
Briefly: Model training
In this section, let's very briefly discuss how AI models are trained. This is a critical part of understanding how AI models work, and how they can be used. We will not go into the details of training, but rather provide a high-level overview to help you understand the process.
What is model training?
So far, we’ve learned that AI models, or more specifically, deep learning models, work by applying a massive number of transformations to an input to produce an output. These transformations are primarily applied through weights, biases and activation functions, as shown below in an example calculation for a node.
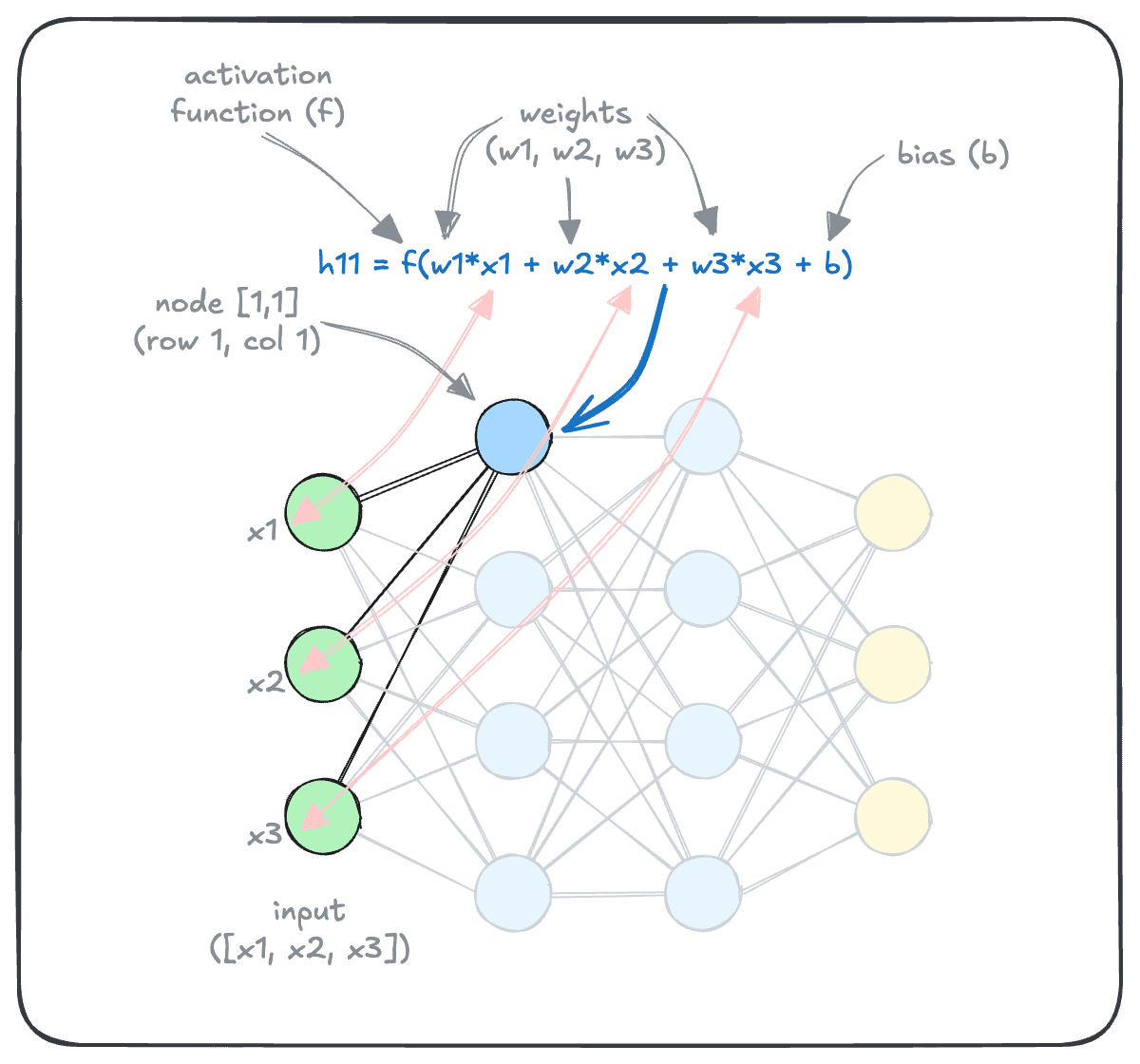
We also learned that the weights and biases are collectively called parameters of a deep learning model. As the name indicates, parameters define the behavior of a deep learning model (in contrast to the architecture of a deep learning model).
Parameter: n. an arbitrary constant whose value characterizes a member of a system
Source: Merriam-Webster DictionaryTwo deep learning models, even with the same architecture, can have different parameters to perform a different job.
Given that these models commonly have millions, or billions, of parameters, it is basically impossible to hard-code these parameters to achieve the desired goal. Instead, these parameters are “trained” numerically, which is what leads them to be called “deep learning” models.
How are models trained?
The training at a high level is just like any other machine learning model. To a layperson, it is similar to “goal seek” in Microsoft Excel, or even more basic, the “hot and cold” game.
In deep learning, each training “iteration” is used to compare the model’s output to the “ideal” output (this is called a “loss function”). Then, a lot of fancy math is used to update the parameters such that the model gets a little bit better at its job.
We used the term “fancy math” to whimsically indicate that there is a lot of complex mathematics as well as computation involved. This is, of course, an extremely interesting and important area of AI.
The key here is to use “gradient descent”, to update parameters over time using numerical differentiation of the loss function. This technique calculates the direction in which parameters should change to reduce the model's error, and then makes small adjustments in that direction.
But it is slightly outside the scope of our discussion here, and perhaps not as critical for those looking to simply use models. If you are interested in learning about model training in detail, there’s a lot of great resources out there.
Here are a couple of our favorites:
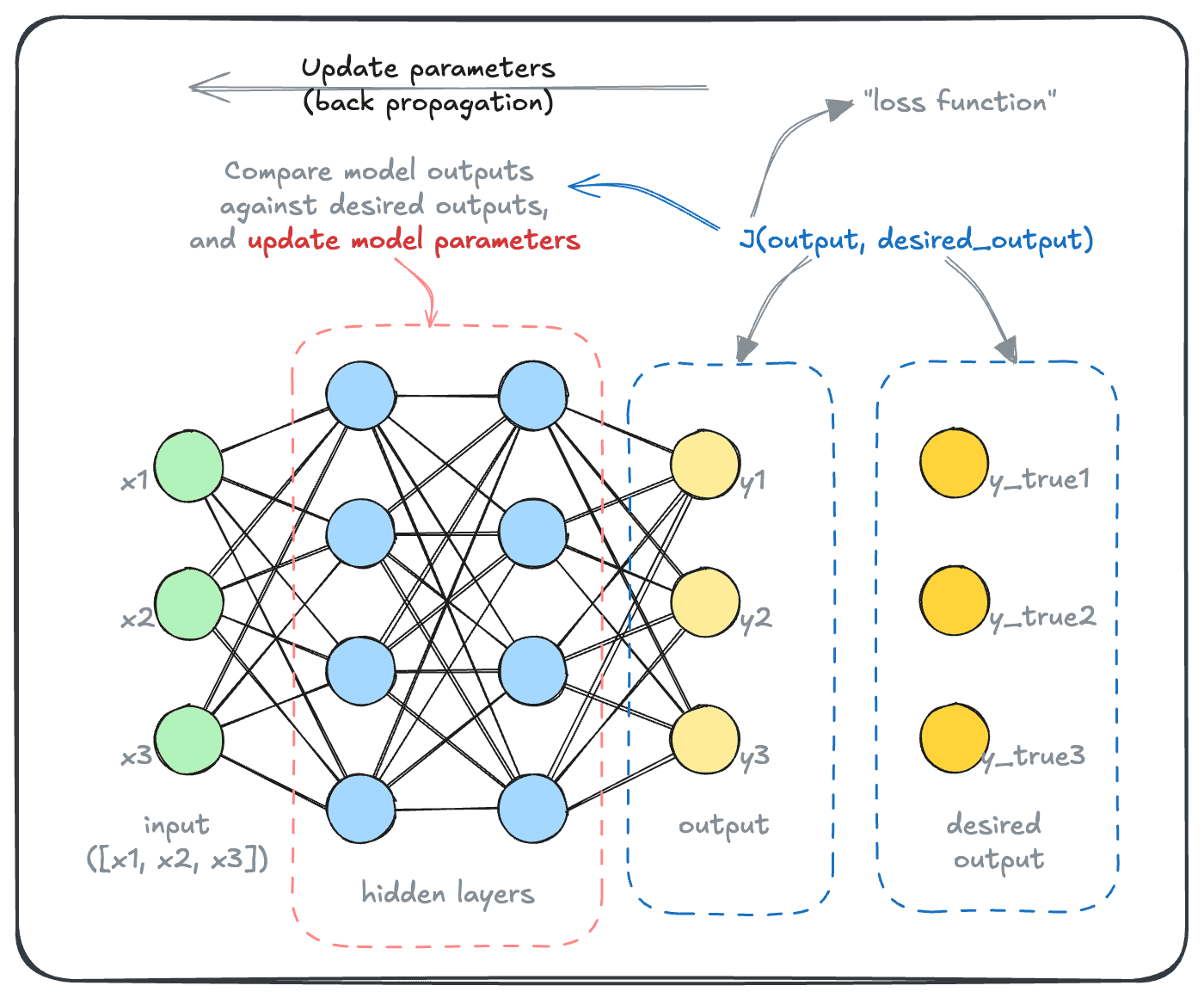
You will see that this process works backwards, propagating the learnings from the model output back to the parameters. That’s why this is called “back propagation”, or “backprop”.
In a model training process, this type of update would be one “iteration”. Many, many, such iterations are carried out throughout the lifecycle of model training. It is the combination of the large size of these models, and the number of iterations required for training that makes it so expensive, and time-consuming, to train these models.
Models: Build vs. buy
Training a large language model from scratch can take months and cost millions of dollars in computing resources. Modern GPUs are uniquely suited for this application, which is why they have been in high demand in the recent past.
Modern AI models are trained in multiple stages, called “pre-training” and “fine-tuning”. A simplified explanation is that pre-training gives a model its general capabilities, while fine-tuning adapts it for specific domain or application capabilities.
In a majority of cases, users will be selecting models off-the-shelf, although fine-tuning a model can be a good solution for the right use case, as long as it is done with the sufficient expertise and goal in mind. We will discuss this more in our later section on model evaluation and selection.
Next, let’s start to get into how these models can actually be used. We will look at how to access such models, such as through commercial inference providers or by performing local inference. And we’ll review their pros and cons, as well as begin to interpret details of various models by reading model cards.
Questions and feedback
If you have any questions or feedback, let us know in the user forum.