
Ollama Generative AI with Weaviate
Weaviate's integration with Ollama's models allows you to access their models' capabilities directly from Weaviate.
Configure a Weaviate collection to use a generative AI model with Ollama. Weaviate will perform retrieval augmented generation (RAG) using the specified model via your local Ollama instance.
More specifically, Weaviate will perform a search, retrieve the most relevant objects, and then pass them to the Ollama generative model to generate outputs.
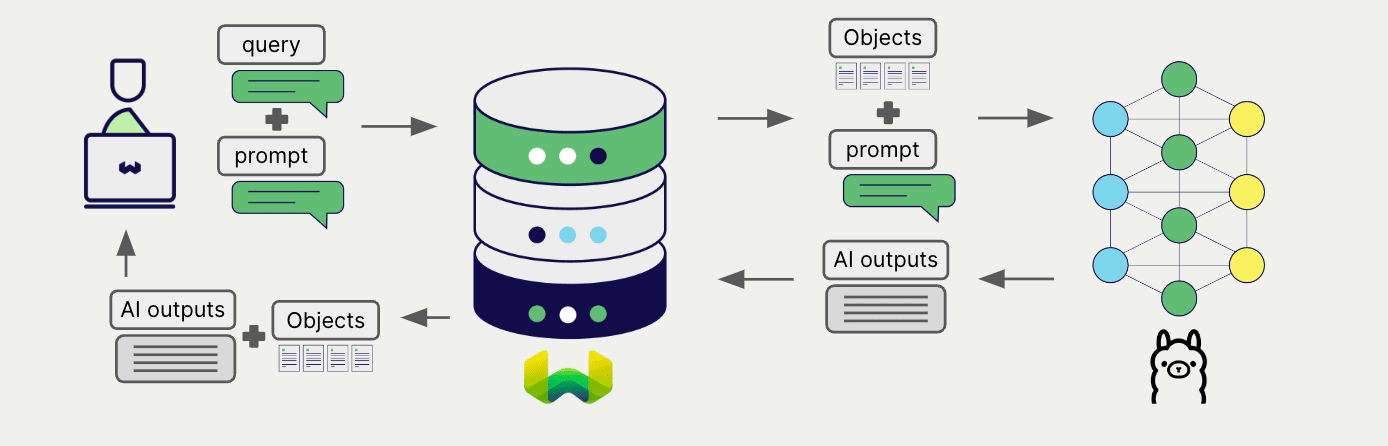
Requirements
Ollama
This integration requires a locally running Ollama instance with your selected model available. Refer to the Ollama documentation for installation and model download instructions.
Weaviate configuration
Your Weaviate instance must be configured with the Ollama generative AI integration (generative-ollama) module.
For Weaviate Cloud (WCD) users
This integration is enabled by default on Weaviate Cloud (WCD) serverless instances.
To use Ollama with Weaviate Cloud, make sure your Ollama server is running and accessible from the Weaviate Cloud instance. If you are running Ollama on your own machine, you may need to expose it to the internet. Carefully consider the security implications of exposing your Ollama server to the internet.
For use cases such as this, consider using a self-hosted Weaviate instance, or another API-based integration method.
For self-hosted users
- Check the cluster metadata to verify if the module is enabled.
- Follow the how-to configure modules guide to enable the module in Weaviate.
Your Weaviate instance must be able to access the Ollama endpoint. If you area a Docker user, specify the Ollama endpoint using host.docker.internal alias to access the host machine from within the container.
Credentials
As this integration connects to a local Ollama container, no additional credentials (e.g. API key) are required. Connect to Weaviate as usual, such as in the examples below.
- Python API v4
- JS/TS API v3
Configure collection
A collection's generative model integration configuration is mutable from v1.25.23, v1.26.8 and v1.27.1. See this section for details on how to update the collection configuration.
Configure a Weaviate index as follows to use an Ollama generative model:
- Python API v4
- JS/TS API v3
from weaviate.classes.config import Configure
client.collections.create(
"DemoCollection",
generative_config=Configure.Generative.ollama(
api_endpoint="http://host.docker.internal:11434", # If using Docker, use this to contact your local Ollama instance
model="llama3" # The model to use, e.g. "phi3", or "mistral", "command-r-plus", "gemma"
)
# Additional parameters not shown
)
await client.collections.create({
name: 'DemoCollection',
generative: weaviate.configure.generative.ollama({
apiEndpoint: 'http://host.docker.internal:11434', // If using Docker, use this to contact your local Ollama instance
model: 'llama3', // The model to use, e.g. 'phi3', or 'mistral', 'command-r-plus', 'gemma'
}),
// Additional parameters not shown
});
The Weaviate server has to be able to reach the Ollama API endpoint. If Weaviate is running in a Docker container and Ollama is running locally, use host.docker.internal to redirect Weaviate from localhost inside the container to localhost on the host machine.
If your Weaviate instance and Ollama instance are hosted in a different way, adjust the API endpoint parameter so it points to your Ollama instance.
The default model is used if no model is specified.
Select a model at runtime
Aside from setting the default model provider when creating the collection, you can also override it at query time.
- Python API v4
- JS/TS Client v3
from weaviate.classes.config import Configure
from weaviate.classes.generate import GenerativeConfig
collection = client.collections.get("DemoCollection")
response = collection.generate.near_text(
query="A holiday film",
limit=2,
grouped_task="Write a tweet promoting these two movies",
generative_provider=GenerativeConfig.ollama(
api_endpoint="http://host.docker.internal:11434", # If using Docker, use this to contact your local Ollama instance
model="llama3" # The model to use, e.g. "phi3", or "mistral", "command-r-plus", "gemma"
),
# Additional parameters not shown
)
import { generativeParameters } from 'weaviate-client';
let response;
const myCollection = client.collections.use("DemoCollection");
response = await myCollection.generate.nearText("A holiday film", {
groupedTask: "Write a tweet promoting these two movies",
config: generativeParameters.ollama({
apiEndpoint: 'http://host.docker.internal:11434', // If using Docker, use this to contact your local Ollama instance
model: 'llama3', // The model to use, e.g. 'phi3', or 'mistral', 'command-r-plus', 'gemma'
}),
}, {
limit: 2,
}
// Additional parameters not shown
)
Retrieval augmented generation
After configuring the generative AI integration, perform RAG operations, either with the single prompt or grouped task method.
Single prompt
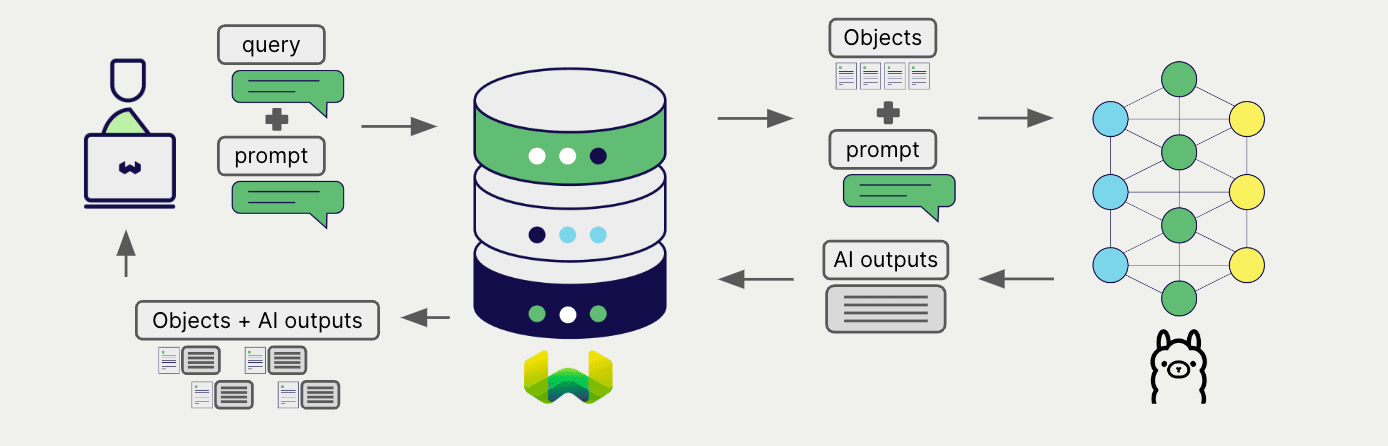
To generate text for each object in the search results, use the single prompt method.
The example below generates outputs for each of the n search results, where n is specified by the limit parameter.
When creating a single prompt query, use braces {} to interpolate the object properties you want Weaviate to pass on to the language model. For example, to pass on the object's title property, include {title} in the query.
- Python API v4
- JS/TS API v3
collection = client.collections.get("DemoCollection")
response = collection.generate.near_text(
query="A holiday film", # The model provider integration will automatically vectorize the query
single_prompt="Translate this into French: {title}",
limit=2
)
for obj in response.objects:
print(obj.properties["title"])
print(f"Generated output: {obj.generated}") # Note that the generated output is per object
let response;
const myCollection = client.collections.use("DemoCollection");
let myCollection = client.collections.get('DemoCollection');
const singlePromptResults = await myCollection.generate.nearText('A holiday film', {
singlePrompt: `Translate this into French: {title}`,
}, {
limit: 2,
});
for (const obj of singlePromptResults.objects) {
console.log(obj.properties['title']);
console.log(`Generated output: ${obj.generative?.text}`); // Note that the generated output is per object
}
Grouped task
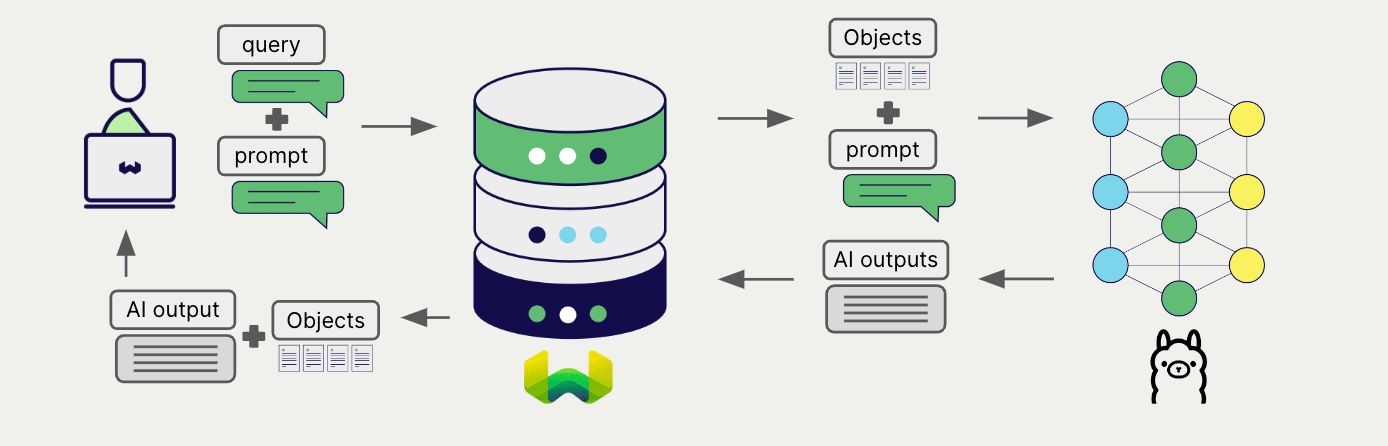
To generate one text for the entire set of search results, use the grouped task method.
In other words, when you have n search results, the generative model generates one output for the entire group.
- Python API v4
- JS/TS API v3
collection = client.collections.get("DemoCollection")
response = collection.generate.near_text(
query="A holiday film", # The model provider integration will automatically vectorize the query
grouped_task="Write a fun tweet to promote readers to check out these films.",
limit=2
)
print(f"Generated output: {response.generated}") # Note that the generated output is per query
for obj in response.objects:
print(obj.properties["title"])
let response;
const myCollection = client.collections.use("DemoCollection");
let myCollection = client.collections.get('DemoCollection');
const groupedTaskResults = await myCollection.generate.nearText('A holiday film', {
groupedTask: `Write a fun tweet to promote readers to check out these films.`,
}, {
limit: 2,
});
console.log(`Generated output: ${groupedTaskResults.generative?.text}`); // Note that the generated output is per query
for (const obj of groupedTaskResults.objects) {
console.log(obj.properties['title']);
}
RAG with images
You can also supply images as a part of the input when performing retrieval augmented generation in both single prompts and grouped tasks.
- Python API v4
- JS/TS API v3
import base64
import requests
from weaviate.classes.generate import GenerativeConfig, GenerativeParameters
src_img_path = "https://upload.wikimedia.org/wikipedia/commons/thumb/b/b0/Winter_forest_silver.jpg/960px-Winter_forest_silver.jpg"
base64_image = base64.b64encode(requests.get(src_img_path).content).decode('utf-8')
prompt = GenerativeParameters.grouped_task(
prompt="Which movie is closest to the image in terms of atmosphere",
images=[base64_image], # A list of base64 encoded strings of the image bytes
# image_properties=["img"], # Properties containing images in Weaviate
)
jeopardy = client.collections.get("DemoCollection")
response = jeopardy.generate.near_text(
query="Movies",
limit=5,
grouped_task=prompt,
generative_provider=GenerativeConfig.ollama(),
)
# Print the source property and the generated response
for o in response.objects:
print(f"Title property: {o.properties['title']}")
print(f"Grouped task result: {response.generative.text}")
References
Available models
See the Ollama documentation for a list of available models. Note that this list includes both generative models and embedding models; specify a generative model for the generative-ollama module.
Download the desired model with ollama pull <model-name>.
If no model is specified, the default model (llama3) is used.
Further resources
Other integrations
Code examples
Once the integrations are configured at the collection, the data management and search operations in Weaviate work identically to any other collection. See the following model-agnostic examples:
- The how-to: manage data guides show how to perform data operations (i.e. create, update, delete).
- The how-to: search guides show how to perform search operations (i.e. vector, keyword, hybrid) as well as retrieval augmented generation.
References
If you have any questions or feedback, let us know in the user forum.