
Detailed evaluation
Introduction
After identifying your needs and compiling a shortlist of candidate models, you can perform a thorough evaluation. The goal of this stage is to collect concrete evidence to support embedding model selection for your specific use case.
When evaluating embedding models, it's important to distinguish between two types of evaluation:
- Model evaluation: Focuses on assessing the embedding model itself through direct metrics. This typically involves measuring performance on standard benchmarks or custom tasks designed to match your specific use case.
- Downstream evaluation: Examines how the embedding model performs within the larger system or application, such as a RAG pipeline or recommendation engine.
Both types of evaluation are important, but they serve different purposes. Model evaluation helps you understand the intrinsic capabilities of each embedding model. On the other hand, downstream evaluation shows how those capabilities translate to real-world application performance as a system.
In this guide, let’s focus on model evaluation. This is to help you make initial selections while building your AI powered applications. We will discuss downstream, or system-level, evaluation at a later time.
We will start this with model evaluation through standard benchmarks.
Standard benchmarks
Standard benchmarks can be a good place to begin detailed model evaluation. They are created by experts, and in many cases, their results are readily available for consumption with minimal effort.
When reviewing benchmark results, pay attention to the specific tasks and metrics most relevant to your use case.
As mentioned earlier when compiling candidate models, the Massive Text Embedding Benchmark (MTEB) is a great starting point that is almost used as an industry standard measure.
Let's dig a little deeper into how to interpret these benchmark results for a detailed evaluation. The MTEB is composed of over a hundred individual tasks, which are combined to characterize a model’s performance by each task type. For text models, common tasks types include:
- Retrieval: Finding relevant documents based on a query
- Classification: Categorizing text into predefined classes
- Clustering: Grouping similar texts together
- Reranking: Sorting results by relevance
- Semantic textual similarity (STS): Measuring how similar two texts are semantically
The most common task type for use in AI applications may be retrieval. In fact, we’ve already discussed using retrieval scores from MTEB. But there is a lot more to dig into than the overall score, as the MTEB makes individual task scores available.
Review MTEB scores in detail
Each task type score in MTEB is composed of multiple scores from multiple tasks. The retrieval score, as of April 2025, is made up of scores from 17 different task benchmarks.
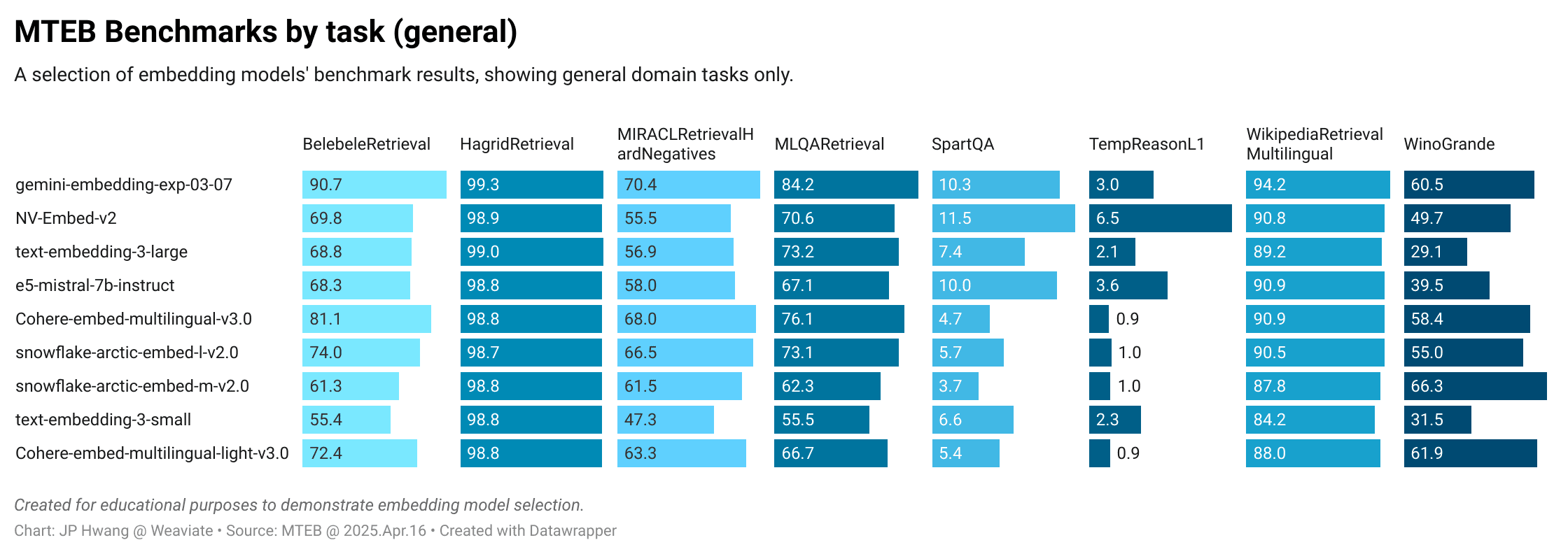
Let’s compare a few models’ performances below through visualizations of scores. These figures compile results from MTEB’s multilingual task set, divided into two subsets for readability.
This first image includes tasks that uses general domain data, such as the news and encyclopedic data.
The next image includes tasks that uses more specialized domain data. These benchmarks span a range of areas, including legal, medical, programming, and government data.
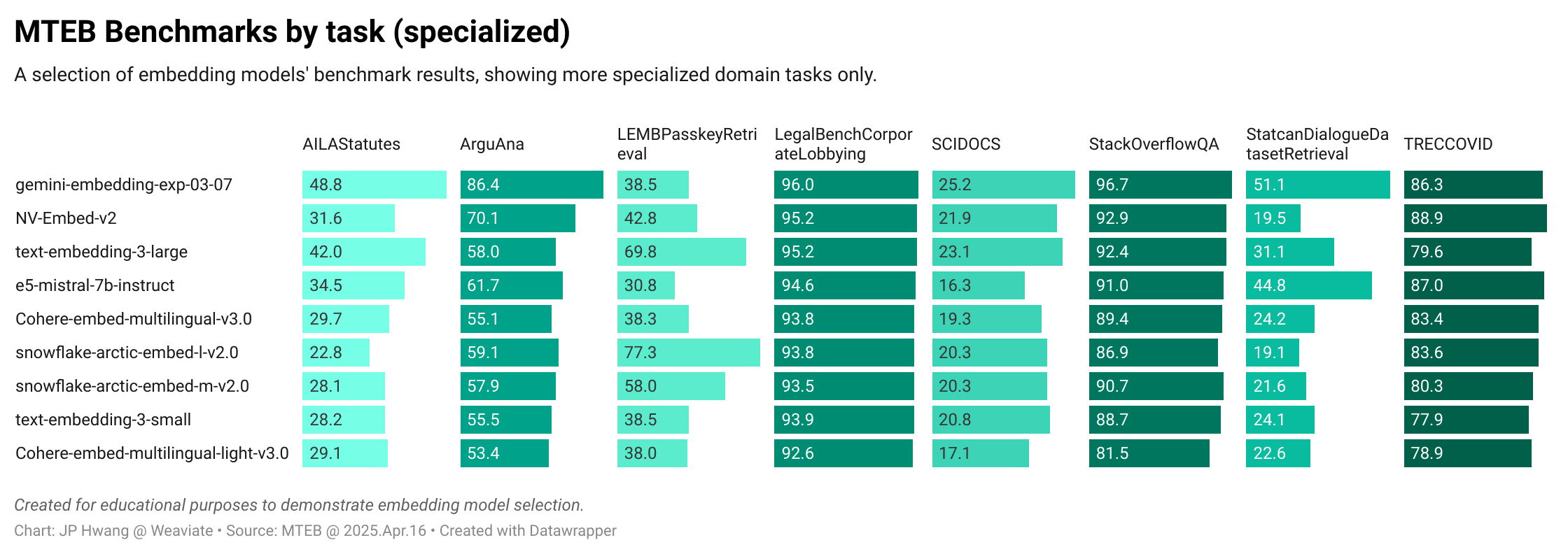
The chart shows that certain embedding models at the top of the table, such as gemini-embedding-exp-03-07 perform quite well across the board compared to the others. But this doesn’t tell the whole story, as a given model often outperforms its average score in particular tasks.
For example, the snowflake-arctic-embed models perform very well with the LEMBPasskeyRetrieval task, which is designed to test recall of specific text buried in a longer embedding. And Cohere’s Cohere-embed-multilingual-v3.0 performs quite well in the MIRACL task, which is a highly multilingual task.
In fact, it is interesting to note that even though we are looking at MTEB’s multilingual task set, it includes includes a number of tasks with an English-only (or majority) corpus.

So, you may benefit from deriving your own metric that blends these task scores, based on how well each specific task corresponds to your needs.
You might consider:
- Task relevance: Does the task match your use case?
- Data distribution: Does the data represent your domain?
- Metric relevance: Are the reported metrics aligned with your requirements?
- Recency: Are the results recent enough to reflect current model capabilities?
- Fairness: Were all models evaluated under comparable conditions?
For example, if you know that your data definitely will include a blend of languages, you may weight the multi-lingual datasets more heavily than the mono-lingual datasets. And similarly with domain-specific data, such as legal, medical, programming and so on.
The resulting score may be different from the official blended number, but may be more relevant to your particular use case.
Limitations of standard benchmarks
These third-party benchmarks are very useful, but there are a few limitations that you should keep in mind. The main two limitations are data leakage, and correlation to your needs.
Data leakage
Because these benchmarks are publicly available, there is a risk that some of the benchmark data ends up in the training data used to build models. This can happen for a number of reasons, especially because there is simply so much data being used in the training process.
This means that the benchmark result may not be a fair representation of the model’s capabilities, as the model is “remembering” the training data.
Correlation to your needs
Another limitation is that the standard benchmarks don’t accurately reflect your needs. As you saw, we can aim to find a benchmark that is as close as possible to your actual use case. But it is unlikely that the task, data distribution and metrics are fully aligned with your needs.
Mitigation
As a result, it is important to take these standard benchmarks with a grain of salt. And in terms of getting further signals, a good complementary exercise is to perform your own benchmarks, which we will look at in the next section.
Model evaluation: custom benchmarks
While standard benchmarks provide valuable reference points, creating your own custom evaluation can be a fantastic complementary tool to address their limitations.
Running your own benchmark can sound quite intimidating, especially given how extensive benchmarks such as MTEB are. But it doesn’t need to be. You can do this by following these steps:
Set benchmark objectives
By now, you should have an idea of any gaps in your knowledge set, as well as your given tasks. It might be something like:
- Which model best retrieves the appropriate related customer reviews about coffee, written primarily in English, French, and Korean?
- Does any model work well across code retrieval in Python and Golang for back-end web code chunks, as well as related documentation snippets?
The custom benchmark should be designed with an idea of addressing particular questions.
Determine metrics to use
Once the overall goals are defined, the corresponding metrics can follow.
For example, retrieval performance is commonly measured by one or more of precision, recall, MAP, MRR, and NDCG.
Each of these measure slightly different aspects of retrieval performance. However, using NDCG is a good starting point.
NDCG measures the system's ability to correctly sort items based on relevance. Given a query and a dataset ranked for this query, NDCG will reward results for having the higher ranked items higher in the search results.
It is measured on a score of 0 to 1, where 0 means no ranked items were retrieved, and 1 means all top ranked items were retrieved, and ordered correctly.
Curate a benchmark dataset
A suitable dataset is critical for a benchmark to be meaningful. While such a dataset may already exist, it is common to build or reshape a dataset to suit the benchmark goals and metrics.
The dataset should aim to:
- Reflect the retrieval task
- Reflect the task difficulty
- Capture the data distribution
- Include sufficient volume
This may be the most time consuming part of the process. However, a pragmatic approach can help to make it manageable. A benchmark with as few as 20 objects and a handful of queries can produce meaningful results.
Run benchmark
At this point, run the benchmark using your candidate models.
As with many other scientific projects, reproducibility and consistency is key here. It is also worth keeping in mind that you may come back to this later on to assess new models, or with updated knowledge about your needs.
In programming terms, you might modularize aspects, such as embedding creation, dataset loading, metric evaluation, and result presentation.
Evaluate the results
Once the benchmarks are run, it is important to assess the results using quantitative (e.g. NDCG@k numbers) and qualitative (e.g. which objects were retrieved where) means.
The quantitative results will produce a definitive ranking that you can use, for example to order the models. However, this is subject to many factors, such as dataset composition and metric being used.
The qualitative results may provide more important insights, such as patterns of failure. For example, may see an embedding model:
- Regularly fail to retrieve certain types of objects, such as shorter, but very relevant text, favoring longer ones
- Perform better with positively phrased text but not ones with negation in the sentence.
- Struggle with your domain-specific jargon.
- Work well with English and Mandarin Chinese, but not so well with Hungarian, which may be a key language for your data.
To some extent, these insights may be only discoverable to those with domain familiarity, or those with context on the system being built. Accordingly, qualitative assessment is critically important.
Questions and feedback
If you have any questions or feedback, let us know in the user forum.