
Weaviate 1.31 Release
Weaviate v1.31 is now available with some really exciting new features as always. It introduces MUVERA encoding for multi-vector embeddings, new BM25 operators for more customizable keyword searching, the ability to add new vectors to existing collections, just to name a few.
This release also adds support for a bunch of new models (model2vec, VoyageAI's v3.5 models, Cohere v3.5 reranker & V4 embed models), and a HUGE list of performance improvements. (Honestly, take a look at the full release notes for the list of changes, and give our engineering team a high five for all the hard work they put in!)
Here are the release ⭐️highlights⭐️!

- MUVERA for multi-vector embeddings
- New BM25 keyword search operators
- Add new vectors to existing collections
- HNSW snapshotting
- More model integrations
- A HUGE list of performance improvements
- Community contributions
MUVERA for multi-vector embeddings
ColBERT or ColPali-like multi-vector embeddings went generally available in Weaviate v1.30. As a reminder, here is an illustration showing the difference between single-vector and multi-vector embeddings.
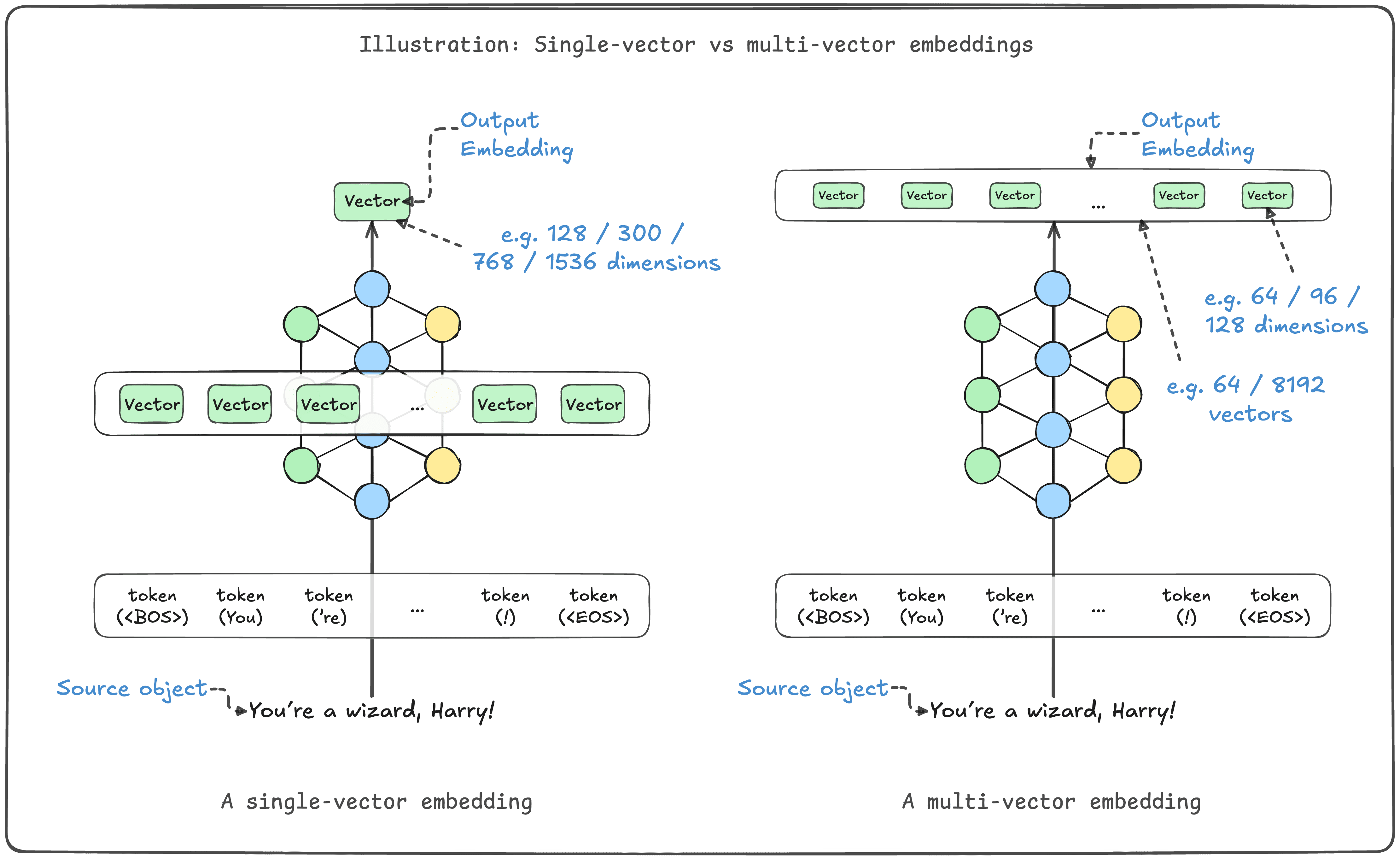
Multi-vector embeddings enable more precise searching through "late interaction", but they have a drawback meaning that they can be much larger than single-vector embeddings.
This is where MUVERA comes in. It flattens variable-length multi-vector embeddings into fixed-length single-vector embeddings. In a majority of cases, this will reduce the size of the embeddings - more so for larger embeddings such as those from long text sources (many tokens) or images (many patches).
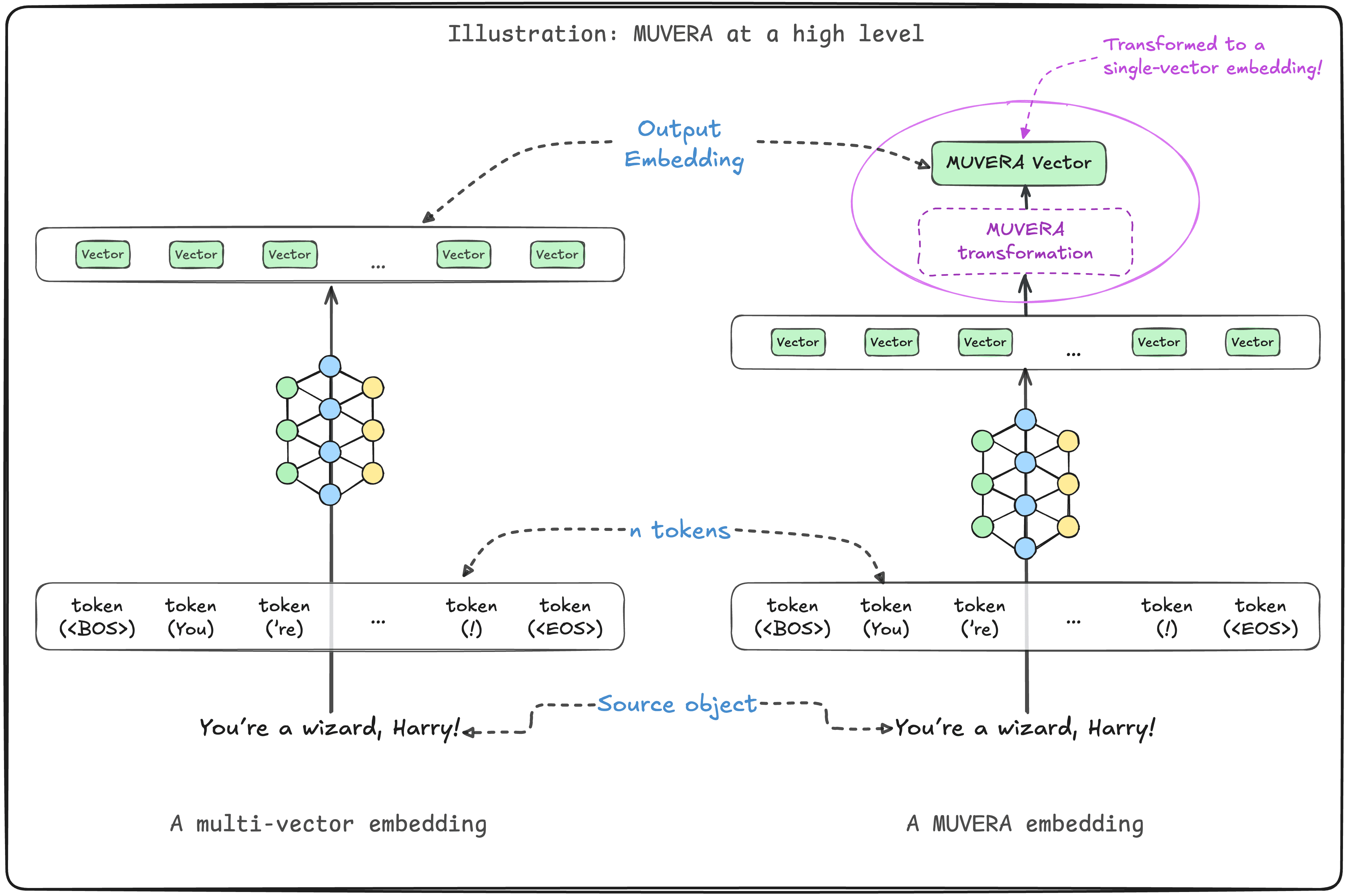
There are additional benefits to using MUVERA, such as the general speed-up at import time given that only one vector needs to be inserted into the database (and the vector index). The trade-off is that the simplified vector may reduce the quality of the search.
You can mitigate some of this by changing your vector index settings, such as to set higher ef values.
We'll get into more details on this in a future blog post, coming within the next week or so.
New BM25 keyword search operators
Keyword search is a key (sorry, couldn't resist) part of Weaviate's search capabilities. A keyword search will match documents that contain the exact terms (i.e. tokens) in the query, ranked by a BM25 algorithm score that captures the relevance of the match.
The default BM25 algorithm includes documents that contains at least one of the terms in the query. This is a good default for most use cases, but it may not be the best for all use cases.
For example, if you are searching for a specific product (e.g. "noise cancelling microphone"), you may want to only include documents that contain all the terms in the query. Or, if you are searching for technical literature (e.g. "vector embedding quantization technique"), you may want to include documents that contain at least some (e.g. 3) of the terms contained in the query.
Previously, you could sort of do this by combining a BM25 query with a filter. But now, you can use the new And or Or operators to create more complex queries.
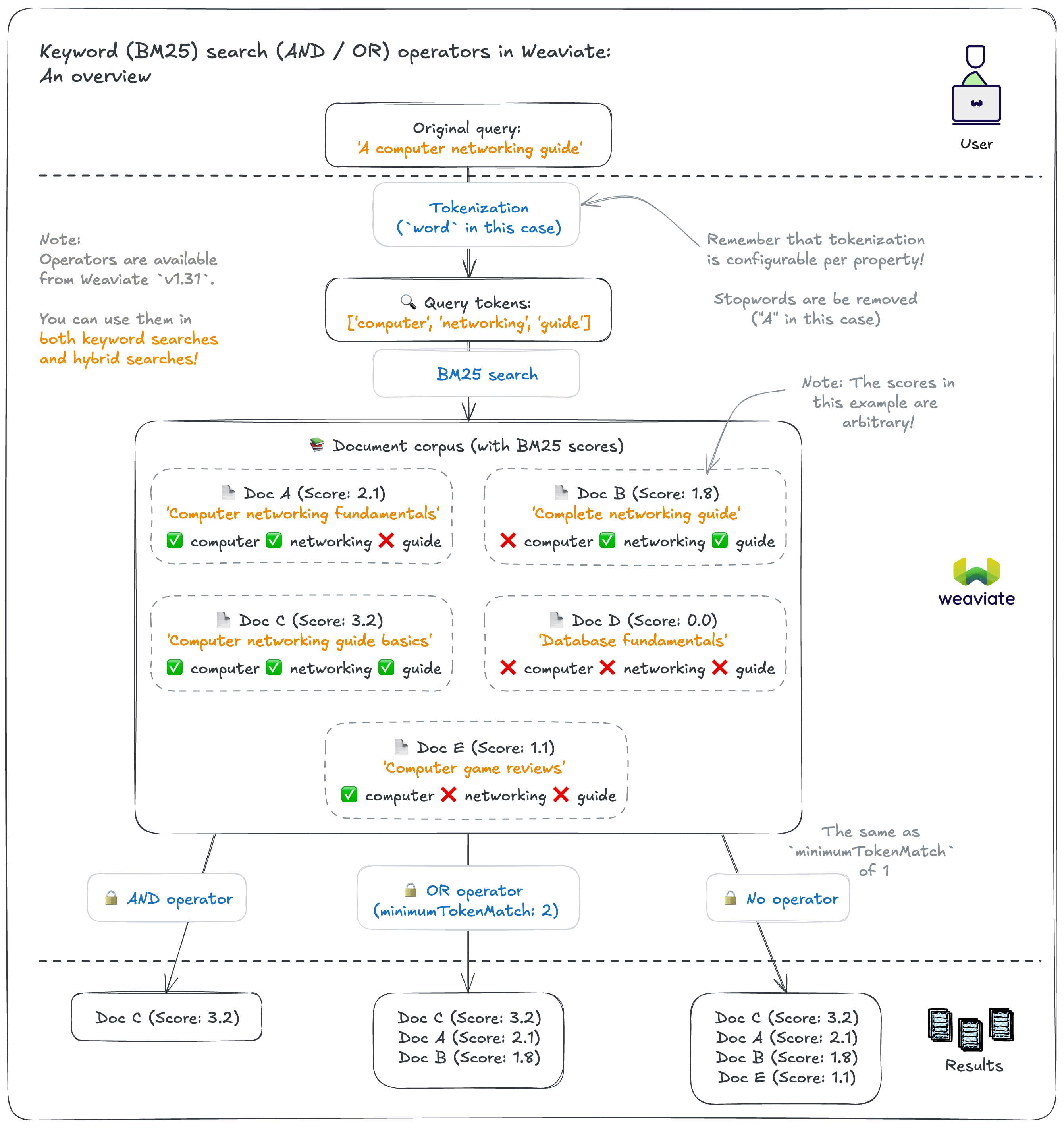
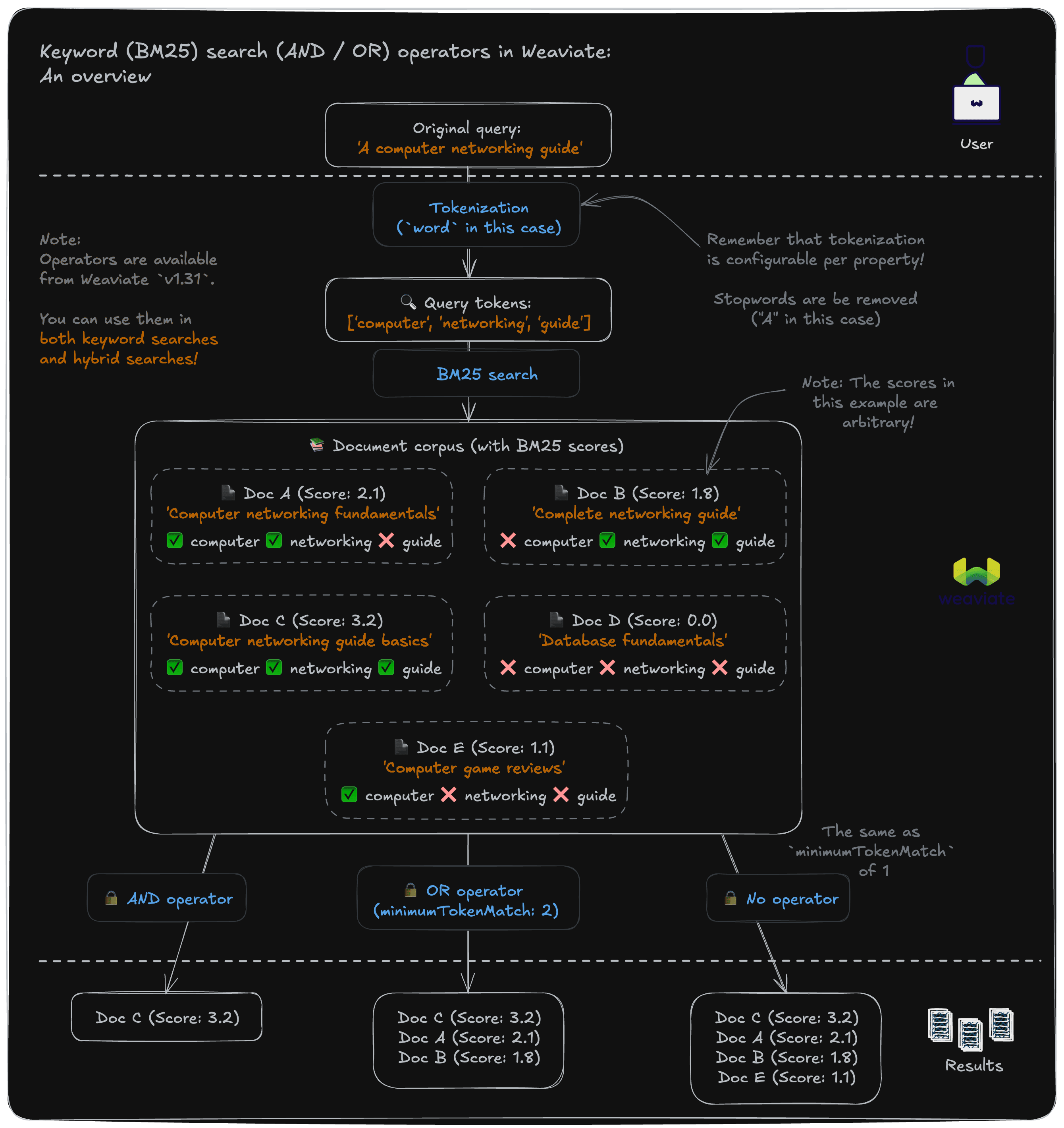
Examples
For example, the following query will ONLY match documents that contain all the terms ("australian", "mammal", "cute") in the query, ranked by BM25 score:
from weaviate.classes.query import BM25Operator
jeopardy = client.collections.get("JeopardyQuestion")
response = jeopardy.query.bm25(
query="Australian mammal cute",
operator=BM25Operator.and_(),
limit=3,
)
for o in response.objects:
print(o.properties)
While this one will match documents that contain at least two of the terms ("australian", "mammal", "cute") in the query, ranked by BM25 score:
from weaviate.classes.query import BM25Operator
jeopardy = client.collections.get("JeopardyQuestion")
response = jeopardy.query.bm25(
query="Australian mammal cute",
operator=BM25Operator.or_(minimum_match=2),
limit=3,
)
for o in response.objects:
print(o.properties)
This is a really powerful feature that allows you to customize your keyword search to your use case. Along with our recent indexing performance improvements (see BlockMax WAND blog), Weaviate's keyword search capabilities keep getting better and better.
In case you are wondering - yes, this is available with Weaviate's hybrid search as well. 😉 So you can granularly control the keyword search part of your hybrid search even more.
Add new vectors to existing collections
Vectors are, obviously, the core of Weaviate's search capabilities. They are the "fingerprint" of the data that you are storing in Weaviate.
Each object can have multiple vector representations in Weaviate. So a single object, say Movie, can have a vector for its title and one for its description.
While you can plan for these vectors at collection creation time, sometimes your needs change. And that's where this new feature comes in.
From v1.31, you can add new vectors to an existing collection. This is particularly useful if you find that you want to do things like:
- Use a different embedding model for a collection (e.g. multi-vector embeddings with MUVERA 😉)
- Generate vectors from different parts of the data
- Add a new modality to an existing collection (e.g. add a vector for the poster image)
HNSW snapshotting
HNSW is Weaviate's default vector index type, as it is efficient and scalable as the size of your collection grows.
You already know that Weaviate includes a ton of great optimizations for HNSW, such as quantizations for in-memory index size, and async indexing for import efficiency.
Now, v1.31 introduces HNSW snapshotting. The tl;dr is that Weaviate can now create snapshots of your HNSW index, instead of having to re-build the index from its write-ahead log (WAL).
Just how much of a difference can this make? Well, it depends on the size of your index of course - but: we've seen around a 10-15x speedup in start-up time for large HNSW indexes.
For a 10 million object index, we've seen it go from 70+ seconds to 5 seconds!
This is enabled by default, so you don't need to do anything to get the benefits. If you want to customize the snapshotting behavior, you can do so as well.
Try it out and watch your instance go 🚀🏎️ .
More model integrations
Our list of model integrations keep growing. In v1.31, we add support for:
Cohere- Added support for Cohere's v3.5 reranker model and v4 Embed model. The v4 Embed model is multimodal, too, meaning they can be used for both text and image embeddings.VoyageAI- Added new set of models from VoyageAI, includingvoyage-3.5,voyage-3.5-liteandvoyage-3-largemodels.model2vec- A state of the art static embedding model, meaning it does not use attention mechanisms, making it much faster to run. Use this model where you may have used something like ourtext2vec-contextionarymodel.
A HUGE list of performance improvements
In these blogs, we tend to talk about the visible new features and improvements - for good reason. But there is a lot of work that you don't necessarily see, all of which adds up to huge improvements in performance over time.
Just as an example, here is a selection of some of the performance improvements that were made in v1.31.

Ultimately, these all add up to a much faster and more efficient Weaviate instance over time.
Which - by the way - is why we always recommend you run the latest version of Weaviate, if possible 😉.
So here's a shout-out to our amazing engineering team for all the hard work they put in to make this release (and every other release) possible. 🚀🚀🚀
Community contributions
Weaviate is an open-source project. And while of course, much of the work is done by our amazing engineering team, we are always excited to see contributions from the community.
For this release, we are super excited to shout-out the following contributors for their contributions to Weaviate. 🎉🎉🎉
- @alingse contributed #7682
- @crewone contributed #7641
- @cryo-zd contributed #7615
- @mohamedawnallah contributed #7779
If you are interested in contributing to Weaviate, please check out our contribution guide, and the list of open issues on GitHub. Filtering for the good-first-issue label is a great way to get started.
Summary
Ready to Get Started?
Enjoy the new features and improvements in Weaviate 1.31. The release is available open-source as always on GitHub, and will be available for new Sandboxes on Weaviate Cloud very shortly.
For those of you upgrading a self-hosted version, please check the migration guide for detailed instructions.
It will be available for Serverless clusters on Weaviate Cloud soon as well.
Thanks for reading, see you next time 👋!
Ready to start building?
Check out the Quickstart tutorial, or build amazing apps with a free trial of Weaviate Cloud (WCD).
Don't want to miss another blog post?
Sign up for our bi-weekly newsletter to stay updated!
By submitting, I agree to the Terms of Service and Privacy Policy.