
Use Cases (Motivation)
On this page you will find four use cases which motivate replication for Weaviate. Each of them serves a different purpose and, as a result, may require different configuration.
High Availability (Redundancy)
High availability of a database means that the database is designed to operate continuously without service interruptions. That means that the database system should be tolerant to failures and errors, which should be handled automatically.
This is solved by replication, where redundant nodes can handle requests when other nodes fail.
Weaviate considers cluster metadata operations critical, so it treats them differently than it does data operations.
From Weaviate v1.25, Weaviate uses the Raft consensus algorithm for cluster metadata replication. This is a leader-based consensus algorithm, where a leader node is responsible for cluster metadata changes. Use of Raft ensures that cluster metadata changes are consistent across the cluster, even in the event of (a minority of) node failures.
Prior to Weaviate v1.25, Weaviate used a leaderless design with two-phase commit for cluster metadata operations. This required all nodes for a cluster metadata operation such as a collection definition update, or a tenant state update. This meant that one or more nodes being down temporarily prevented cluster metadata operations. Additionally, only one cluster metadata operation could be processed at a time.
Regarding data operations, read or write queries may still be available in a distributed database structure even when a node goes down, so single points of failure are eliminated. Users' queries will be automatically (unnoticeably) redirected to an available replica node.
Examples of applications where High Availability is desired are emergency services, enterprise IT systems, social media, and website search. Nowadays, users are used to highly available applications, so they expect little to no downtime. For e.g. website search, service (read queries) should not be interrupted if a node goes down. In that case, if writing is temporarily unavailable, it is acceptable and in the worst case scenario the site search will be stale, but still available for read requests.
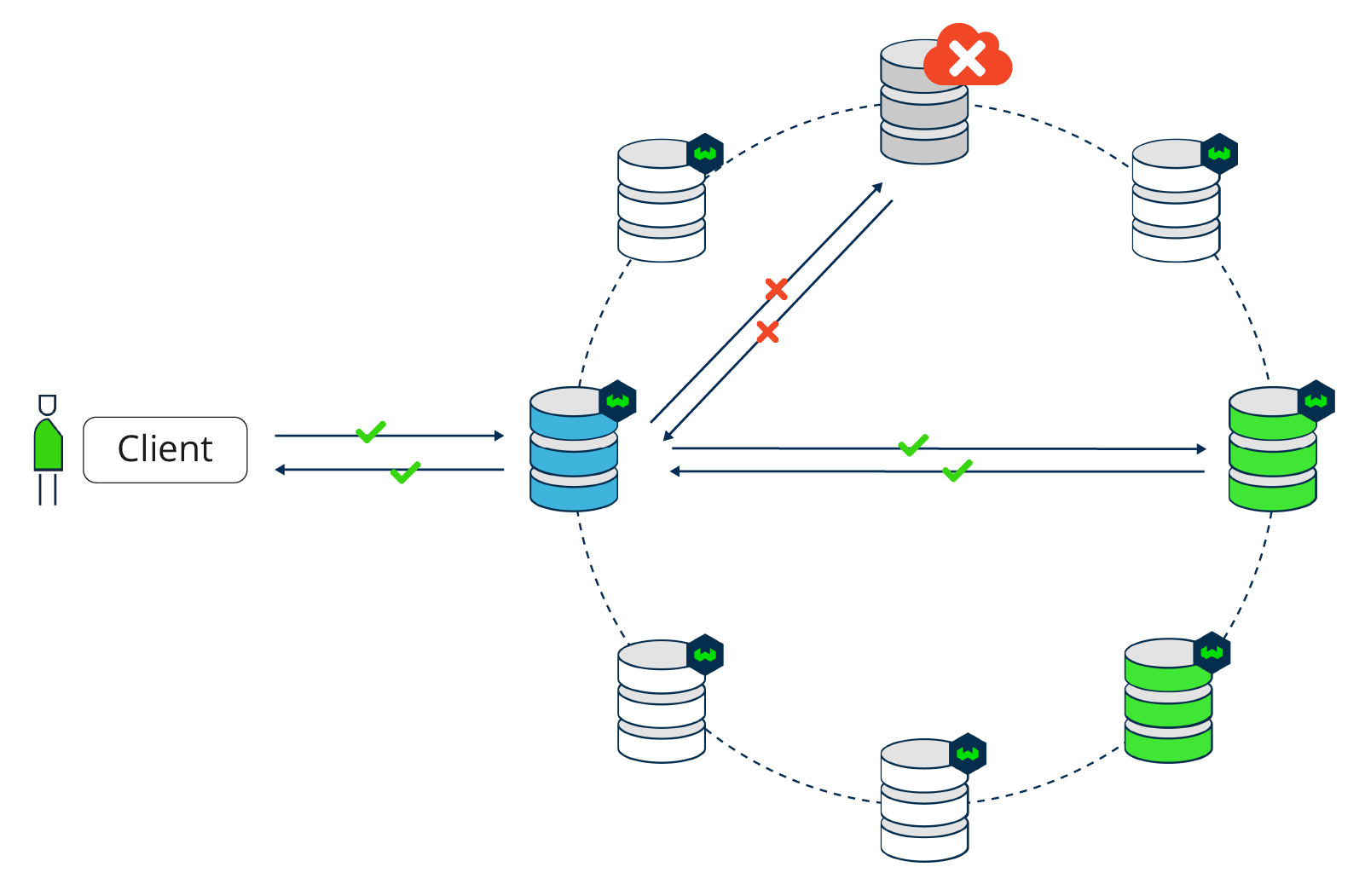
High Availability can be illustrated by the following configuration examples:
- Write
ALL, ReadONE- There is no High Availability during writing becauseALLnodes need to respond to write requests. There is High Availability on read requests: all nodes can go down except one while reading and the read operations are still available. - Write
QUORUM, ReadQUORUM(n/2+1) - A minority of nodes could go down, the majority of nodes should be up and running, and you can still do both reading and writing. - Write
ONE, ReadONE- This is the most available configuration. All but one node can go down and both read and write operations are still possible. Note that this super High Availability comes with a cost of Low Consistency guarantees. Due to eventual consistency, your application must be able to deal with temporarily showing out-of-date data.
Increased (Read) Throughput
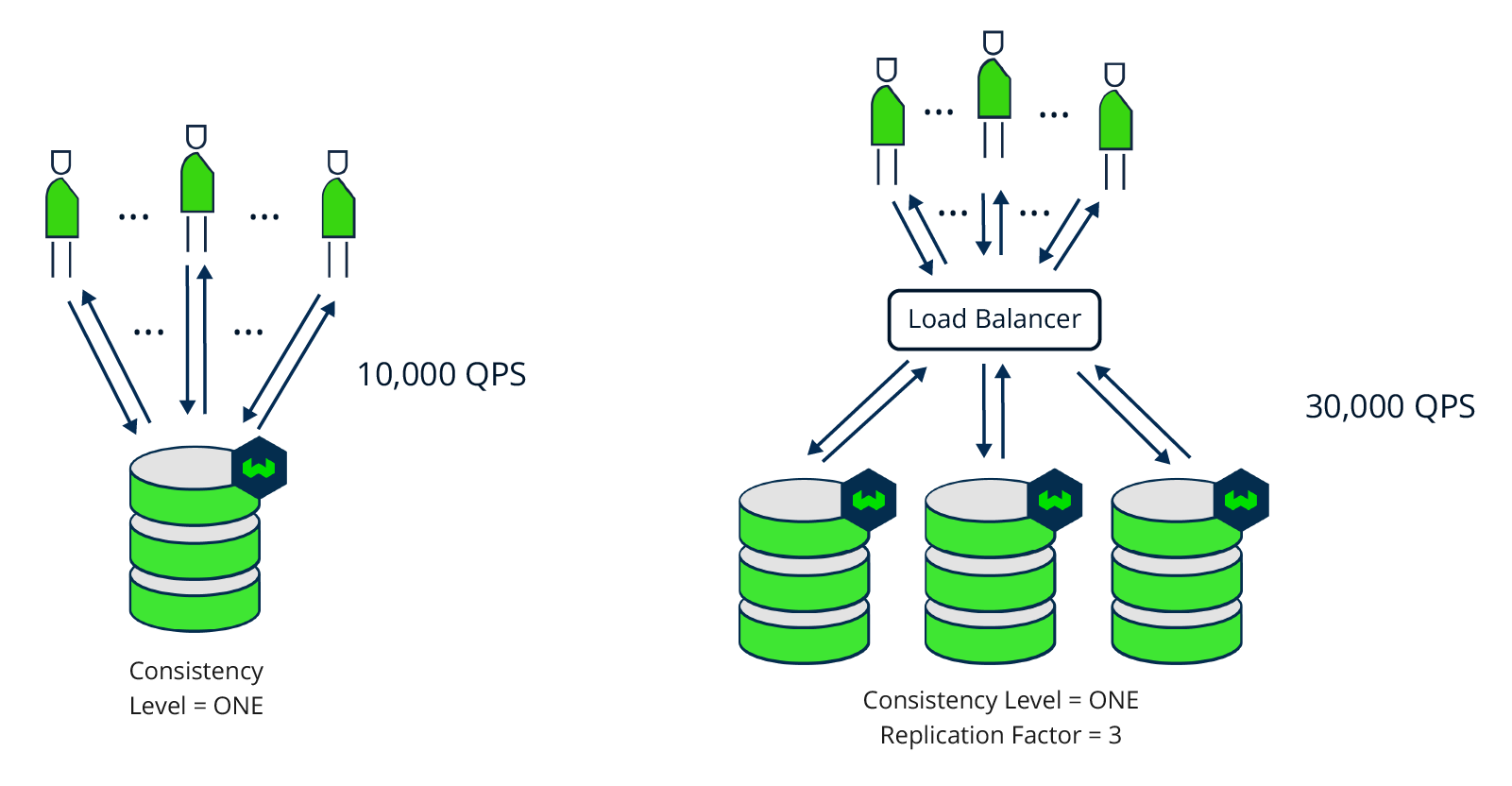
When you have many read requests on your Weaviate instance, for example because you're building an application for many users, the database setup should be able to support high throughput. Throughput is measured in Queries Per Second (QPS). Adding extra server nodes to your database setup means that the throughput scales with it. The more server nodes, the more users (read operations) the system will be able to handle. Thus, replicating your Weaviate instance increases throughput.
When reading is set to a low consistency level (i.e. ONE), then scaling the replication factor (i.e. the number of database server nodes) increases the throughput linearly. For example, when the read consistency level is ONE, if one node can reach 10,000 QPS, then a setup with 3 replica nodes can receive 30,000 QPS.
Zero Downtime Upgrades
Without replication, there is a window of downtime when you update a Weaviate instance. The single node needs to stop, update and restart before it's ready to serve again. With replication, upgrades are done using a rolling update, in which at most one node is unavailable at the same time while the other nodes can still serve traffic.
As an example, consider you're updating the version of a Weaviate instance from v1.19 to v1.20. Without replication there is a window of downtime:
- Node is ready to serve traffic
- Node is stopped, no requests can be served
- Node image is replaced with newer version
- Node is restarted
- Node takes time to be ready
- Node is ready to serve traffic.
From step 2 until step 6 the Weaviate server cannot receive and respond to any requests. This leads to bad user experience.
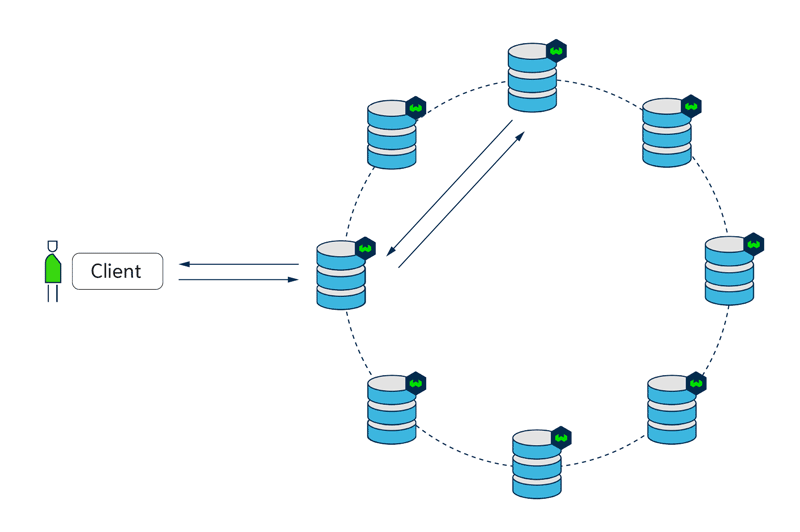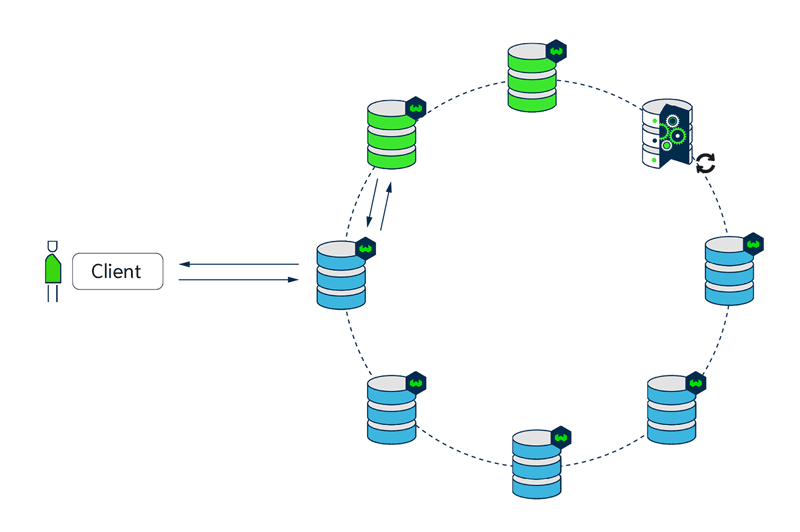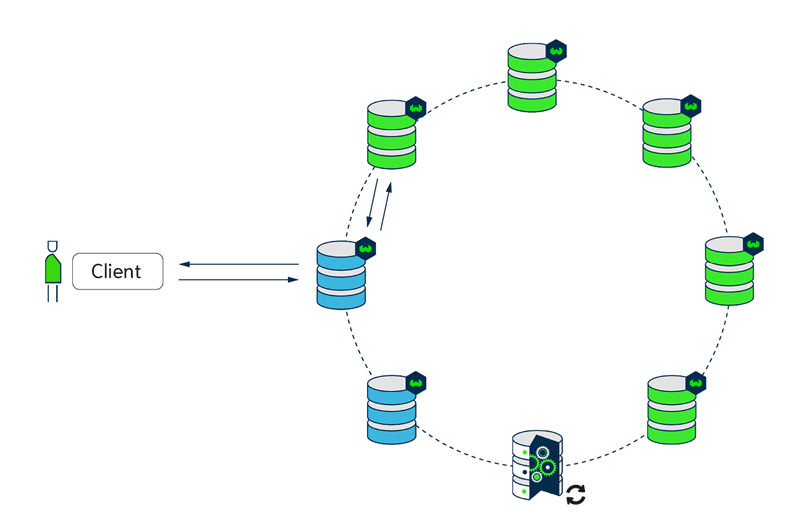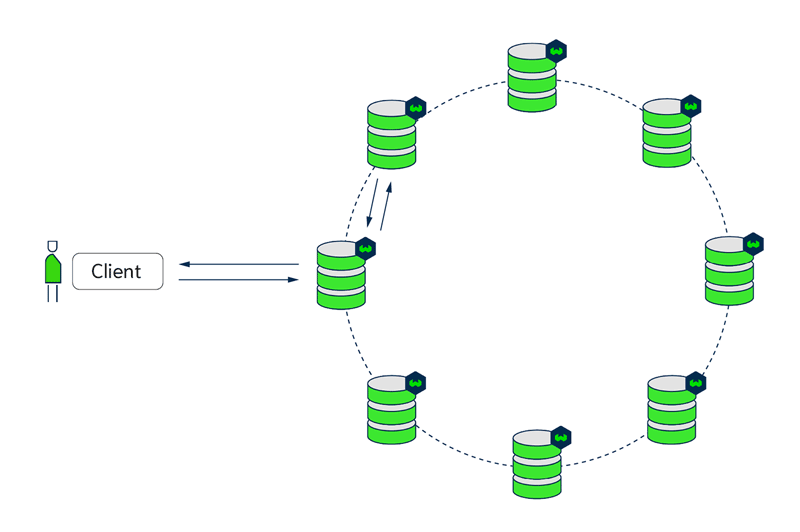
With replication (e.g. replication factor of 3), upgrades to the Weaviate version are done using a rolling update. At most one node will be unavailable at the same time, so all other nodes can still serve traffic.
- 3 nodes ready to serve traffic
- node 1 being replaced, nodes 2,3 can serve traffic
- node 2 being replaced, nodes 1,3 can serve traffic
- node 3 being replaced, nodes 1,2 can serve traffic
Regional Proximity
When users are located in different regional areas (e.g. Iceland and Australia as extreme examples), you cannot ensure low latency for all users due to the physical distance between the database server and the users. You can only place the database server at one geographical location, so the question arises where you put the server:
Option 1 - Put the cluster in the middle (e.g. India).
All users will have relatively high latency, since data needs to travel between Iceland and India, and Australia and India.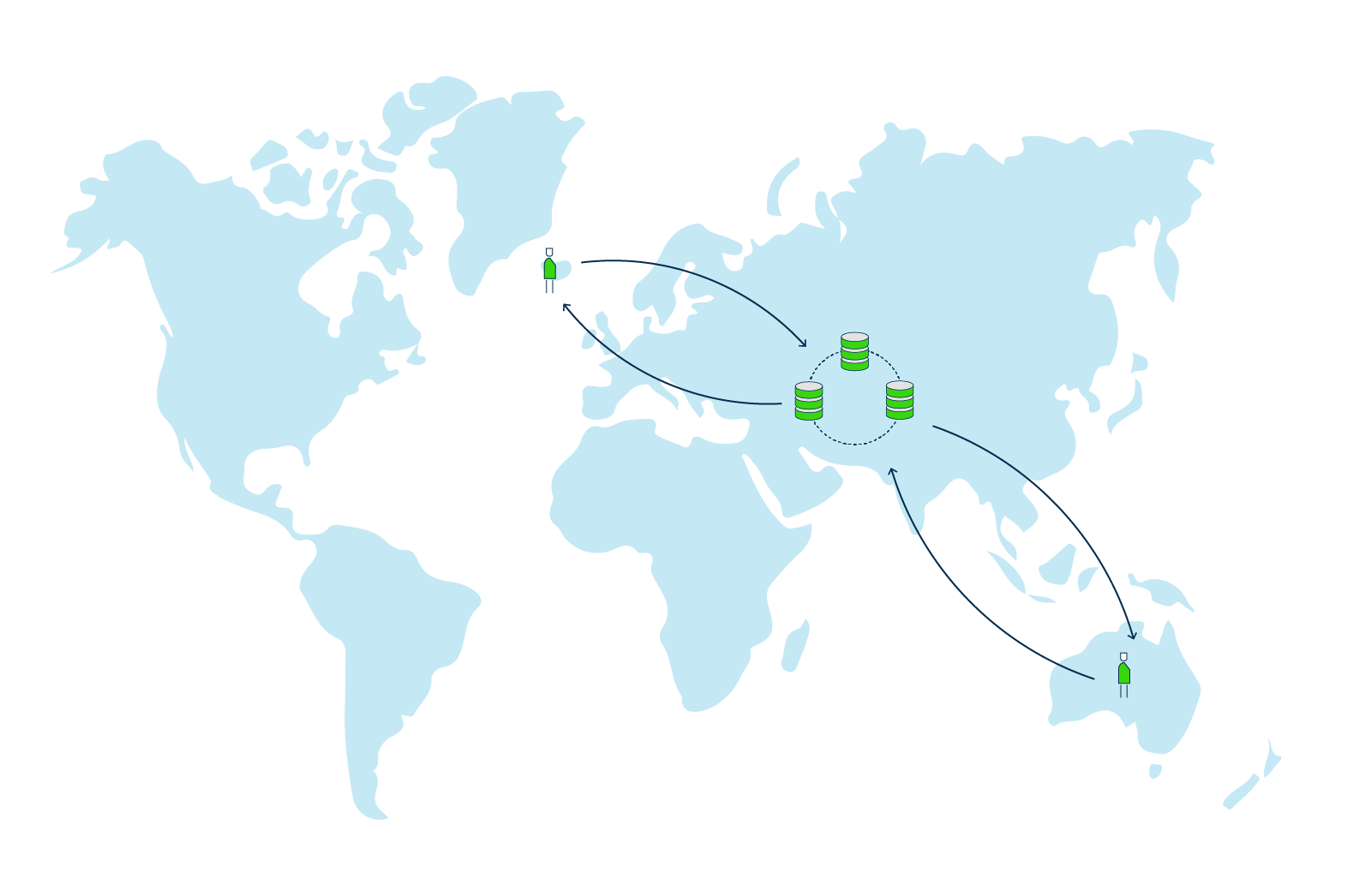
Option 2 - Put the cluster close to one user group (e.g. Iceland)
Users from Iceland have very low latency while users from Australia experience relatively high latency since data needs to travel a long distance.Another option arises when you have the option to replicate your data cluster to two different geographical locations. This is called Multi-Datacenter (Multi-DC) replication.
Option 3 - Multi-DC replication with server clusters in both Iceland and Australia.
Users from Iceland and Australia now both experience low latency, because each user group is served from local clusters.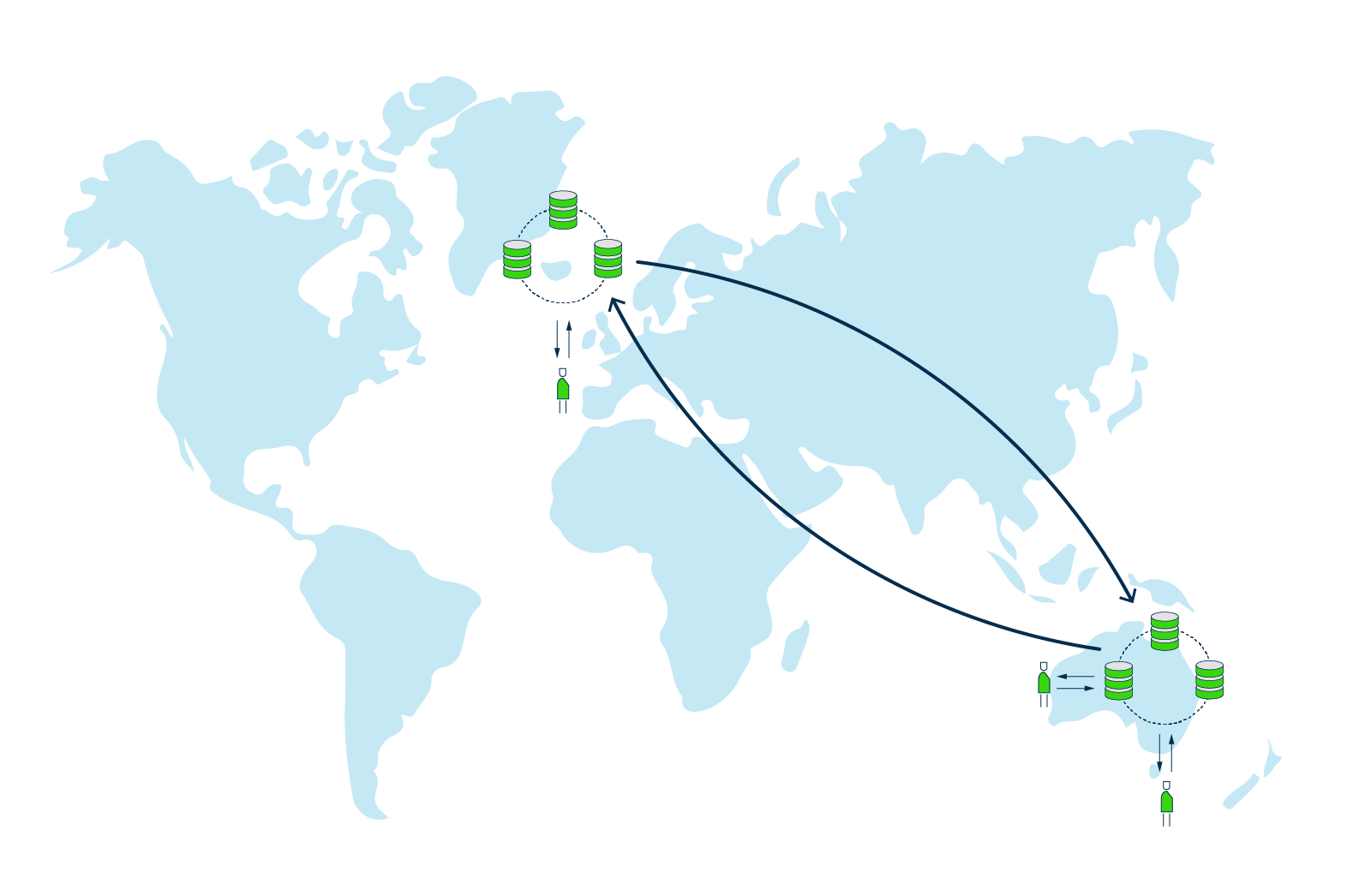
Multi-DC replication also comes with the additional benefit that data is redundant on more physical locations, which means that in the rare case of an entire datacenter going down, data can still be served from another location.
Note, Regional Proximity depends on the Multi-Datacenter feature of replication, which you can vote for here.
Questions and feedback
If you have any questions or feedback, let us know in the user forum.