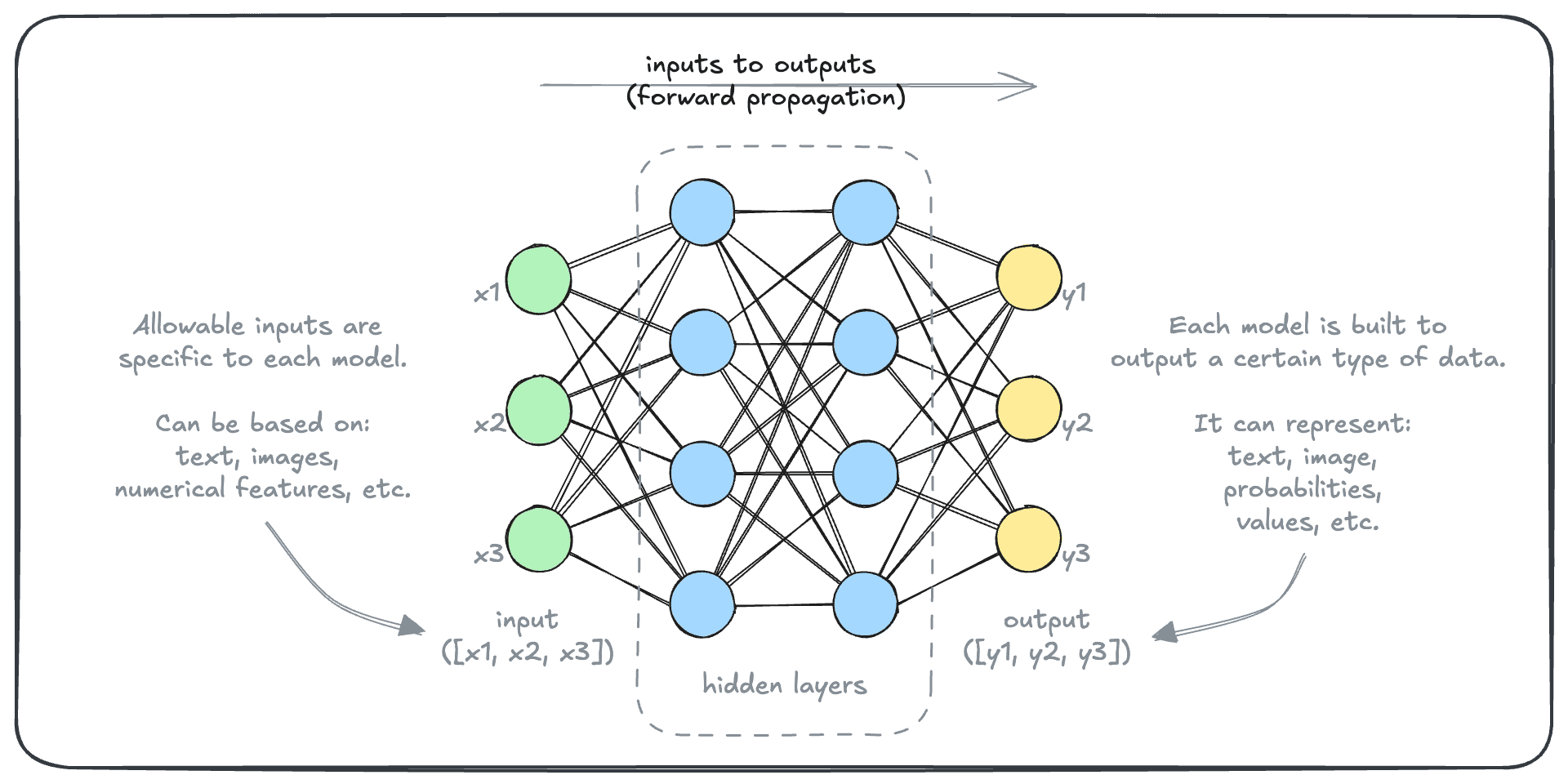
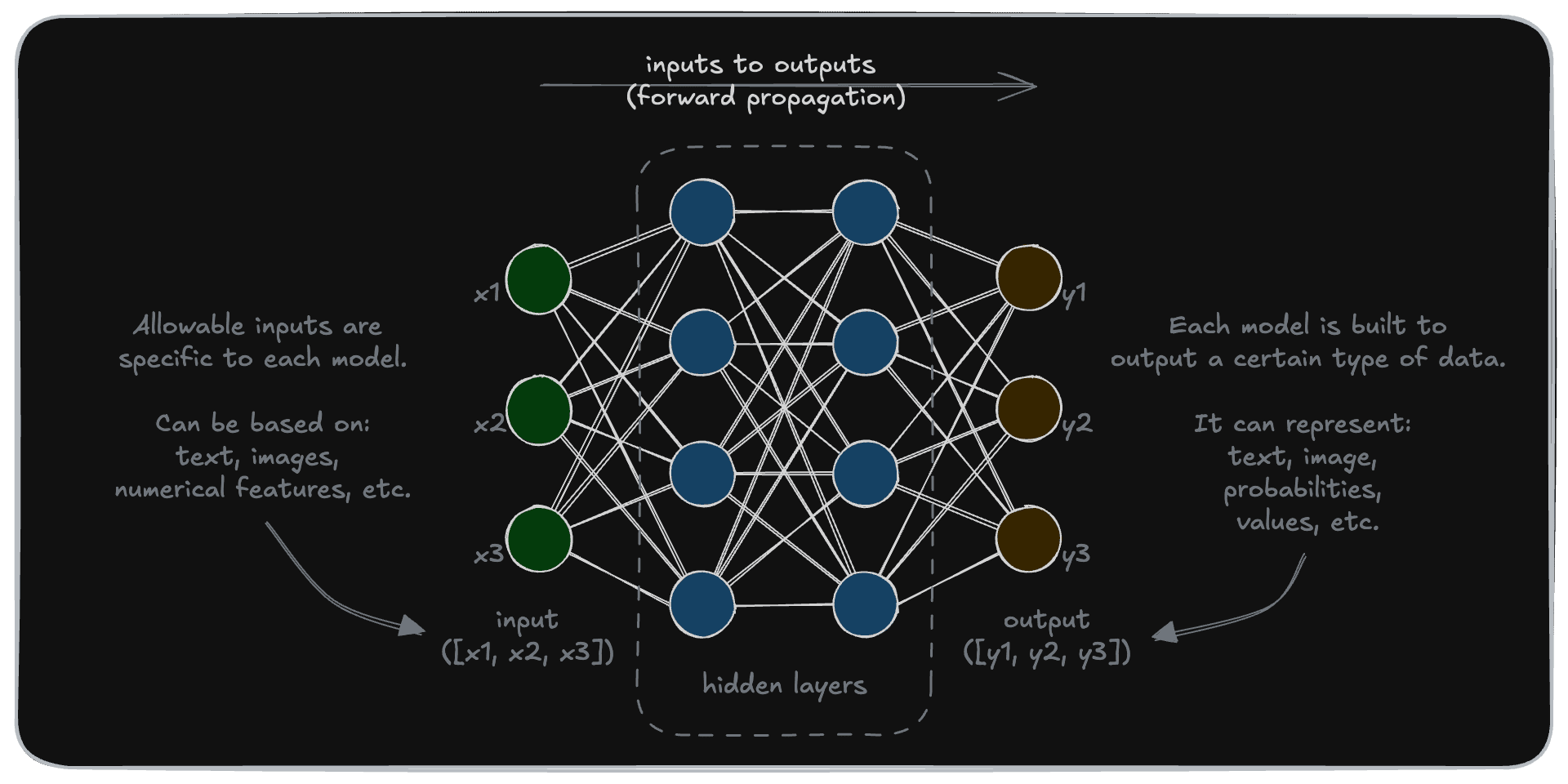
You may have seen a visual representation of a deep learning model like this.
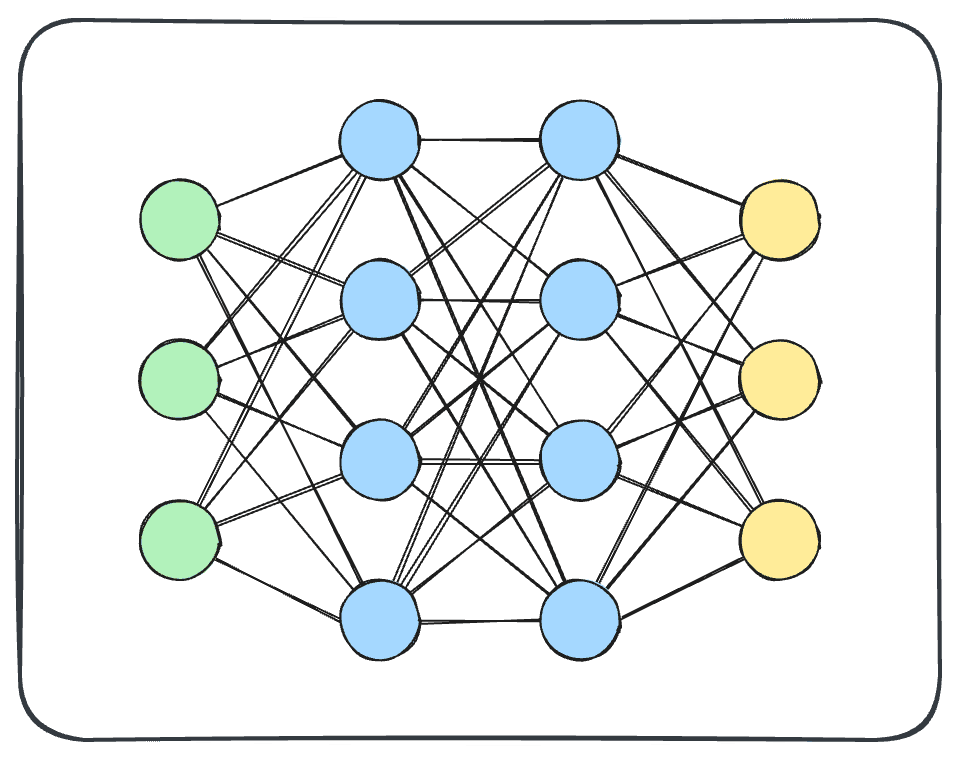
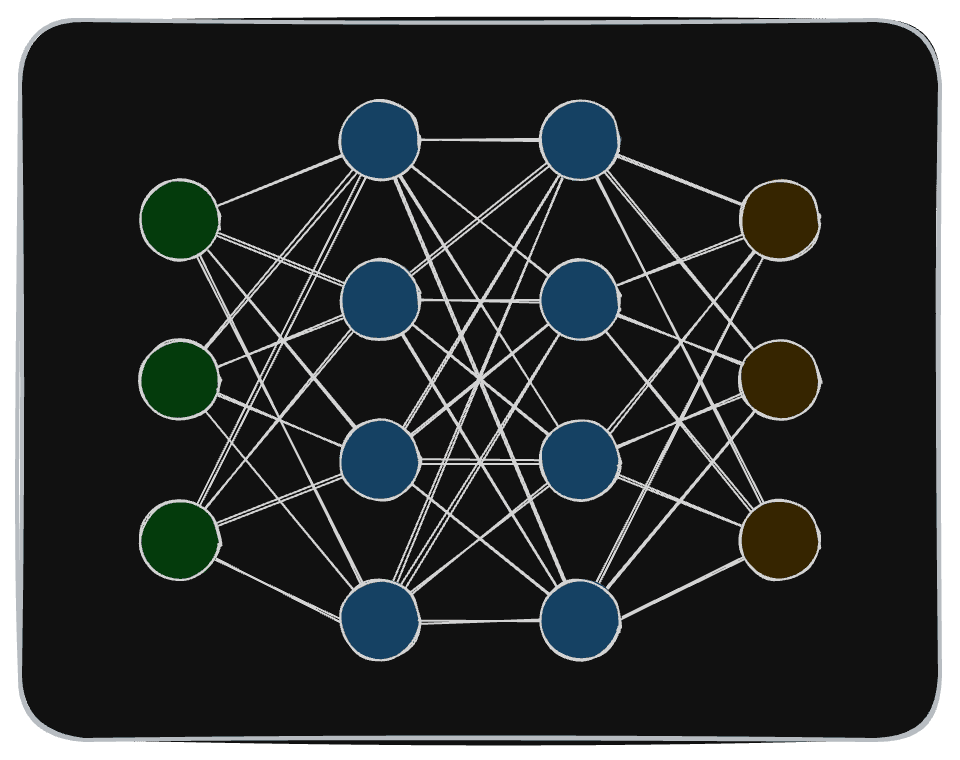
This might not look like much, but it’s actually quite an accurate representation of a deep learning model. Let’s dive into the details.
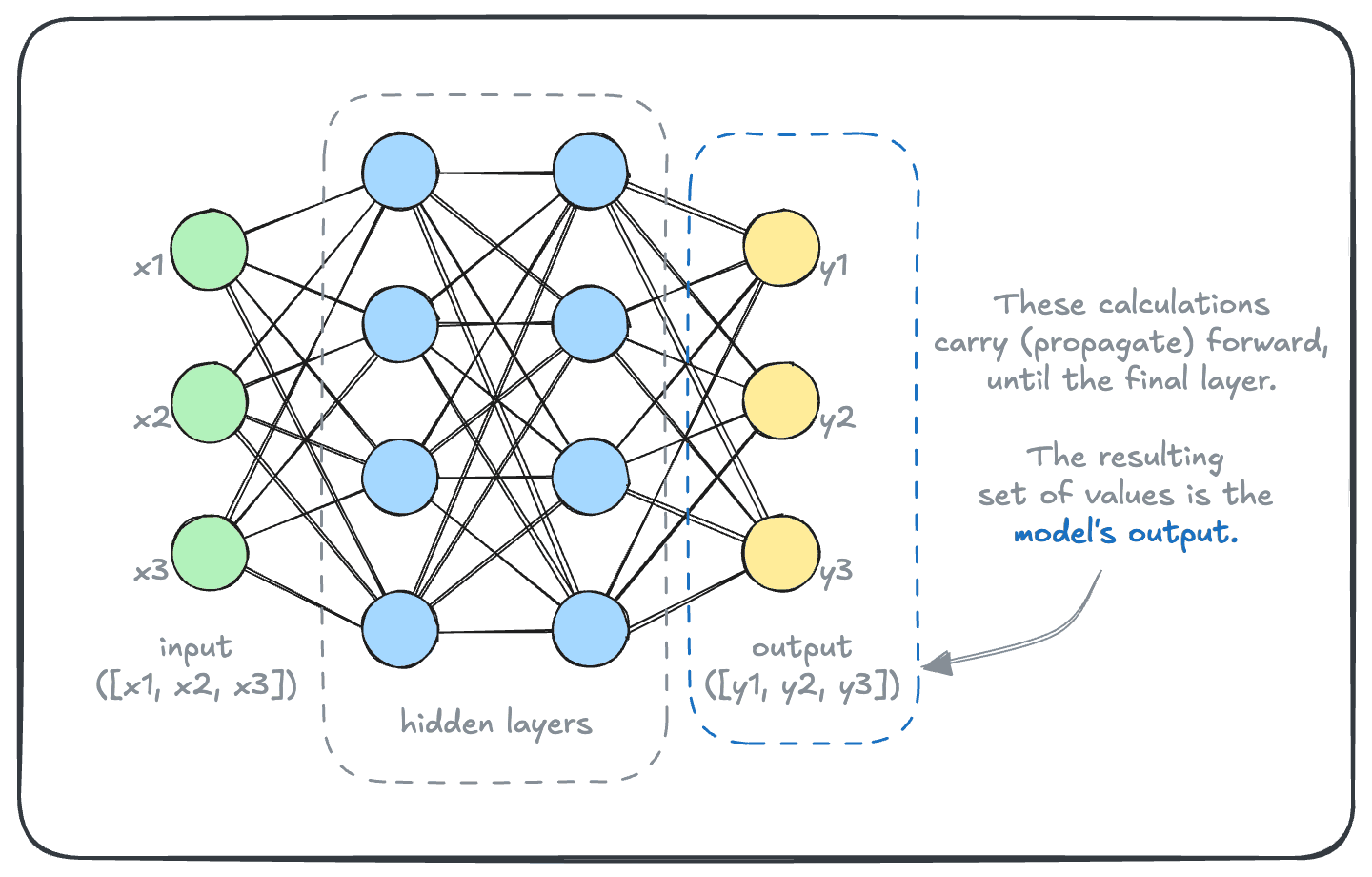
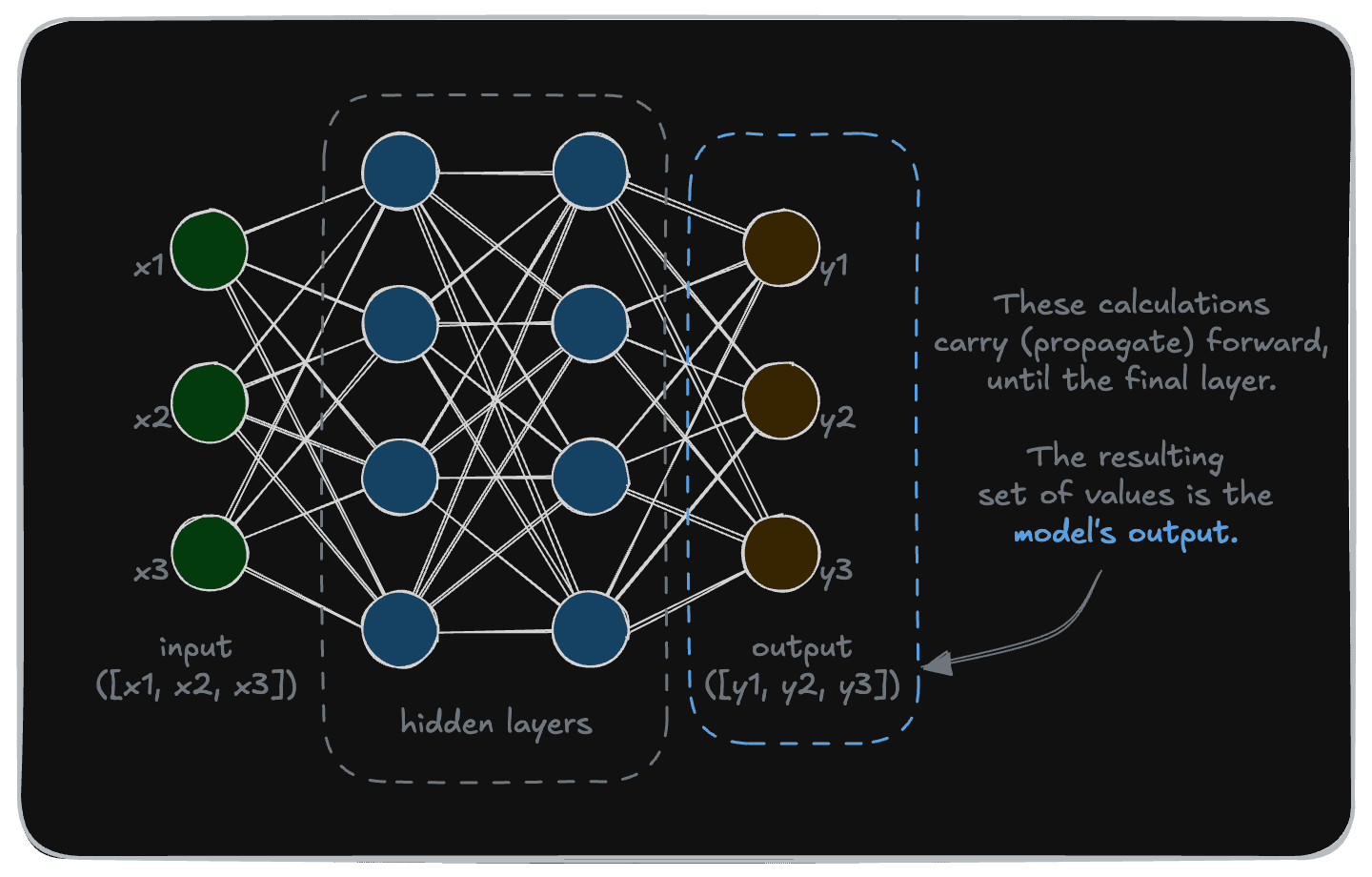
If we were to add details to this diagram, it may look like this. The model takes some input (array [x1, x2, x3] in this example) and transforms it to an output (array [y1, y2, y3] in this example).
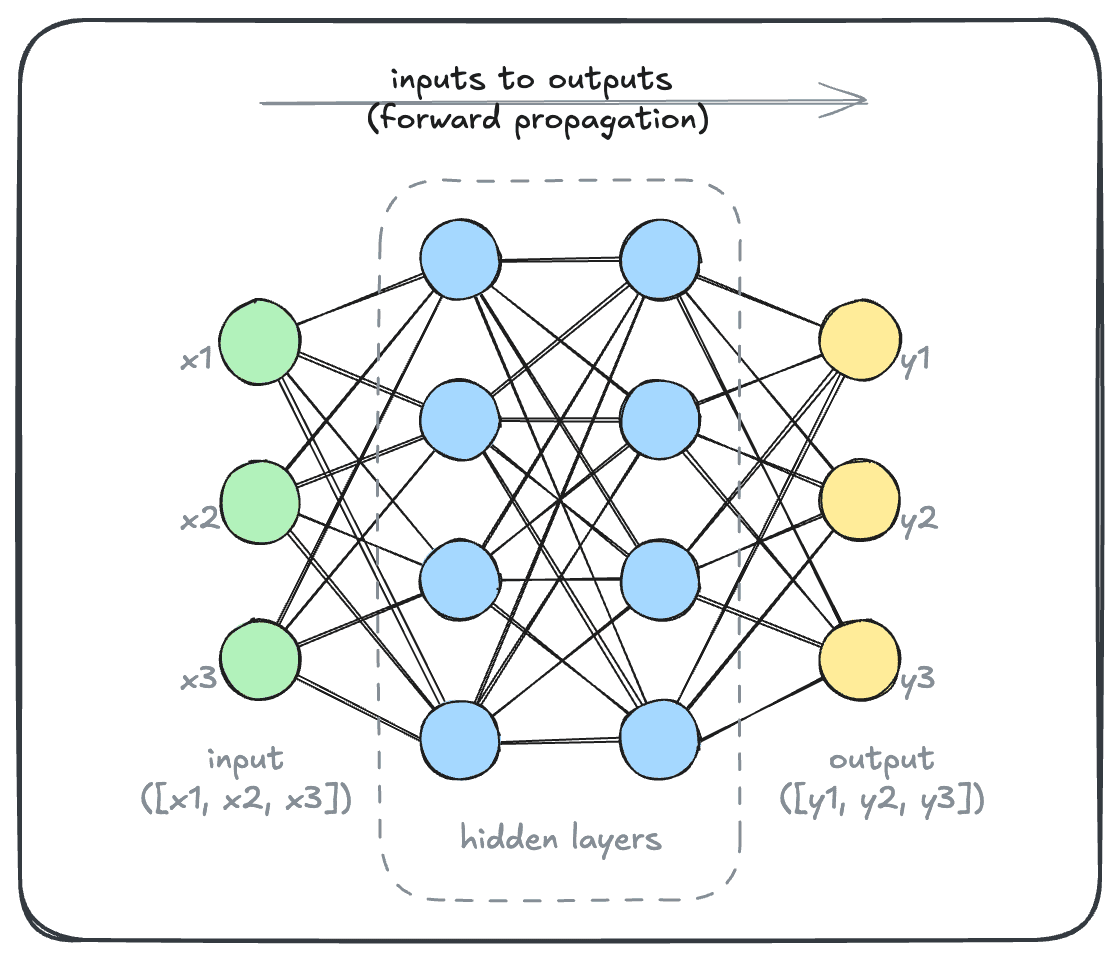
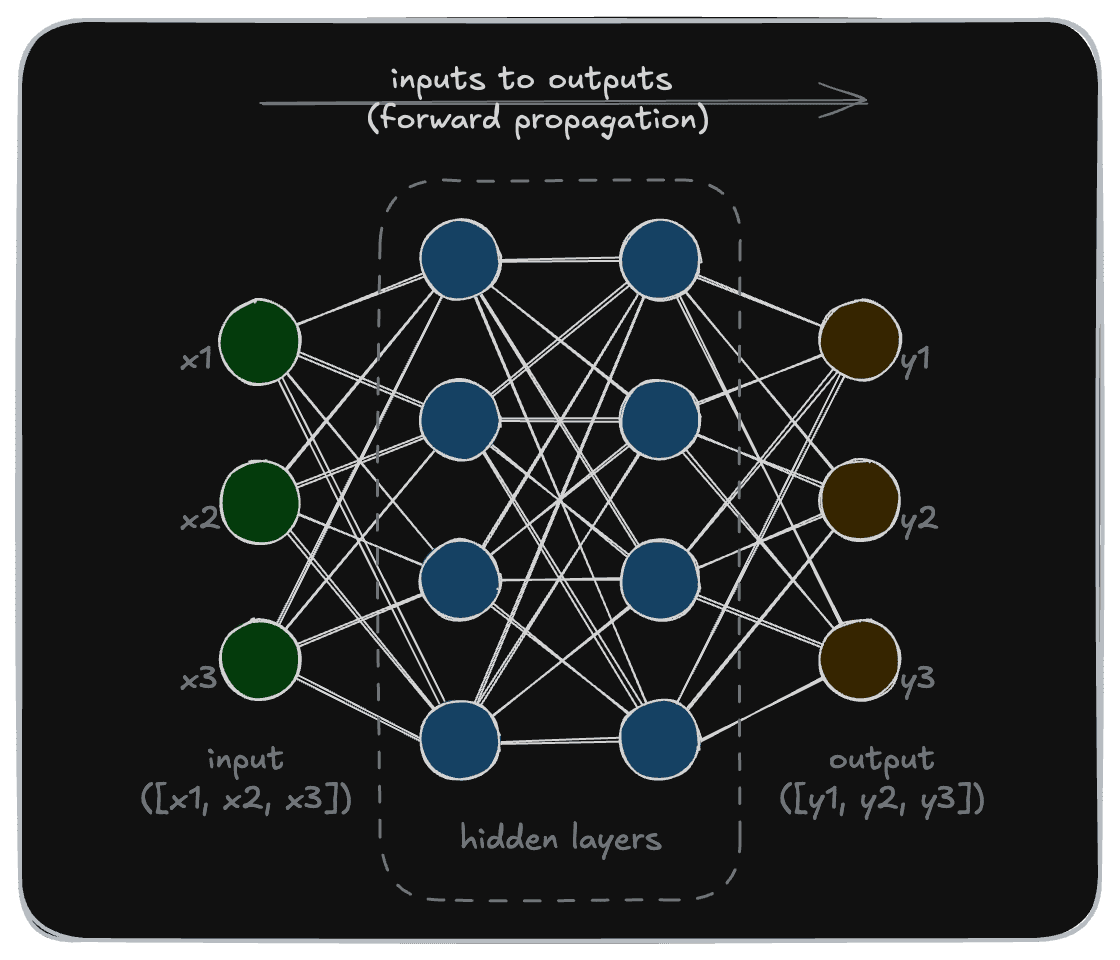
This transformation is carried out by a set of “nodes”, typically called the “hidden layers”.
Inputs and outputs
We mentioned above that the inputs and outputs can be in a variety of formats, and represent a range of different aspects. And that’s exactly the case here.
While the example shows an array of three values as an input and the output, the inputs and outputs can comprise any length of values.
A regression model may take inputs such as [<number of rooms>, <postcode>, <house size>, <house type>, <land size>, <number of garages>, <house age>, ...] and output a value in dollars. A classification model, on the other hand, might take in the same inputs but instead output an array of probabilities like [0.05, 0.65, 0.20, 0.10], representing the likelihood of the house falling into different price brackets such as "budget," "mid-range," "luxury," or "premium luxury."
One restriction of these models is that both inputs and outputs must be numerical. This is so that these inputs can be transformed into outputs. (We will discuss how to represent objects such as texts, or image inputs as numbers.)
So, how do these models convert inputs into outputs, exactly? As it turns out, through a series of calculations such as those shown below. This diagram shows how the value of a particular node (h11, for node on row 1, column 1) is calculated.
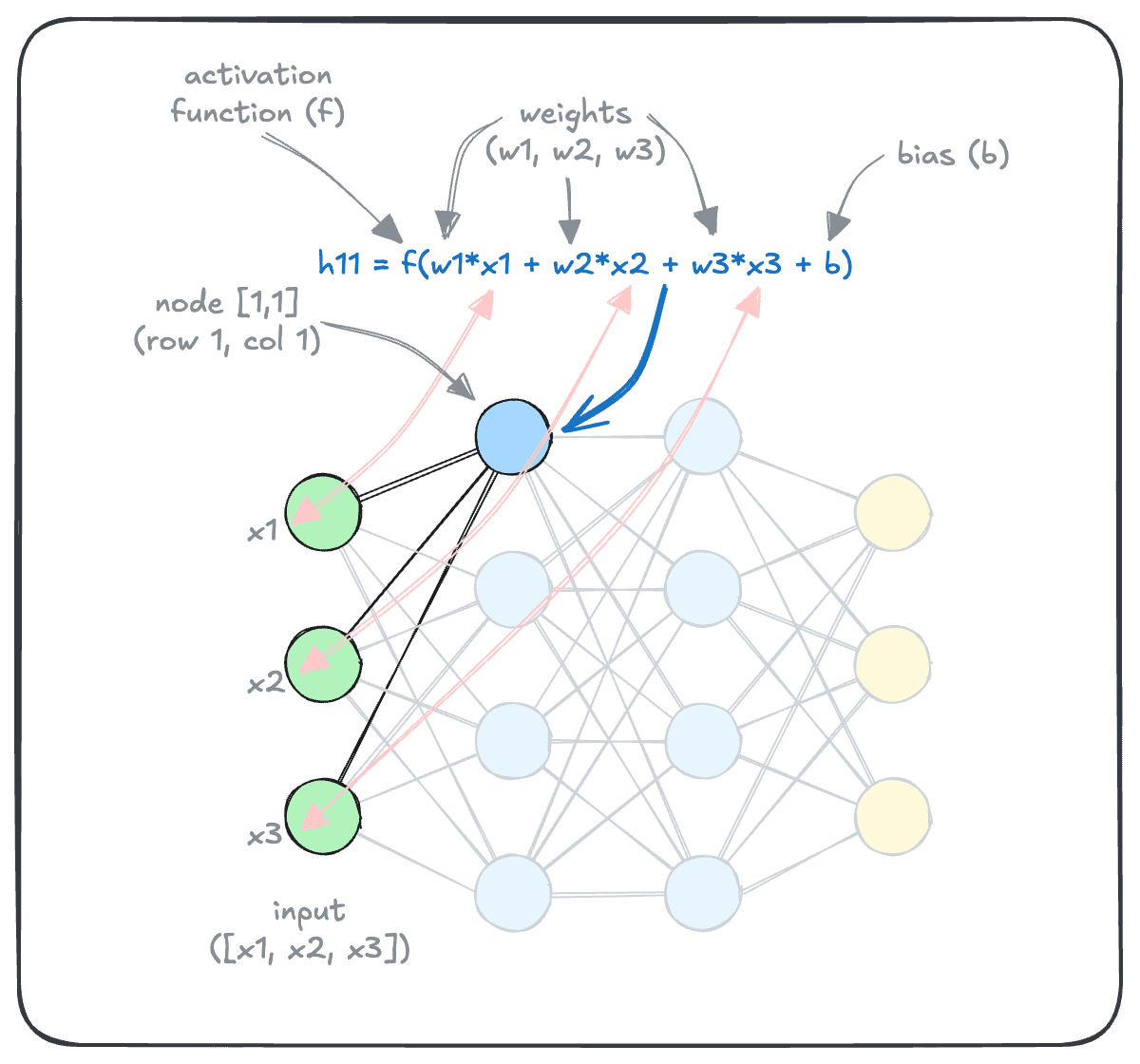
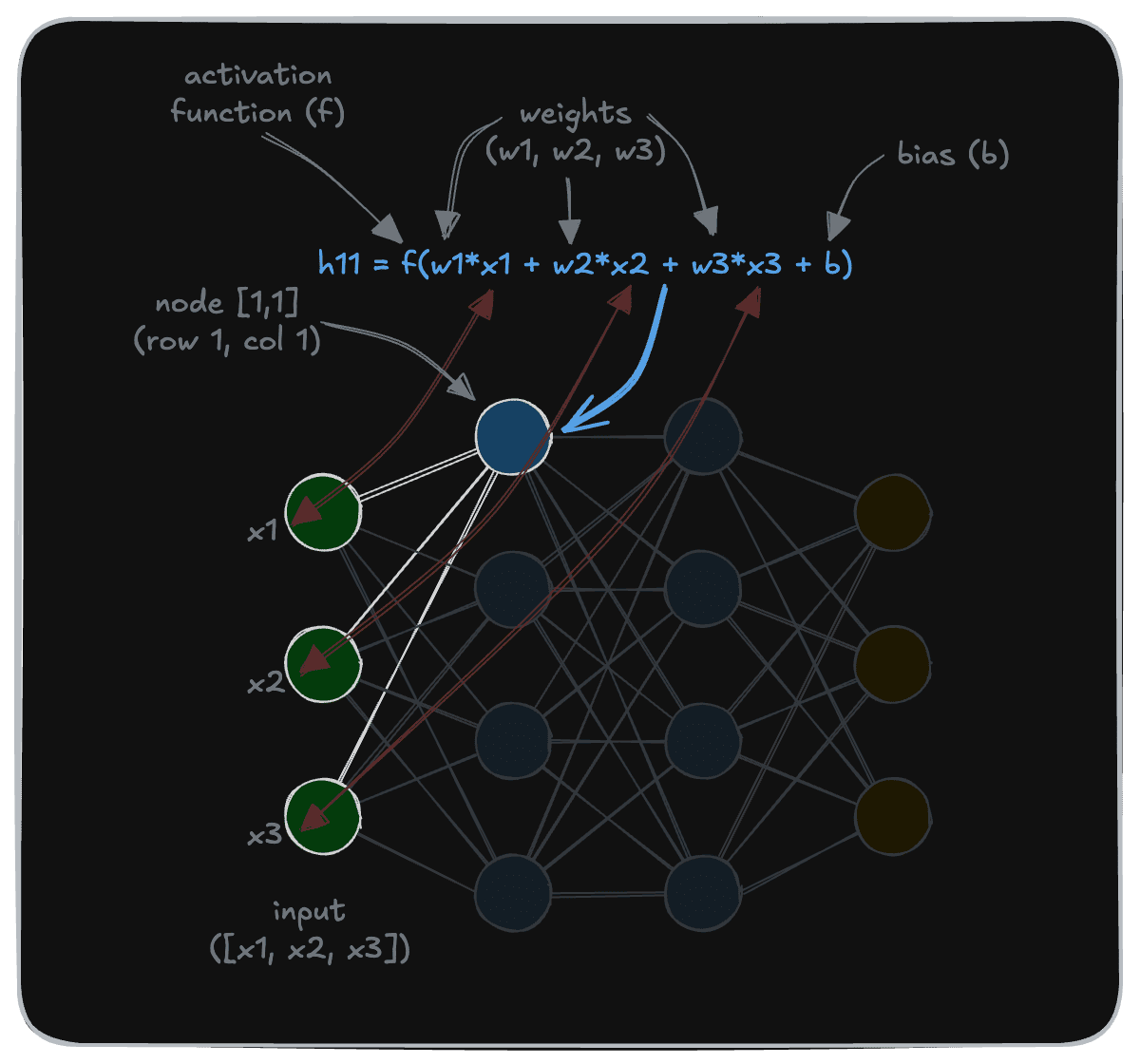
As you can see, the calculation is relatively simple. Some form of linear algebra is performed to calculate the value of the node from values of the connected nodes from the preceding layer. This is where the “weights” and “biases” are applied in carrying the values forward.
Then, an “activation function” is applied to introduce non-linearity, allowing the network to learn complex patterns. This enables AI models to capture the sophisticated relationships in data that would not be possible only with combinations of linear layers. (In fact, without activation functions, the additional layers will simply be wasted!)
And that’s really all a deep learning model does. Except - it does it at scale.
Parameters
As you can see here, each node’s value is determined by the previous layer, and its weights and biases. Each of these weights and biases is called a parameter. Sum up all the parameters in a model, and we have the model’s parameter count, which is used as a shorthand for the model’s size.
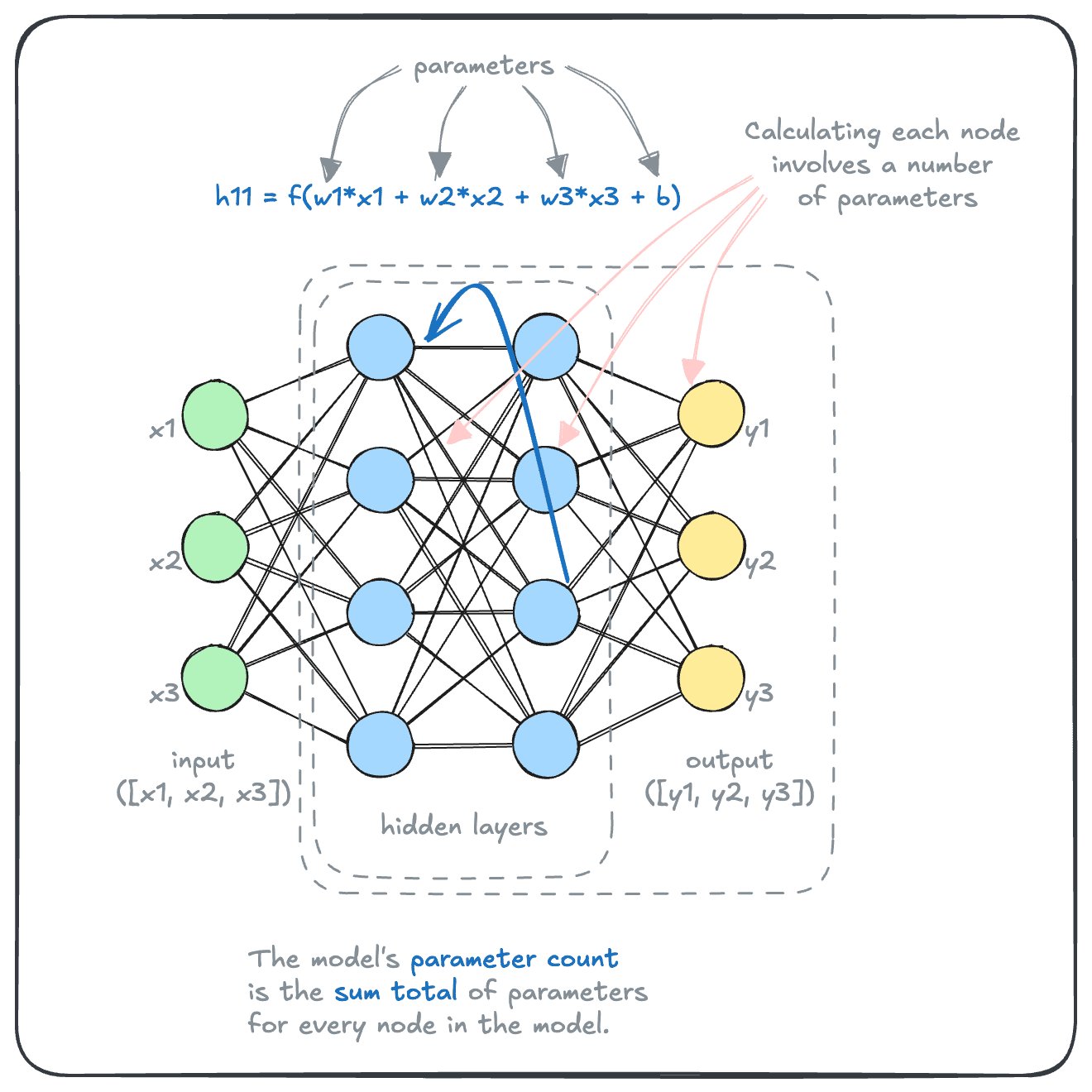
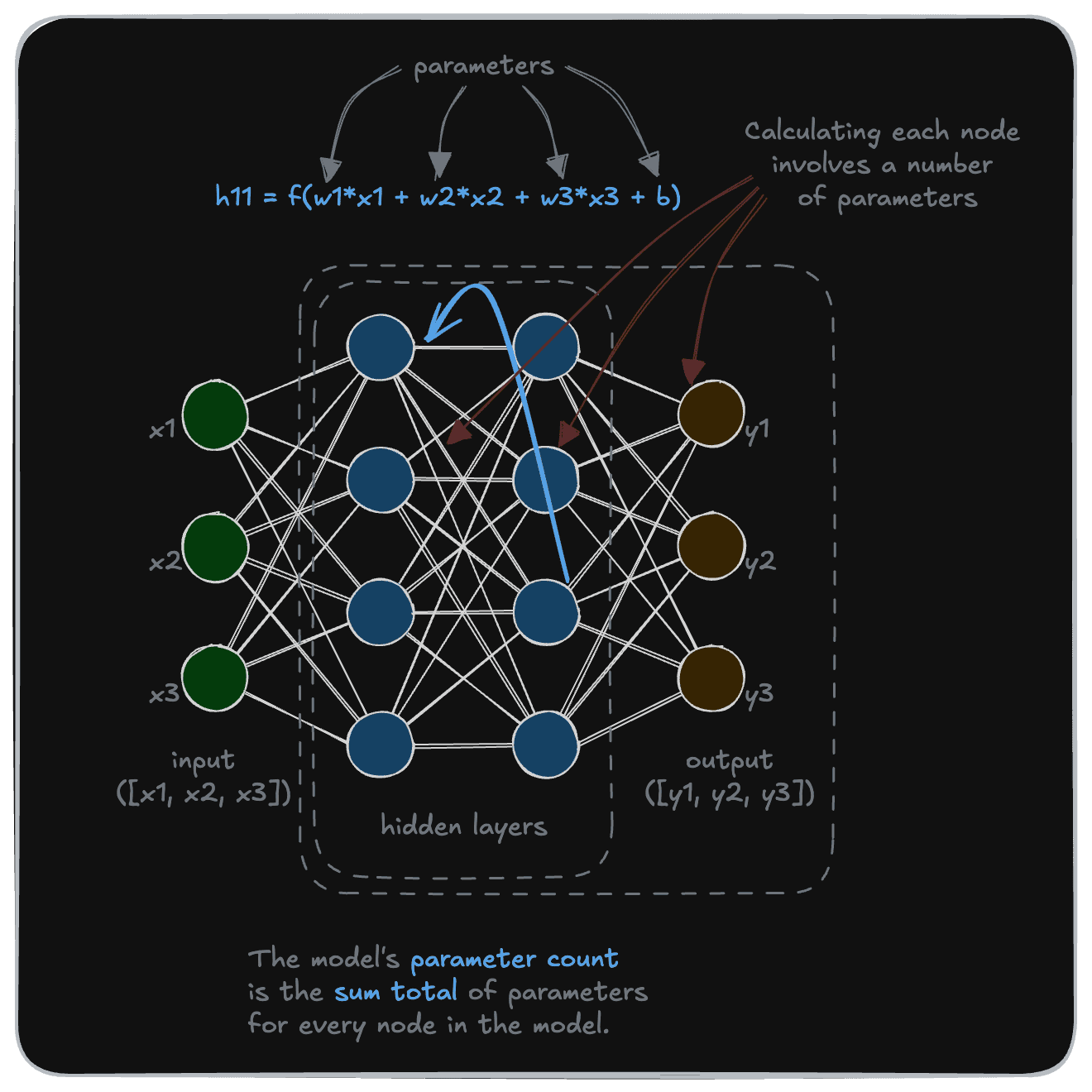
Large AI models have billions of these. The largest version of Meta’s Llama3 models has 405 billion parameters, and the original GPT-4 model was rumored to have ~1.8 trillion parameters.
And that is how a model turns a bunch of inputs into outputs under-the-hood.
As it turns out, once a model is given enough parameters, these parameters can be tuned to imbue these models with incredible power.
Not quite. Even if you weren’t building and training these models, using, larger models involve overhead. Larger models require more resources (memory) to run, slower to generate outputs, and are therefore more expensive. While larger models may be more capable on average, it may be possible to find smaller models that work just as well for a given purpose.
We will discuss this a lot more in a later section related to AI model selection.
Now, it may seem somewhat intuitive that a model can take a series of numbers describing features of a house, and predict its value (regression) or the probabilities of it belonging to a particular class.
But how does this concept lead to generative AI models such as gpt models, or embedding models? It’s actually more similar than you might think.
Let’s take a look at this in the next section.
Questions and feedback
If you have any questions or feedback, let us know in the user forum.