
Best practices & tips
This page covers what we consider general best practices for using Weaviate. They are based on our experience and the feedback we have received from our users.
We will update this page over time as Weaviate evolves and we learn more about how our users are using it. Please check back regularly for updates.
Upgrades & maintenance
Keep Weaviate and client libraries up-to-date
Weaviate is a fast-evolving product, where we are constantly adding new features, improving performance, and fixing bugs. We recommend keeping Weaviate and the client libraries you use up-to-date to benefit from the latest features and improvements.
To keep up-to-date with the latest releases, you can:
- Subscribe to the Weaviate newsletter
- Watch the relevant Weaviate GitHub repositories. They are:
Generally, a new minor version of Weaviate is released every 6-10 weeks, and new patch versions are regularly released.
Resource management
Use high availability clusters for speed and reliability
For environments with high reliability requirements, high query loads or latency requirements, consider deploying Weaviate in a high availability (HA) configuration. An HA configuration with multiple nodes provide several benefits:
- Better fault tolerance: Continue serving requests even if individual nodes experience issues
- Rolling upgrades: Individual nodes can be upgrades without cluster-level downtime
- Improved query performance: Distribute query load across multiple nodes to reduce latency
- Increased throughput: Handle more concurrent queries and data operations
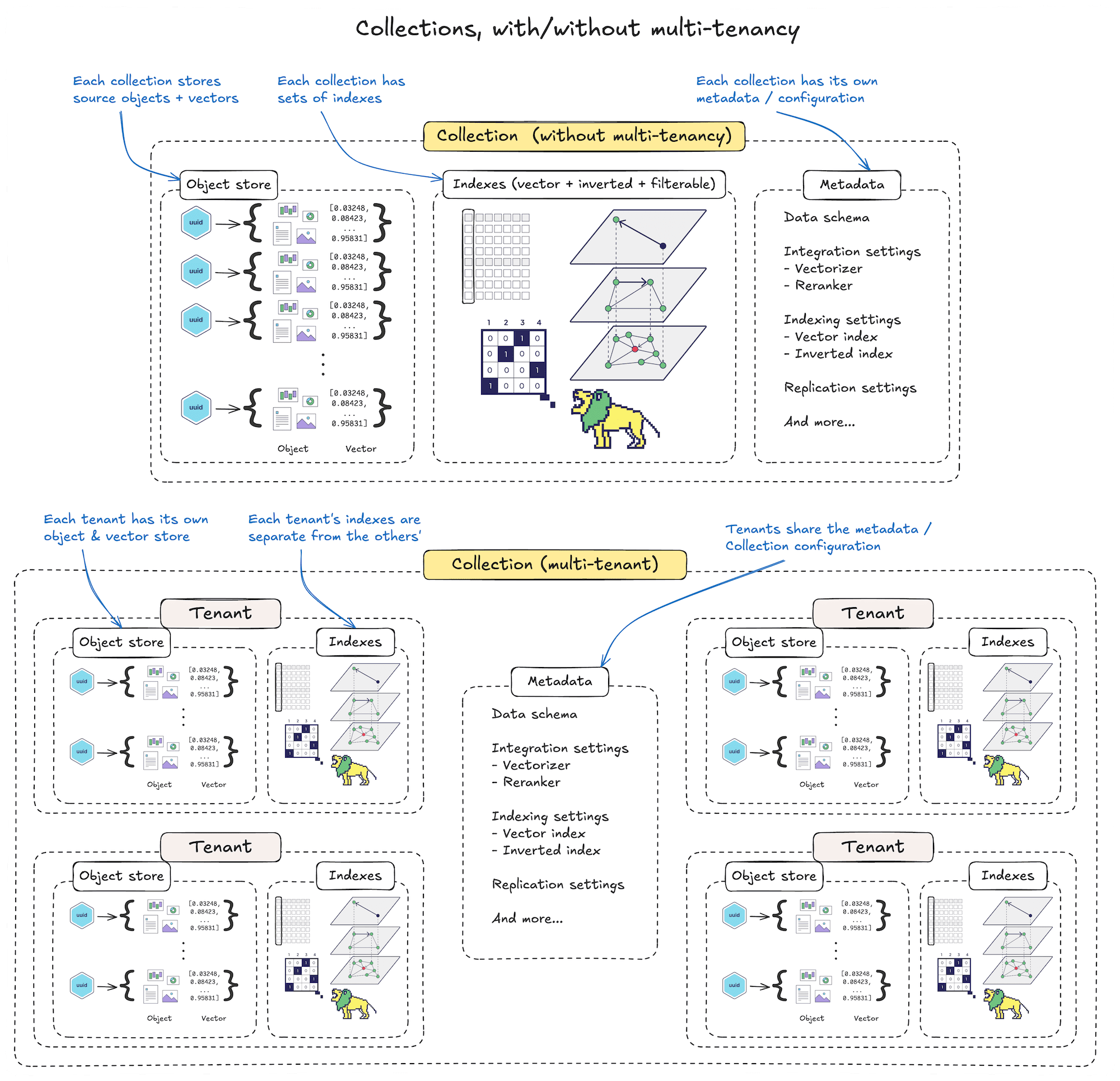
Use multi-tenancy for data subsets
If your use cases involves multiple subsets of data which meet all of the following criteria:
- Have the same data structure (i.e. data schema)
- Can share the same settings (e.g. vector index, inverted index, vectorizer models, etc.)
- Do not need to be queried together
Then consider enabling multi-tenancy, and assigning each subset of data to a separate tenant. This will reduce the resource overhead on Weaviate, and allow you to scale more effectively.
Set a vector index type to suit your data scale
For many cases, the default, hnsw index type is a good starting point. However, in some cases, using flat indexes, or dynamic indexes may be more appropriate.
flatindexes are useful when you know that each collection will only ever contain a small number of vectors (e.g. fewer than 100,000).- They use very little memory, but can be slow for large datasets.
dynamicindexes start with aflatindex, and automatically switch to anhnswindex when the number of vectors in the collection exceeds a certain threshold.- They are a good compromise between memory usage and query performance.
Typically, multi-tenant setups can benefit from using dynamic indexes, as they can automatically switch to hnsw indexes when the number of vectors in a tenant exceeds a certain threshold.
Reduce memory footprint with vector quantization
As the size of your dataset grows, the accompanying vector indexes can lead to high memory requirements and thus significant costs. Especially if the hnsw index type is used.
If you have a large number of vectors, consider using vector quantization to reduce the memory footprint of the vector index. This will reduce the required memory, and allow you to scale more effectively at lower costs.


For HNSW indexes, we suggest enabling product quantization (PQ) as a starting point. It provides a good set of default trade-offs between memory usage and query performance, as well as tunable parameters to optimize for your specific use case.
Customize system thresholds to prevent downtime
Weaviate is configured to emit warnings, or to even go into read-only mode when certain thresholds (in percentage) are exceeded for memory or disk usage.
These thresholds can be adjusted to better fit your use case. For example, if you are running Weaviate on a machine with a large amount of memory, you may want to increase the memory threshold before Weaviate goes into read-only mode. This is because the same percentage of memory usage will represent a larger amount of memory on a machine with more memory.
Set DISK_USE_WARNING_PERCENTAGE and DISK_USE_READONLY_PERCENTAGE to adjust the disk usage thresholds, and MEMORY_WARNING_PERCENTAGE and MEMORY_READONLY_PERCENTAGE to adjust the memory usage thresholds.
Plan memory allocation
When running Weaviate, its memory footprint is a common bottleneck. As a rule of thumb, you can expect to need:
- 6GB of memory for 1 million, 1024-dimensional vectors
- 1.5GB of memory for 1 million, 256-dimensional vectors
- 2GB of memory 1 million, 1024-dimensional vectors with quantization enabled
How did we come up with this figure?
Without quantization, each vector is stored as an n-dimensional float. For 1024-dimensional vectors, this means:
- 4 bytes per float 1024 dimensions 1M vectors = 4GB
We add some overhead for the index structure, and additional overheads, which brings us to the approximate figure of 6GB.
How to quickly check the memory usage
In production settings, you should set up cluster monitoring with tools such as Grafana & Prometheus.
There are, however, other ways to quickly check Weaviate's memory usage.
If you only care about the overall usage, independent of the contents, and have a prometheus monitoring setup already, you can check the metric go_memstats_heap_inuse_bytes which should always show the full memory footprint.
Through pprof
If go is available to your system, you can view the heap profile with golang's pprof tool".
- Have a go runtime installed, or start a Go-based docker container
- Expose port 6060 if running in docker/k8s
To view the profile visually:
go tool pprof -png http://{host}:6060/debug/pprof/heap
Or to view a textual output:
go tool pprof -top http://{host}:6060/debug/pprof/heap
Check the container usage
If you are running Weaviate in kubernetes, you can check an entire container's memory usage with kubectl:
kubectl exec weaviate-0 -- /usr/bin/free
Where weaviate-0 is the pod name.
Note that the apparent memory consumption from the outside (e.g. OS/container levels) will look much higher because the Go runtime is very opportunistic. It often uses MADV_FREE which means that part of the memory can be easily freed as needed. As a result, if Weaviate is the only application running in a container, it will hold on to much more memory than it actually needs, since much of it can be released very quickly when other processes need it.
As a result, this method may be useful for showing the overall high bound for the memory usage. On the other hand, looking at pprof may be more reflective of Weaviate's specific heap profile.
Configure shard loading behavior to balance system & data availability
When Weaviate starts, it loads data from all shards in your deployment. By default, lazy shard loading enables faster startup by loading shards in the background while allowing immediate queries to already-loaded shards.
However, for single-tenant collections under high loads, lazy loading can cause import operations to slow down or partially fail. In these scenarios, consider disabling lazy loading, by setting the following environment variable:
DISABLE_LAZY_LOAD_SHARDS: "true"
This ensures all shards are fully loaded before Weaviate reports itself as ready.
Only disable lazy shard loading for single-tenant collections. For multi-tenant deployments, keeping lazy loading enabled is recommended as it can significantly speed up the startup time.
Data structures
Cross-references vs flattened properties
When designing your data schema, consider whether to use cross-references or flattened properties. If you come from a relational database background, you may be tempted to normalize your data and use cross-references.
However, in Weaviate, cross-references can have multiple drawbacks:
- They are not vectorized, which means that this information is not incorporated as a part of the vector representation of the object.
- They can be slow to query, as they require additional queries to fetch the referenced object. Weaviate is not designed for graph-like queries or joins.
Instead, consider directly embedding the information in each object as another property. This will ensure that the information is vectorized, and can be queried more efficiently.
Data operations
Explicitly define your data schema
Weaviate includes a convenient "auto-schema" functionality that can automatically infer the schema of your data.
However, for production use cases, we recommend explicitly defining your schema, and disabling the auto-schema functionality (set AUTOSCHEMA_ENABLED: 'false'). This will ensure that your data is correctly interpreted by Weaviate, and that malformed data is not ingested into the system, rather than to potentially create unexpected properties.
As an example, consider importing the following two objects:
[
{"title": "The Bourne Identity", "category": "Action"},
{"title": "The Bourne Supremacy", "cattegory": "Action"},
{"title": "The Bourne Ultimatum", "category": 2007},
]
In this case, the second and third objects are malformed. The second has a typo in the property name cattegory, and the third has a category that is a number, rather than a string.
If you have auto-schema enabled, Weaviate will create a property cattegory in the collection, which can lead to unexpected behavior when querying the data. And the third object could lead to the creation of a property category with a data type of INT, which is not what you intended.
Instead, disable auto-schema, and define the schema explicitly:
from weaviate.classes.config import Property, DataType
client.collections.create(
name="WikiArticle",
properties=[
Property(name="title", data_type=DataType.TEXT)
Property(name="category", data_type=DataType.TEXT)
],
)
This will ensure that only objects with the correct schema are ingested into Weaviate, and the user will be notified if they try to ingest an object with a malformed schema.
Accelerate data ingestion with batch imports
When importing any significant amount of data (i.e. more than 10 objects), use batch imports. This will significantly improve your import speed for two reasons:
- You will be sending fewer requests to Weaviate, which reduces the overhead of the network.
- If Weaviate orchestrates data vectorization, it can in turn send vectorization requests in batches, which can be significantly faster, especially where inferences are done with GPUs.
# ⬇️ Don't do this
for obj in objects:
collection.data.insert(properties=obj)
# ✅ Do this
with collection.batch.fixed_size(batch_size=200) as batch:
for obj in objects:
batch.add_object(properties=obj)
Minimize costs by offloading inactive tenants
If you are using multi-tenancy, and have tenants that are not being queried frequently, consider offloading them to cold (cloud) storage.

Offloaded tenants are stored in a cloud storage bucket, and can be reloaded into Weaviate when needed. This can significantly reduce the memory and disk usage of Weaviate, and thus reduce costs.
When the tenant is likely to be used again (e.g. when a user logs in), it can be reloaded into Weaviate, and will be available for querying again.
At the moment, offloading tenants is only available in the open-source version of Weaviate. We plan to make this feature available in Weaviate Cloud.
Application design and integration
Minimize client instantiations
There is a performance overhead when instantiating a Weaviate client object, due to the I/O operations to establish a connection and perform health checks.
Where possible, reuse the same client object for as many operations as you can. Generally, the client object is thread-safe and can be used in parallel across multiple threads.
If multiple client objects are absolutely necessary, consider skipping initial checks (e.g. Python). This can significantly reduce the overhead of instantiating multiple clients.
Note that there may be some client library-specific limitations. For example, the Weaviate Python client should only be used with one batch import thread per client object.
Additionally, you should consider the asynchronous client API to improve performance in asynchronous environments.
Use the relevant Async Client as needed
When using Weaviate in an asynchronous environment, consider using the asynchronous client API. This can significantly improve the performance of your application, especially when making multiple queries in parallel.
Python
The Weaviate Python client 4.7.0 and higher includes an asynchronous client API (WeaviateAsyncClient).
Java
The Weaviate Java client 5.0.0 and higher includes an asynchronous client API (WeaviateAsyncClient).
Questions and feedback
If you have any questions or feedback, let us know in the user forum.