
Identify needs & compile candidates
Identify needs
A systematic approach to model selection starts with clearly identifying requirements. Organizing these requirements into categories can help ensure you consider all relevant factors when evaluating embedding models.
Here are some of our key considerations:
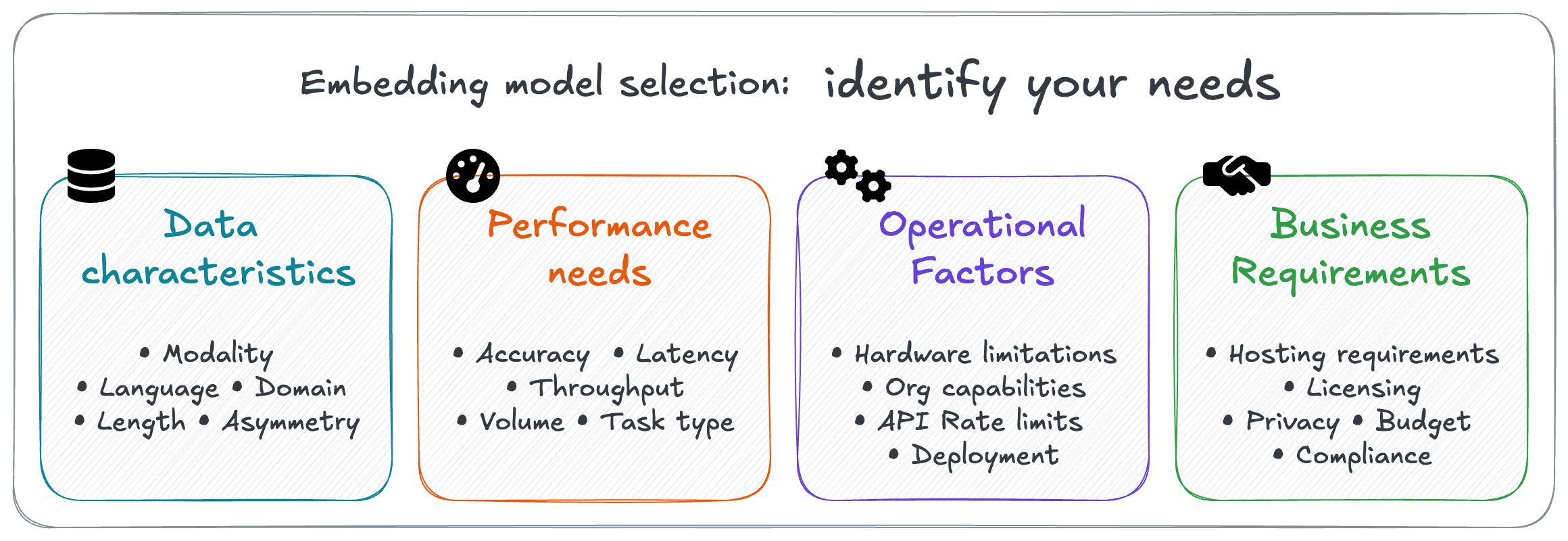
Data Characteristics
| Factor | Key Questions | Why It Matters |
|---|---|---|
| Modality | Are you dealing with text, images, audio, or multimodal data? | Models are built for specific modality/modalities. |
| Language | Which languages must be supported? | Models are trained & optimized for specific language(s), leading to trade-offs in performance. |
| Domain | Is your data general or domain-specific (legal, medical, technical)? | Domain-specific models (e.g. medical) understand specialized vocabulary and concepts. |
| Length | What's the typical length of your documents and queries? | Input token context windows vary between models, from as small as 256 tokens to 8192 tokens for example. However, longer context windows typically require exponentially higher compute and latency. |
| Asymmetry | Will your queries differ significantly from your documents? | Some models are built for asymmetric query to document comparisons. So queries like laptop won't turn on can easily identify documents like Troubleshooting Power Issues: If your device fails to boot.... |
Performance Needs
| Factor | Key Questions | Why It Matters |
|---|---|---|
| Accuracy (recall) | How critical is it that all the top results are retrieved? | Higher accuracy requirements may justify more expensive or resource-intensive models. |
| Latency | How quickly must queries be processed? | Larger models with better performance often have slower inference times. For inference services, faster services will cost more. |
| Throughput | What query volume do you anticipate? Will there be traffic spikes? | Larger models with better performance often have lower processing capacity. For inference services, increased throughput will increase costs. |
| Volume | How many documents will you process? | Larger embedding dimensions increase memory requirements for your vector store. This will impact resource requirements and affect costs at scale. |
| Task type | Is retrieval the only use case? Or will it also involve others (e.g. clustering or classification) ? | Models have strengths and weaknesses; a model excellent at retrieval might not excel at clustering. This will drive your evaluation & selection criteria. |
Operational Factors
| Factor | Key Questions | Why It Matters |
|---|---|---|
| Hardware limitations | What computational resources are available for hosting & inference? | Hardware availability (costs, GPU/TPU availability) will significantly affect your range of choices. |
| API rate limits | If using a hosted model, what are the provider's limits? | Rate limits can bottleneck applications, or limit potential growth. |
| Deployment & maintenance | What technical expertise and resources are required? | Is self-hosting a model an option, or should you look at API-based hosted options? |
Business Requirements
| Factor | Key Questions | Why It Matters |
|---|---|---|
| Hosting options | Do you need self-hosting capabilities, or is a cloud API acceptable? | Self-hosting ➡️ more control at higher operational complexity; APIs ➡️ lower friction at higher dependencies. |
| Licensing | What are the licensing restrictions for commercial applications? | Some model licenses or restrictions may prohibit certain use cases. |
| Long-term support | What guarantees exist for the model's continued availability? | If a model or business is abandoned, downstream applications may need significant reworking. |
| Budget | What are your cost limits and expenditure preferences? | Embedding costs can add up over time, but self-hosting can incur high upfront costs. |
| Privacy & Compliance | Are there data privacy requirements or industry regulations to consider? | Some industries require specific models. And privacy requirements may impose hosting requirements. |
Documenting these requirements creates a clear profile of your ideal embedding model, which will guide your selection process and help you make informed trade-offs.
Compile candidate models
After identifying your needs, create a list of potential embedding models to evaluate. This process helps focus your detailed evaluation on the most promising candidates.
There are hundreds of embedding models available today, with new ones being released regularly. For this many models, even a simple screening process would be too time-consuming.
As a result, we suggest identifying an initial list of models with a simple set of heuristics, such as these:
Account for model modality
This is a critical, first-step filter. A model can only support the modality/modalities that it is designed and trained for.
Some models (e.g. Cohere embed-english-v3.0) are multimodal, while others (e.g. Snowflake’s snowflake-arctic-embed-l-v2.0) are unimodal.
No matter how good a model is, a text-only model such as snowflake-arctic-embed-l-v2.0 will not be able to perform image retrieval. Similarly, a ColQwen model cannot be used for plain text retrieval.
Favor models already available
If your organization already uses embedding models for other applications, these are great starting points. They are likely to have been screened, evaluated and approved for use, and accounts/billing already configured. For local models, this would mean that the infrastructure is already available.
This also extends to models available through your other service providers.
You may be already using generative AI models through providers such as Cohere, Mistral or OpenAI. Or, perhaps your hyperscaler partners such as AWS, Microsoft Azure or Google Cloud provide embedding models.
In many cases, these providers will also provide access to embedding models, which would be easier to adopt than those from a new organization.
Try well-known models
Generally, well-known or popular models are popular for a reason.
Industry leaders in AI such as Alibaba, Cohere, Google, NVIDIA and OpenAI all produce embedding models for different modalities, languages and sizes. Here are a few samples of their available model families:
| Provider | Model families |
|---|---|
| Alibaba | gte, Qwen |
| Cohere | embed-english, embed-multilingual |
gemini-embedding, text-embedding | |
| NVIDIA | NV-embed |
| OpenAI | text-embedding, ada |
There are also other families of models that you can consider.
For example, the ColPali family of models for image embeddings and CLIP / SigLIP family of models for multimodal (image and text) are well-known in their respective domains. Then, nomic, snowflake-arctic, MiniLM and bge models are some examples of well-known language retrieval models.
These popular models tend to be well-documented, discussed and widely supported.
As a result, they tend to be easier than the more obscure models to use, evaluate, troubleshoot and use.
Benchmark leaders
Models that perform well on standard benchmarks may be worth considering. Resources like MTEB Leaderboard can help identify high-performing models.
As an example, the screenshot below shows models on MTEB at a size of fewer than 1 billion parameters, sorted by their retrieval performance.
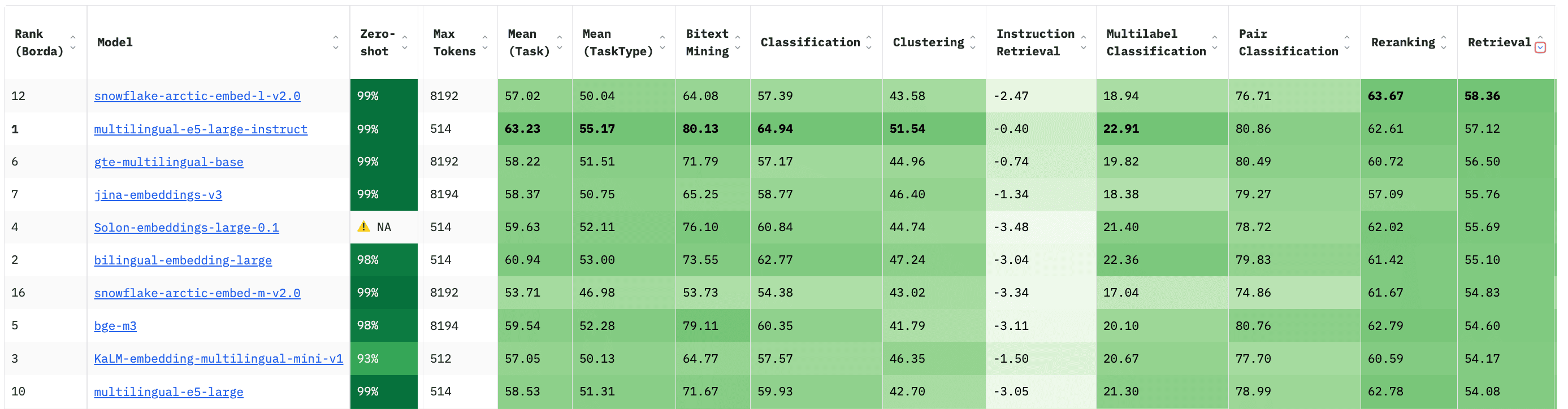
It shows some models that we’ve already discussed - such as the showflake-arctic, Alibaba’s gte, or BAAI’s bge models.
But additionally, you can see already a number of high-performing models that we hadn’t discussed. Microsoft research's intfloat/multilingual-e5-large-instruct or JinaAI’s jinaai/jina-embeddings-v3 model are both easily discoverable here.
Note that as of 2025, the MTEB contains different benchmarks to assess different capabilities, such as the linguistic or modality needs.
When viewing benchmarks, make sure to view the right set of benchmarks, and the appropriate columns. In the example below, note that the page shows results for MIEB (image retrieval), with results sorted by Any to Any Retrieval.
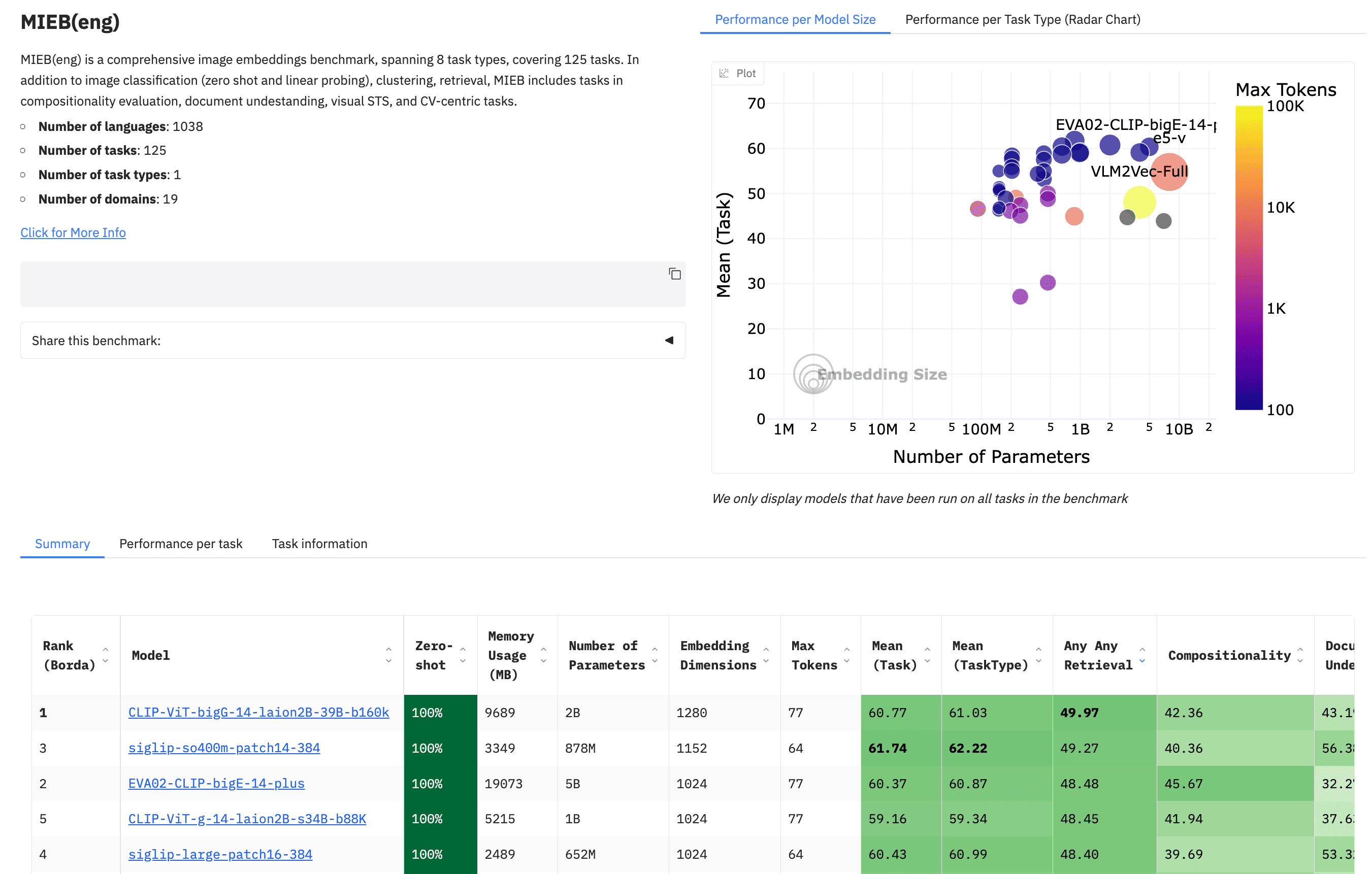
The MTEB is filterable and sortable by various metrics. So, you can arrange it to suit your preferences and add models to your list as you see fit.
You should be able to compile a manageable list of models relatively quickly using these techniques. This list can then be manually reviewed for detailed screening.
Questions and feedback
If you have any questions or feedback, let us know in the user forum.