
Workflow for model selection
Overview
Selecting the right embedding model is a complex task. A big reason for this complexity is that each model will have some strengths and weaknesses that involve trade-offs.
An obvious trade-off is that between model performance, size and cost. Take a look at the chart below, showing a general correlation between model size and retrieval performance for embedding models.
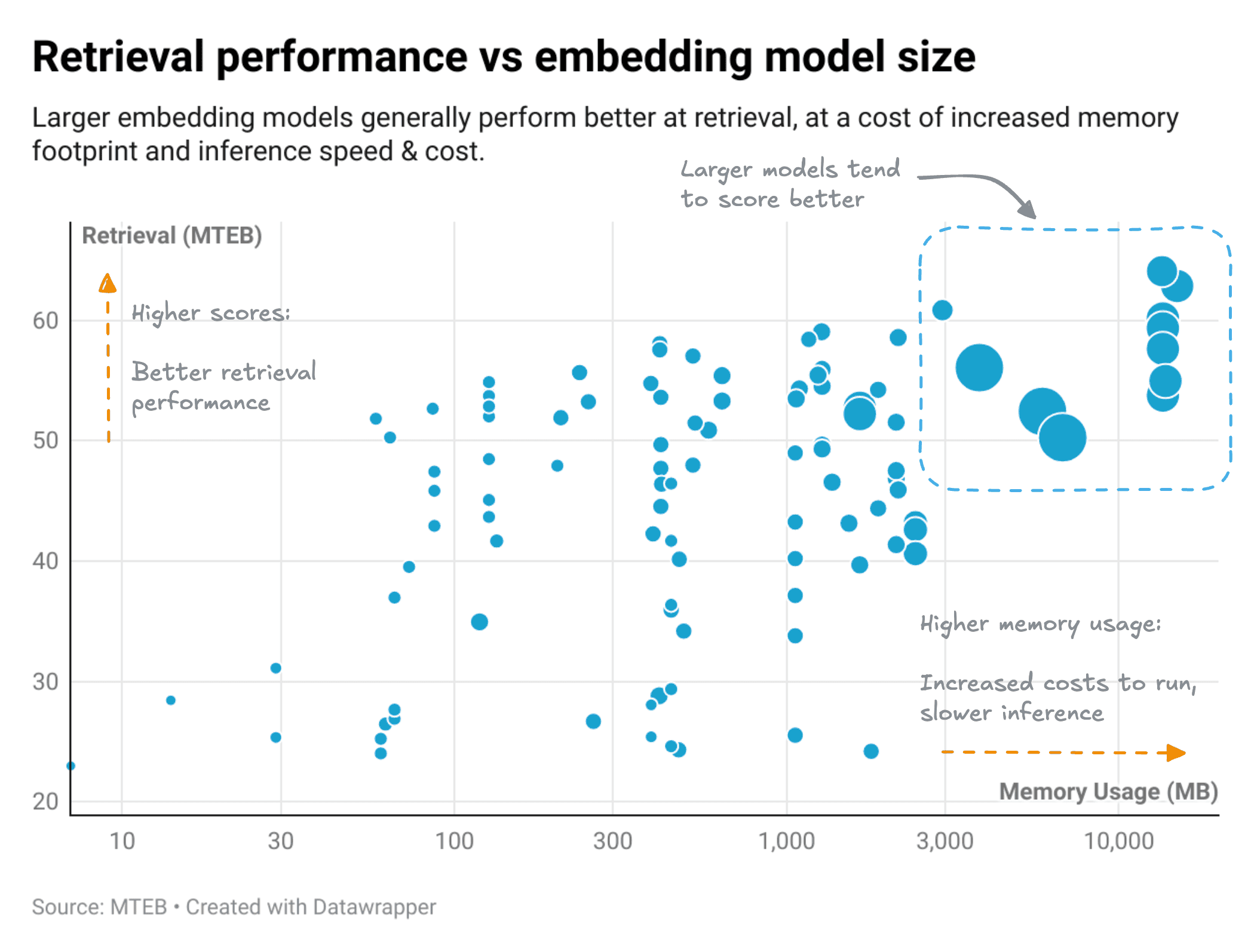
The chart shows a clear positive relationship between model size and higher performance. This also means that generally, models with better performance will be larger. They will require more memory and compute, which means higher costs and slower speeds.
In other words, a larger model such as nv-embed-v2 may perform better at retrieval than a smaller model such as snowflake-arctic-embed-m-v1.5, but may cost more to run and/or use.
But there are many other dimensions to consider. For example:
- A proprietary model such as a modern
geminimodel may show promising performance, but may not meet a user’s preference for local inference. - While a model may perform well at a standard benchmark, it may not perform as well if given material from a specialized domain, such as legal, medical, or coding tasks.
- A local model may be cheaper to run, but the organization may lack the expertise and resources for long-term infrastructure maintenance.
In the face of this complexity, a systematic approach can help you to make an informed decision based on your specific requirements. This is one such approach:
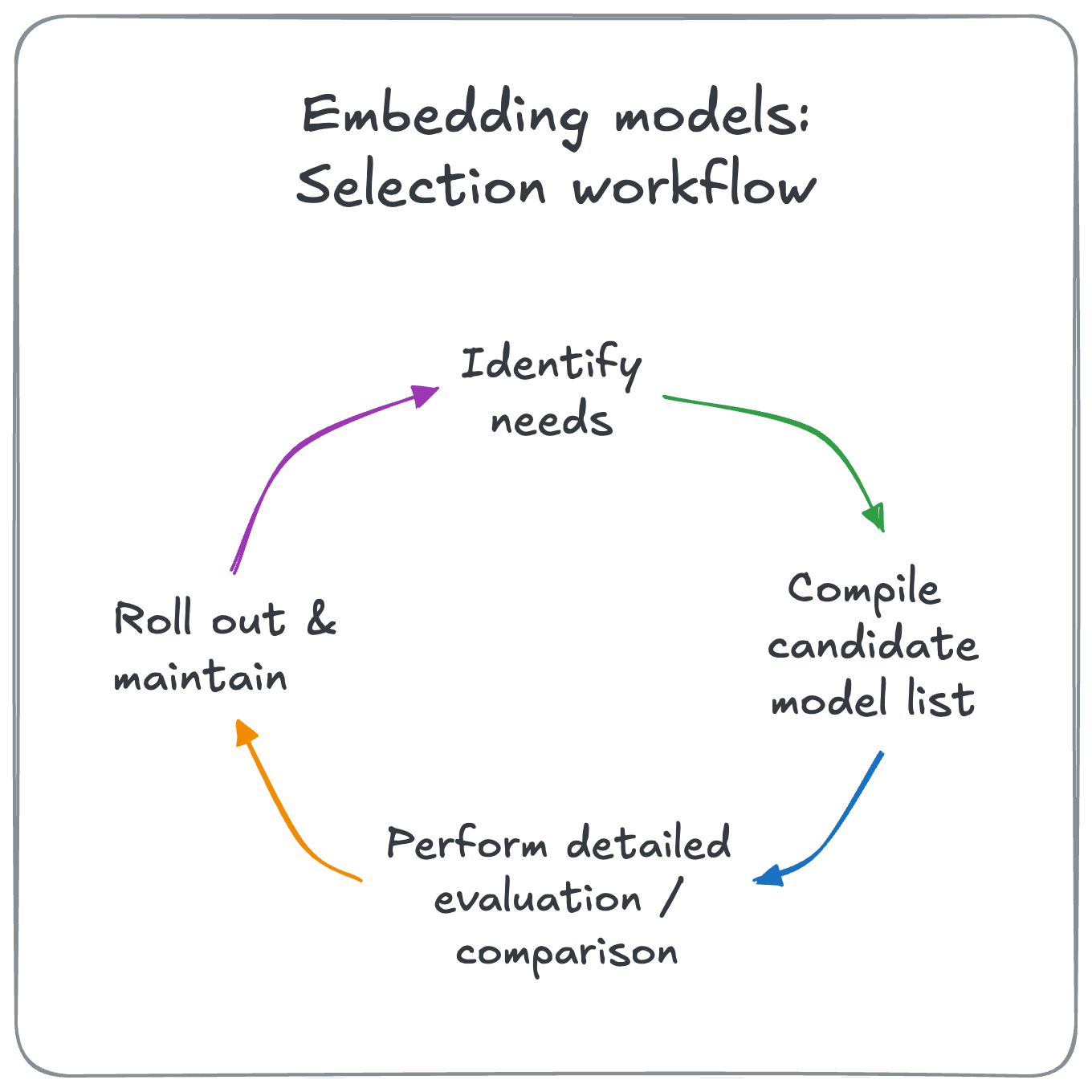
This workflow is made up of four key stages as illustrated in the diagram above:
- Identify your needs: Clearly articulate a set of requirements or preferences to act as a set of guidelines for the future.
- Compile a list of candidate models: Screen for a set of potentially suitable models based on your identified needs and available information.
- Perform detailed evaluation: Run your own evaluations, for your use case, using your chosen data.
- Periodic re-evaluation: Keep an eye for any changes to your requirements (data, application) or environment (new model, provider)
Next, we will review each stage one by one.
Questions and feedback
If you have any questions or feedback, let us know in the user forum.