
Perform initial screening
Overview
Once you have a list of candidate models down to a reasonable size (say, 10-20 models maximum), you can start to manually review this list.
This step can be a screen process comparing your compiled requirements against available model details. In most cases, publicly available models will also include summary information through model cards or other means such as documentation or even related academic papers.
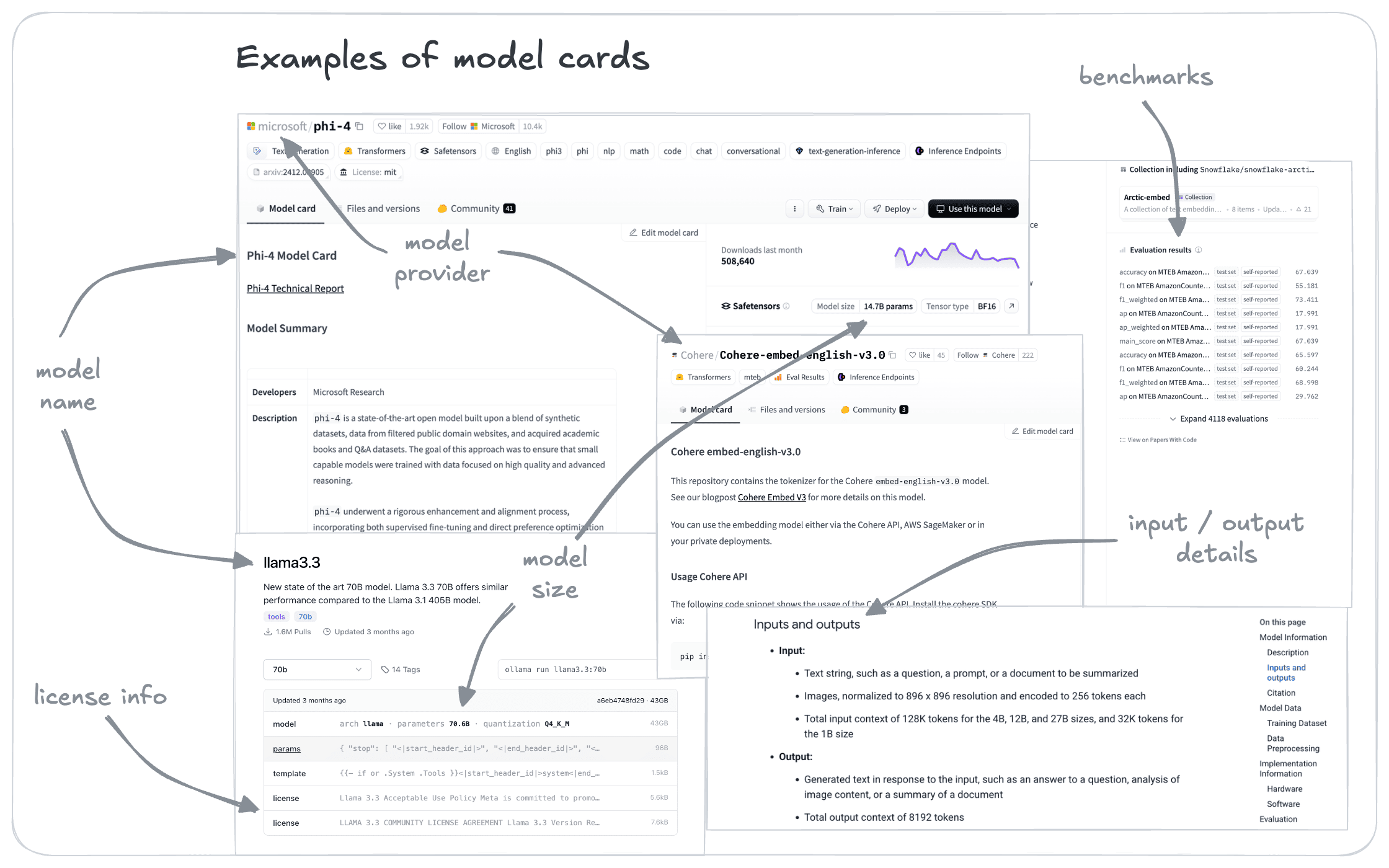
Some of the readily screenable factors, and how to screen models are shown below:
Screening factors
Context length
Input context length is a critical factor to ensure that meaning from the whole document chunks taken into account. Maximum input context lengths vary widely between models, as shown in these examples:
all-MiniLM-L6-v2: 256 tokens- Cohere
embed-english-v3.0: 512 tokens snowflake-arctic-embed-l-v2.0: 8192 tokens
Input text exceeding the context length will be ignored. On the other hand, higher allowable context lengths typically require exponentially higher compute and latency. As a result, this is an important tradeoff that includes an interplay with your text chunking strategy.
Consider what a “chunk” of information to retrieve looks like for your use case. Typically, a model with 512 tokens or higher is sufficient for most use cases.
Model goals & training methodology
Different embedding models are optimized for different use cases. This informs the model architecture, training data and training methodology.
Reviewing the model provider’s descriptions and published training details can provide key insights into its suitability for your use case.
- Linguistic capabilities: Some models (e.g. Snowflake’s
snowflake-arctic-embed-l-v2.0) are multi-lingual, while others are primarily uni-lingual (e.g. Cohere’sembed-english-v3.0). These linguistic capabilities come largely from the training data and methodology selection. - Domain exposure: Models trained on specialized domains (e.g., legal, medical, financial) typically perform better for domain-specific applications.
- Primary tasks: The provider may have been building a general-purpose embedding model, or one that is particularly focussed on particular tasks. Google’s
gemini-embeddingmodel appears to be designed with a goal of being a jack-of-all-trades type, state of the art model in all tasks and domains (release blog). On the other hand, Snowflake’sarctic-embed2.0 models appear to be focussed on retrieval tasks (release blog). - Base model: In many cases, an embedding model is trained from an existing model. Any advantages, or shortcomings, of the base model will often carry over to the final model, especially if it is an architectural one such as its context window size or pooling strategy.
- Training methods (advanced): If you have more experience with model training techniques, this is an area that you can use as heuristics as well. For example, models trained with contrastive learning often perform better for retrieval tasks. Additionally, hard negative mining is a technique that is valuable to enhance contrastive learning.
Select a model whose capabilities align with your goals. For example, if your application requires retrieving paragraphs of text chunks in English, French, German, Mandarin Chinese and Japanese, check the model card and training information. Look for its retrieval performance, and whether these languages were included in the training corpus.
Dimensionality and optimization options
The dimensionality of embeddings affects both performance and resource requirements.
As a rule of thumb, your memory requirements for a vector database (any quantization notwithstanding) may be: 4 bytes n dimensions m objects * 1.5 where m is the size of your database, and n is the vector dimensionality (1.5 to account for overhead).
This means that for, say, 10 million objects, the memory requirements for given models’ full outputs will be:
- NVIDIA
NV-embed-v2:246 GB - OpenAI
text-embedding-3-large:184 GB snowflake-arctic-embed-l-v2.0:61 GBall-MiniLM-L6-v2:23 GB
As you might imagine, this can add significant costs to your infrastructure needs for the vector database.
At the database end, there are quantization strategies which will reduce the footprint and therefore costs, which we will cover in another course.
However, certain models can also help in this regard as well. Matryoshka Representation Learning (MRL) models like jina-embeddings-v2 or snowflake-arctic-embed-l-v2.0 allow for flexible dimensionality reduction by simply truncating the vector. In the case of snowflake-arctic-embed-l-v2.0, it can be truncated to 256 dimensions from its original 1024 dimensions, reducing its size to a quarter without much loss in performance.
Consider how big your dataset is likely to get to, then select your model accordingly, keeping the resulting system requirements in mind. If the requirements are too high and thus out-of-budget, it may set you back to square one when you need to scale up and go to production.
Model size and inference speed
Model size directly impacts inference speed, which is critical for applications with latency requirements. Larger models generally offer better performance but at the cost of increased computational demands.
When screening models, consider these aspects:
| Factor | Implications |
|---|---|
| Parameter count | More parameters typically mean better quality but slower inference and higher memory usage |
| Architecture efficiency | Some models are optimized for faster inference despite their size |
| Hardware requirements | Larger models may require specialized hardware (GPUs/TPUs) |
Given that the inference speed is a function of the model, inference hardware as well as the network latencies, review these factors as a system when screening models’ suitability.
Pricing, availability, and licensing
The practical aspects of model adoption extend beyond technical considerations.
Providers offer various pricing structures:
- API-based pricing: Pay-per-token (OpenAI, Cohere)
- Compute-based pricing: Based on hardware utilization (Cloud providers)
- Tiered licensing: Different capabilities at different price points
- Open-source: Free to use, but self-hosting costs apply
Choice of model and inference type will affect model availability:
- Geographic availability: Some providers don't operate in all regions
- SLA guarantees: Uptime commitments and support levels
- Rate limiting: Constraints on throughput that may affect your application
- Version stability: How frequently models are deprecated or updated
Additionally, licensing terms vary significantly:
- Commercial use restrictions: Some open models prohibit commercial applications
- Data usage policies: How your data may be used by the provider
- Export restrictions: Compliance with regional regulations
- Deployment flexibility: Whether the model can be deployed on-premises or edge devices
Always review the specific terms for each model. For example, while models like CLIP are openly available, they may have usage restrictions that affect your application.
These practical considerations can sometimes outweigh performance benefits. A slightly less accurate model with favorable licensing terms and lower costs might be preferable for many production applications.
Creating your candidate shortlist
After considering these factors, you can create a prioritized shortlist of models to evaluate in more detail. A good approach is to include a mix of:
- Benchmark leaders: High-performing models on standard metrics
- Resource-efficient options: Models with smaller footprints or faster inference
- Specialized models: Models that might be particularly well-suited to your domain
- Different architectures: Including diverse approaches increases the chance of finding a good fit
Aim for 3-5 models in your initial shortlist for detailed evaluation. Including too many models can make the evaluation process unwieldy and time-consuming.
In the next section, we'll explore how to perform detailed evaluations of these candidate models to determine which one best meets your specific requirements.
Questions and feedback
If you have any questions or feedback, let us know in the user forum.