
Navigating the landscape
Access mode selection
When it comes to deploying AI models in your applications, choosing between commercial inference providers and local inference is a good step to narrow down your range of choices.
Each approach has distinct advantages and trade-offs that should be considered based on your specific use case.
Inference service providers
Examples: AWS, Cohere, Google, Microsoft Azure, OpenAI, etc.
Advantages:
- No infrastructure management or hardware investment required
- Access to proprietary, provider-specific models
- Regular model updates & improvements
- Automatic scaling to handle varying workloads
Disadvantages:
- Generally higher costs than local or self-managed inference
- Data privacy considerations (data leaves your environment)
- Dependency on third-party service availability
- What happens if the provider ceases to operate
- Limited customization options
Local Inference
Example: Hugging Face Transformers / Accelerate, llama.cpp, Ollama, PyTorch Serve, TensorFlow Serving
Advantages:
- Control data transmissions
- No internet dependency for inference operations
- Ability to deploy custom trained models
Disadvantages:
- Higher upfront costs for hardware procurement
- Unlikely to be able to access the latest, most powerful models
- Responsibility for model updates and maintenance
- Potential performance constraints based on available hardware
Decision Factors
Consider the following questions when making your selection:
- Data sensitivity: Does your application process confidential or regulated data? If your data cannot leave your premises, this may limit your options to particular inference providers, or local models.
- Inference volume: How many requests do you expect to process daily/monthly? For many, the up-front costs for local models may be prohibitive.
- Latency requirements: How time-sensitive are your model responses? If this is high, it may preclude many small-scale users from using local models.
- Budget constraints: Is your priority upfront savings or long-term cost optimization?
- Technical resources: Do you have the expertise to manage local model deployment, and potentially training?
Note that there isn’t a one-size-fits-all solution.
However, it may be that for getting started, using a commercial inference provider may be an easier, lower-friction choice.
How to read model cards
Model “cards” are to AI models what product labels or specification sheets are to regular products.
Model cards are supplied by the model provider to help you understand what the model is and how to best use it.
Examples of model cards
Model cards come in a variety of formats. See, for example, the following cards for embedding models:
- https://huggingface.co/Cohere/Cohere-embed-english-v3.0
- https://docs.cohere.com/v2/docs/cohere-embed
- https://huggingface.co/Snowflake/snowflake-arctic-embed-l-v2.0
And some cards for generative AI models:
- https://huggingface.co/meta-llama/Llama-3.3-70B-Instruct
- https://ollama.com/library/llama3.3:70b
- https://ai.google.dev/gemma/docs/core/model_card_3
- https://build.nvidia.com/microsoft/phi-4-multimodal-instruct/modelcard
Even from this small selection, you can see that these cards vary according to the hosting site and the model provider. This volume of information can be overwhelming, especially at first.
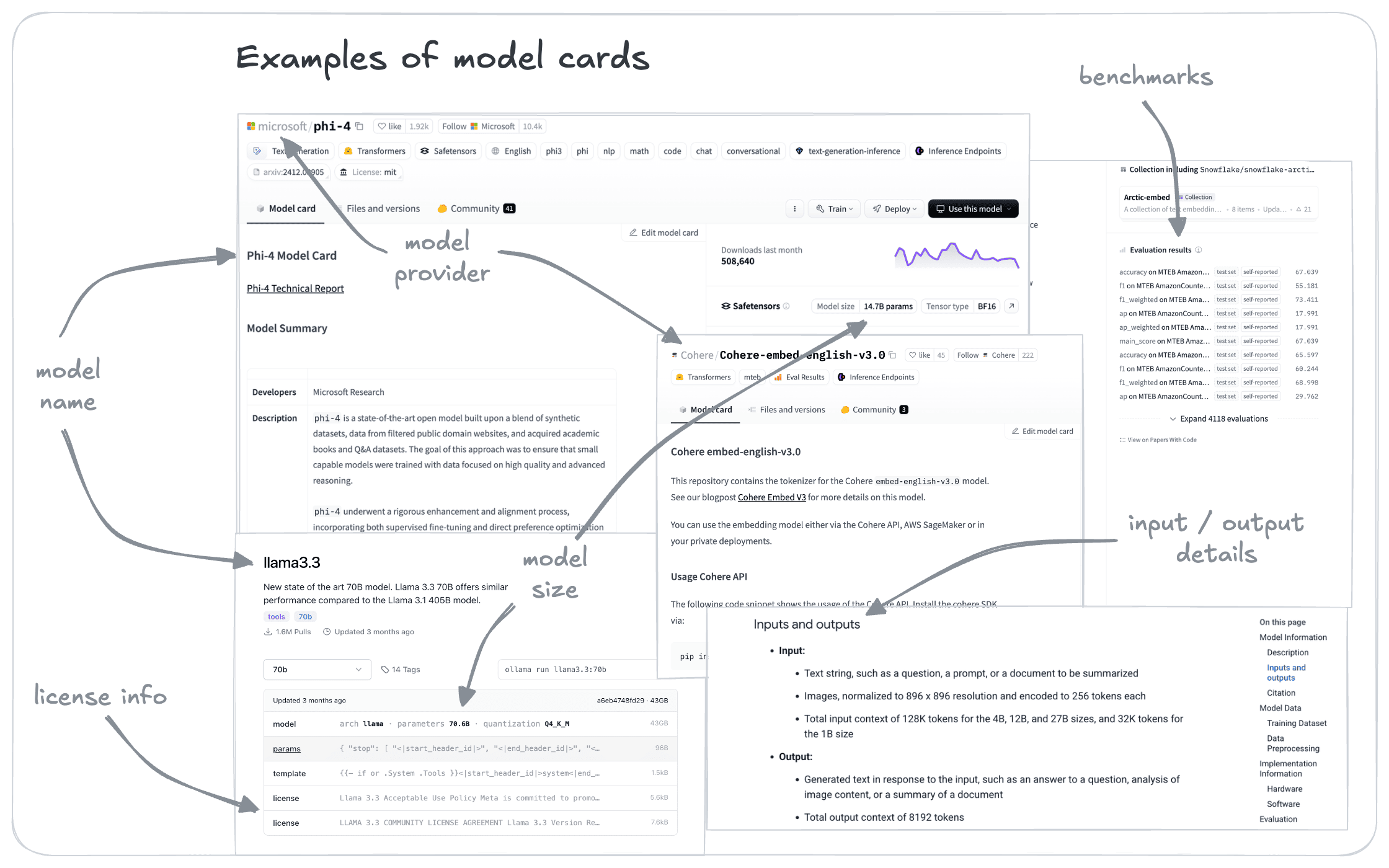
We will get into these in more detail in later courses. But here are some key parameters to look out for.
- Basic model information
- Model name and version
- Model type (generative, embedding, etc.)
- Model size (parameter count) and architecture
- Training data overview
- Costs, if accessed through an API, or hardware requirements
- Technical specifications
- Dimensionality (for embedding models)
- Context length (for generative models)
- Supported languages or modalities
- Performance metrics
- Benchmark results
- Known strengths and limitations
- Downstream performance
- Usage information
- Intended use cases
- Implementation guidelines or code snippets
- Legal and ethical considerations
- License type and usage restrictions
- Potential biases or fairness considerations
Just reviewing these parameters will take you a long way towards identifying models that will suit your needs.
In the absence of other information, a good starting point would be to filter for:
- The right model type
- Suitable modality, language and context length or dimensionality
- Ability to access model (inference provider / local inference)
- License suitability
Then, select candidate models from a reputable model provider, or based on their benchmark performance.
Ultimately you may wish to evaluate the model’s, and your application’s, performance yourself.
But following these simple heuristics will get you a long way towards selecting a good baseline model or a set of baseline models.
Questions and feedback
If you have any questions or feedback, let us know in the user forum.