
Consistency
The replication factor in Weaviate determines how many copies of shards (also called replicas) will be stored across a Weaviate cluster.
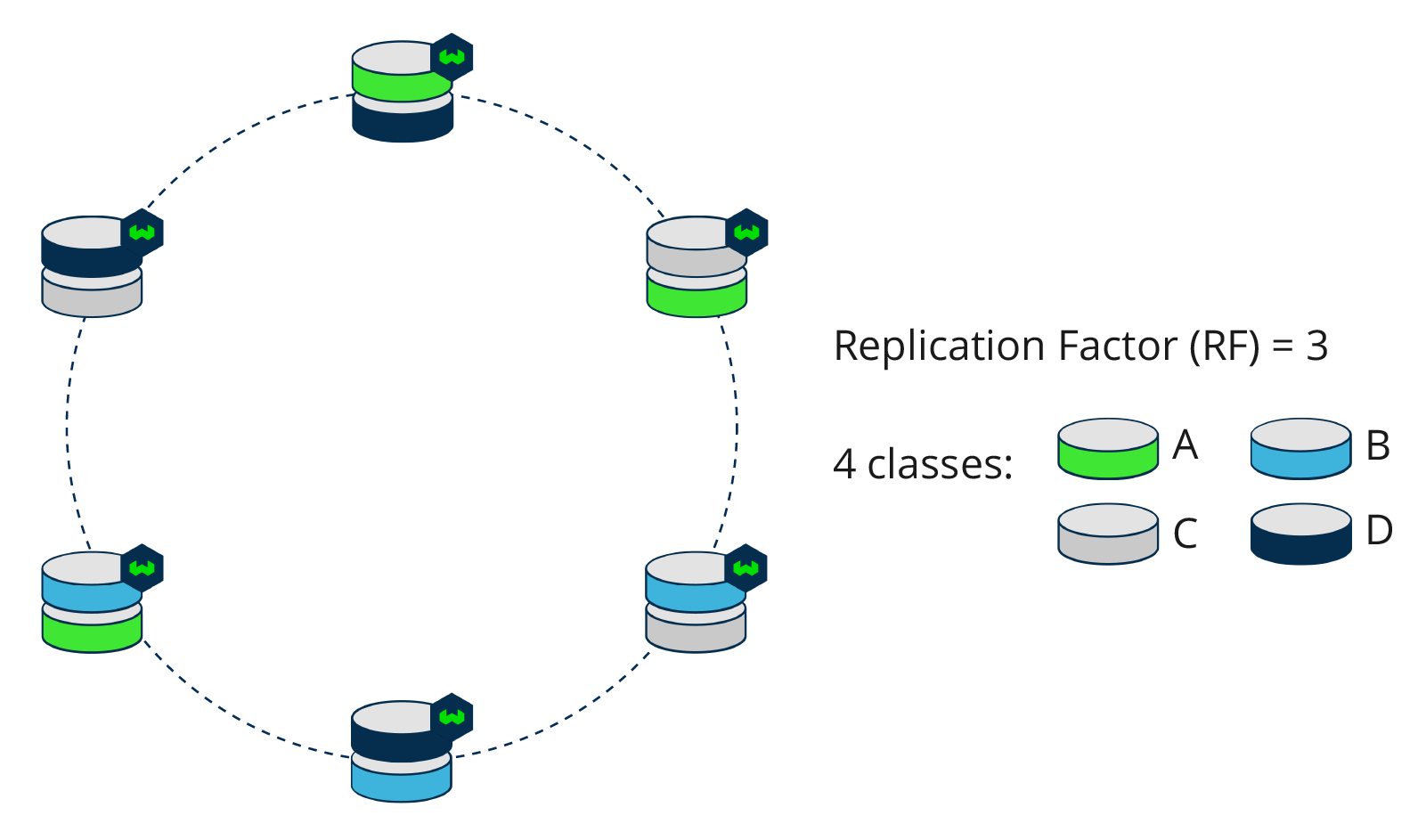
When the replication factor is > 1, consistency models balance the system's reliability, scalability, and/or performance requirements.
Weaviate uses multiple consistency models. One for its cluster metadata and another for its data objects.
Consistency models in Weaviate
Weaviate uses the Raft consensus algorithm for cluster metadata replication. Cluster metadata in this context includes the collection definitions and tenant activity statuses. This allows cluster metadata updates to occur even when some nodes are down.
Data objects are replicated using a leaderless design using tunable consistency levels. So, data operations can be tuned to be more consistent or more available, depending on the desired tradeoff.
These designs reflect the trade-off between consistency and availability that is described in the CAP Theorem.
The strength of consistency can be determined by applying the following conditions:
- If r + w > n, then the system is strongly consistent.
- r is the consistency level of read operations
- w is the consistency level of write operations
- n is the replication factor (number of replicas)
- If r + w <= n, then eventual consistency is the best that can be reached in this scenario.
Cluster metadata
The cluster metadata in Weaviate makes use of the Raft algorithm.
From v1.25, Weaviate uses the Raft consensus algorithm for cluster metadata replication. Raft is a consensus algorithm with an elected leader node that coordinates replication across the cluster using a log-based approach.
As a result, each request that changes the cluster metadata will be sent to the leader node. The leader node will apply the change to its logs, then propagate the changes to the follower nodes. Once a quorum of nodes has acknowledged the cluster metadata change, the leader node will commit the change and confirm it to the client.
This architecture ensures that cluster metadata changes are consistent across the cluster, even in the event of (a minority of) node failures.
Pre-v1.25 cluster metadata consensus algorithm
Prior to using Raft, a cluster metadata update was done via a Distributed Transaction algorithm. This is a set of operations that is done across databases on different nodes in the distributed network. Weaviate used a two-phase commit (2PC) protocol, which replicates the cluster metadata updates in a short period of time (milliseconds).
A clean (without fails) execution has two phases:
- The commit-request phase (or voting phase), in which a coordinator node asks each node whether they are able to receive and process the update.
- The commit phase, in which the coordinator commits the changes to the nodes.
Collection definition requests in queries
v1.27.10, v1.28.4Some queries require the collection definition. Prior to the introduction of this feature, every such query led to the local (requesting) node to fetch the collection definition from the leader node. This meant that the definition was strongly consistent, but it could lead to additional traffic and load.
Where available, the COLLECTION_RETRIEVAL_STRATEGY environment variable can be set to LeaderOnly, LocalOnly, or LeaderOnMismatch.
LeaderOnly(default): Always requests the definition from the leader node. This is the most consistent behavior but can lead to higher intra-cluster traffic.LocalOnly: Always use the local definition; leading to eventually consistent behavior while reducing intra-cluster traffic.LeaderOnMismatch: Checks if the local definition is outdated, and requests the definition if necessary. Balances consistency and intra-cluster traffic.
The default behavior is LeaderOnly to achieve strong consistency. However, LocalOnly and LeaderOnMismatch can be used to reduce intra-cluster traffic according to the desired consistency level.
Data objects
Weaviate uses two-phase commits for objects, adjusted for the consistency level. For example for a QUORUM write (see below), if there are 5 nodes, 3 requests will be sent out, each of them using a 2-phase commit under the hood.
As a result, data objects in Weaviate are eventually consistent. Eventual consistency provides BASE semantics:
- Basically available: reading and writing operations are as available as possible
- Soft-state: there are no consistency guarantees since updates might not yet have converged
- Eventually consistent: if the system functions long enough, after some writes, all nodes will be consistent.
Weaviate uses eventual consistency to improve availability. Read and write consistency are tunable, so you can tradeoff between availability and consistency to match your application needs.
The animation below is an example of how a write or a read is performed with Weaviate with a replication factor of 3 and 8 nodes. The blue node acts as the coordinator node. The consistency level is set to QUORUM, so the coordinator node only waits for two out of three responses before sending the result back to the client.
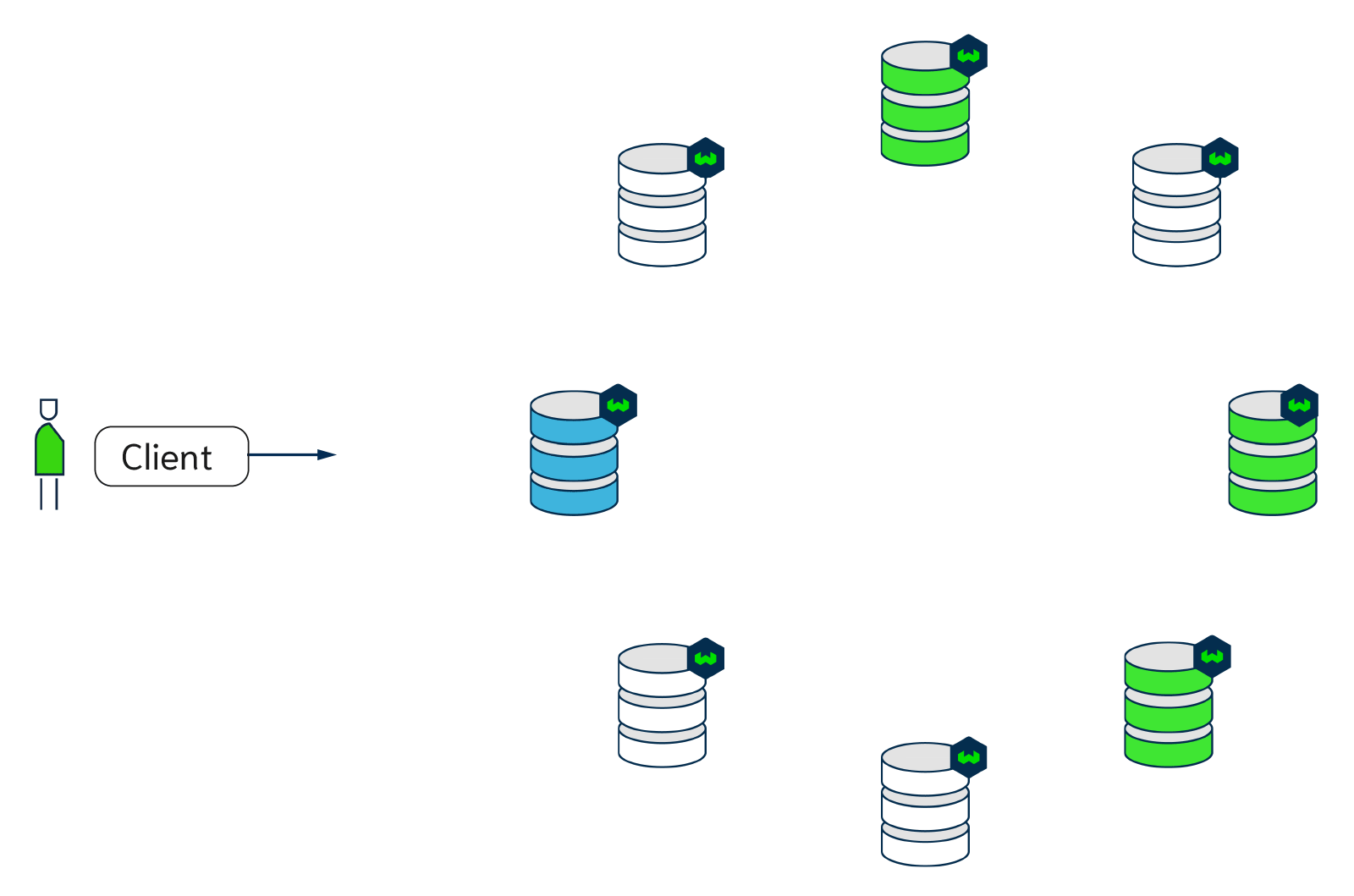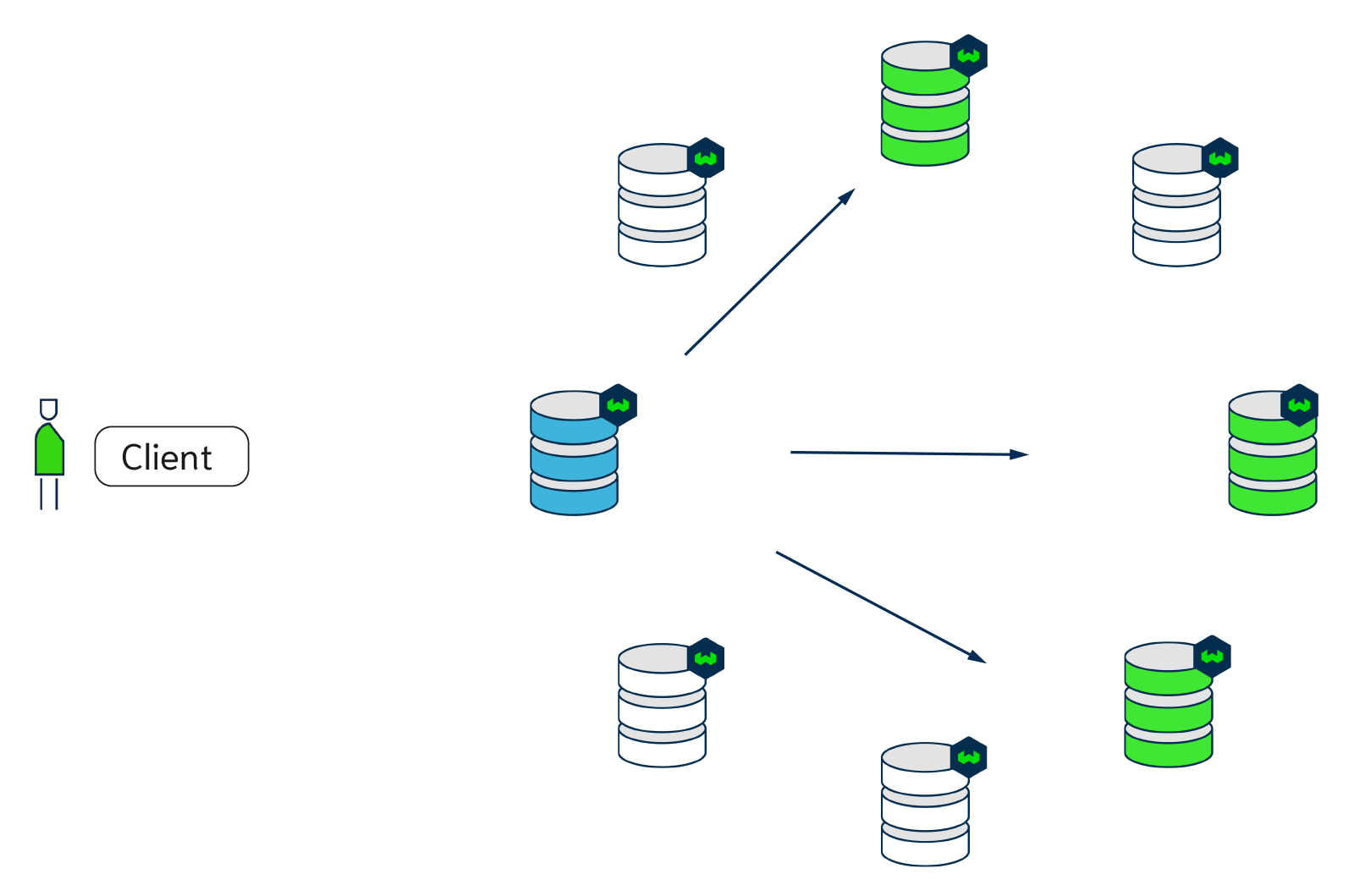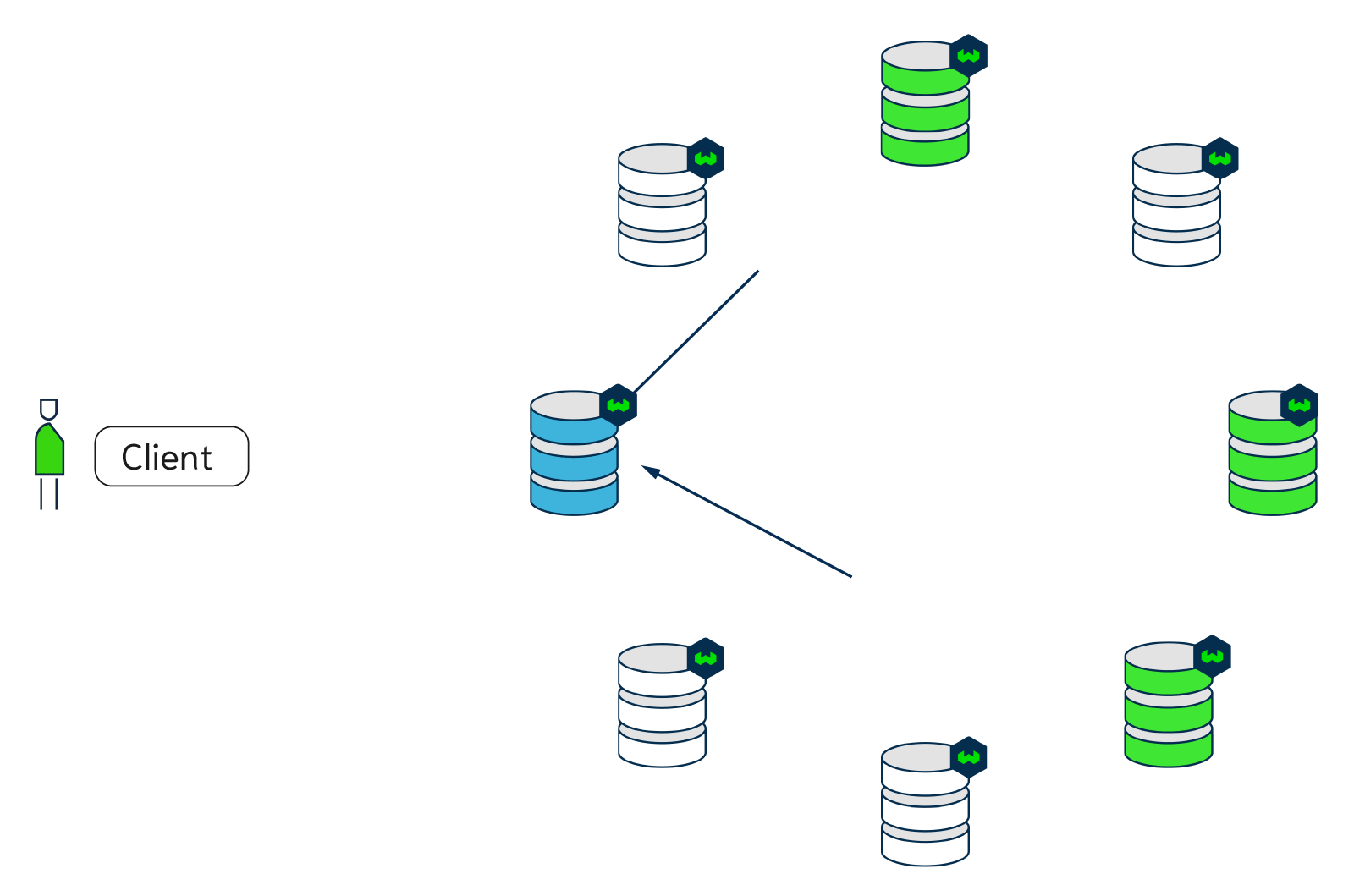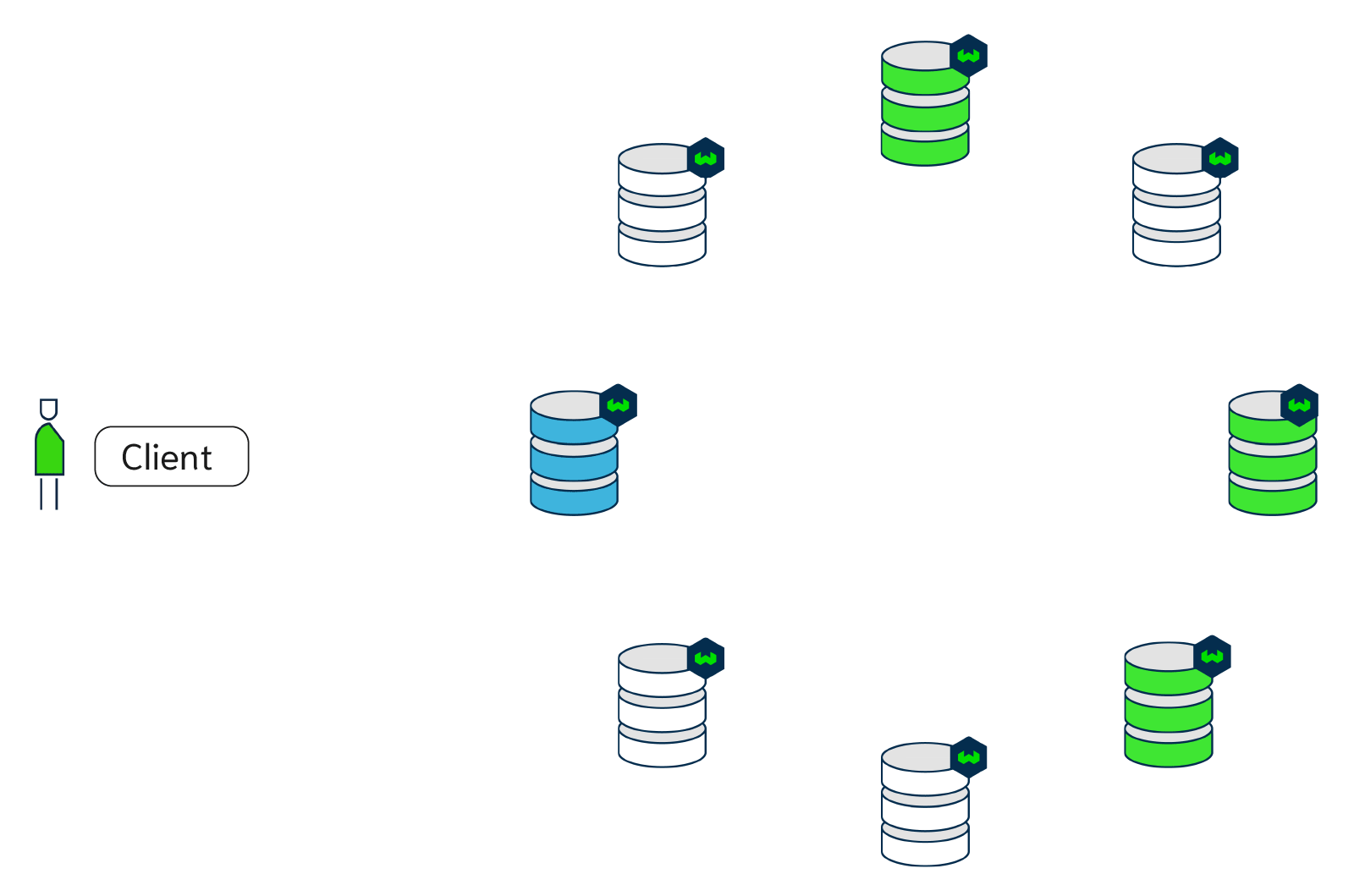
Tunable write consistency
Adding or changing data objects are write operations.
Write operations are tunable starting with Weaviate v1.18, to ONE, QUORUM (default) or ALL. In v1.17, write operations are always set to ALL (highest consistency).
The main reason for introducing configurable write consistency in v1.18 is because that is also when automatic repairs are introduced. A write will always be written to n (replication factor) nodes, regardless of the chosen consistency level. The coordinator node however waits for acknowledgments from ONE, QUORUM or ALL nodes before it returns. To guarantee that a write is applied everywhere without the availability of repairs on read requests, write consistency is set to ALL for now. Possible settings in v1.18+ are:
- ONE - a write must receive an acknowledgment from at least one replica node. This is the fastest (most available), but least consistent option.
- QUORUM - a write must receive an acknowledgment from at least
QUORUMreplica nodes.QUORUMis calculated as n / 2 + 1, where n is the number of replicas (replication factor). For example, using a replication factor of 6, the quorum is 4, which means the cluster can tolerate 2 replicas down. - ALL - a write must receive an acknowledgment from all replica nodes. This is the most consistent, but 'slowest' (least available) option.
Figure below: a replicated Weaviate setup with write consistency of ONE. There are 8 nodes in total out of which 3 replicas.
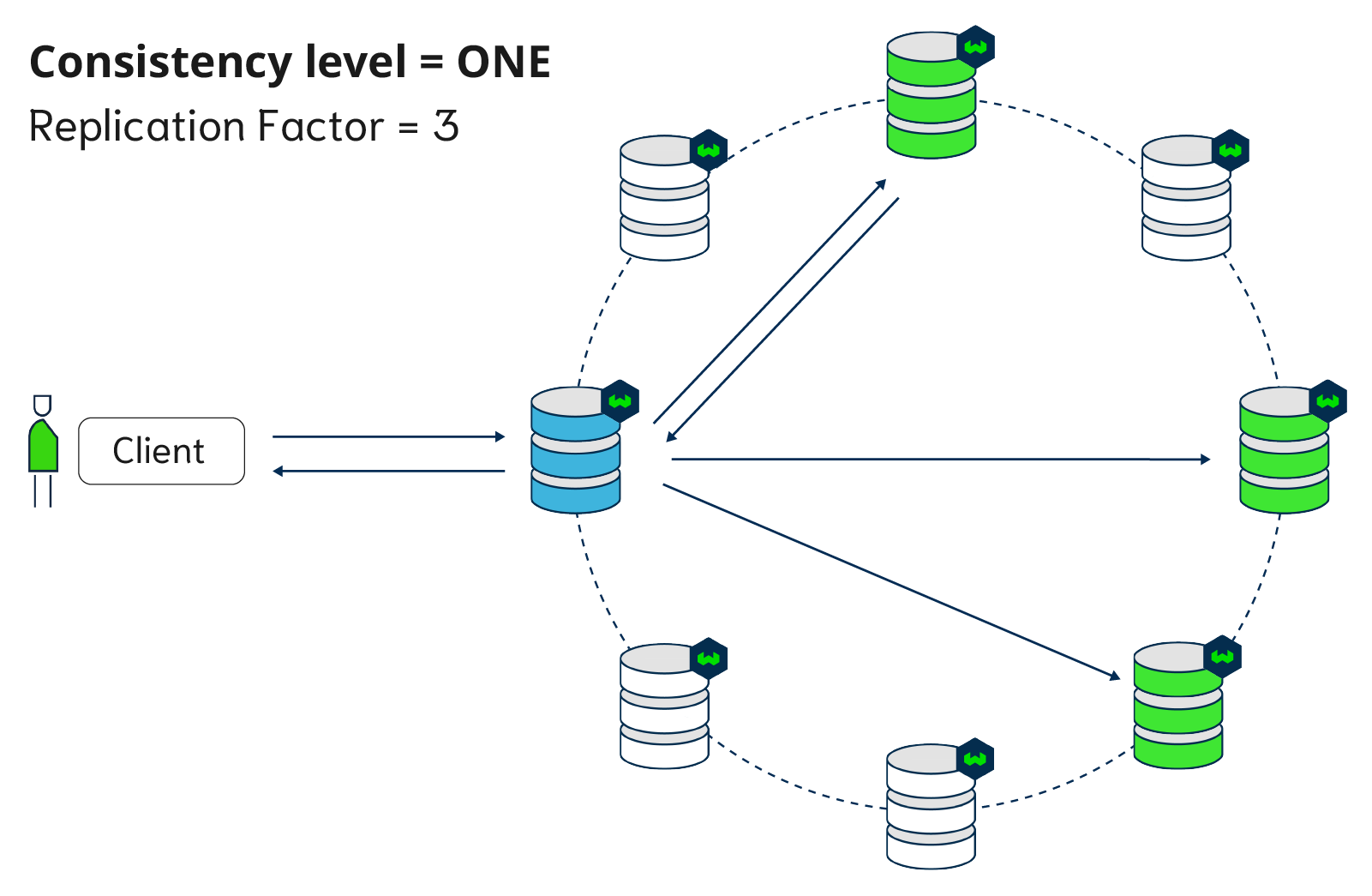
Figure below: a replicated Weaviate setup with Write Consistency of QUORUM (n/2+1). There are 8 nodes in total, out of which 3 replicas.
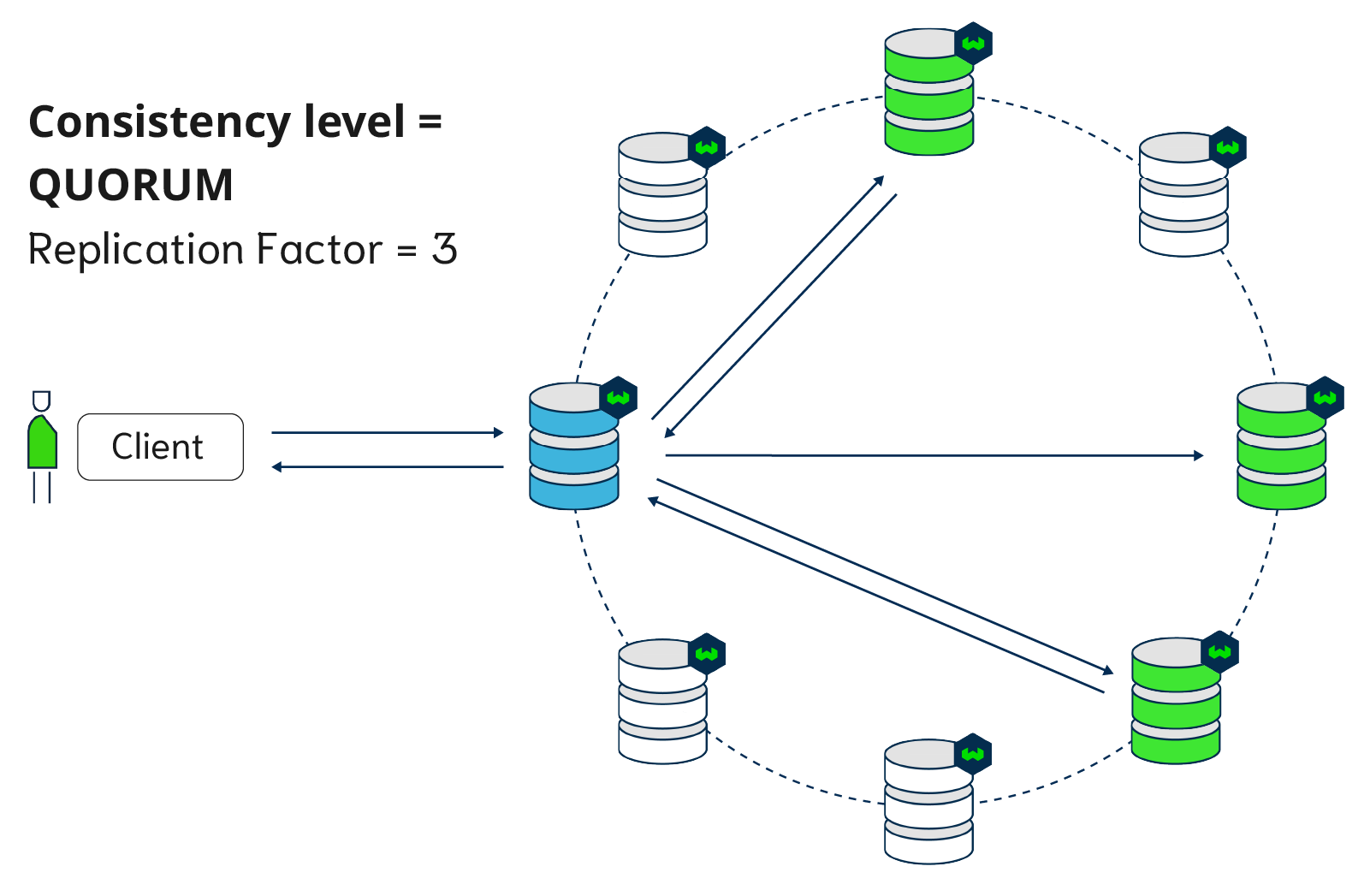
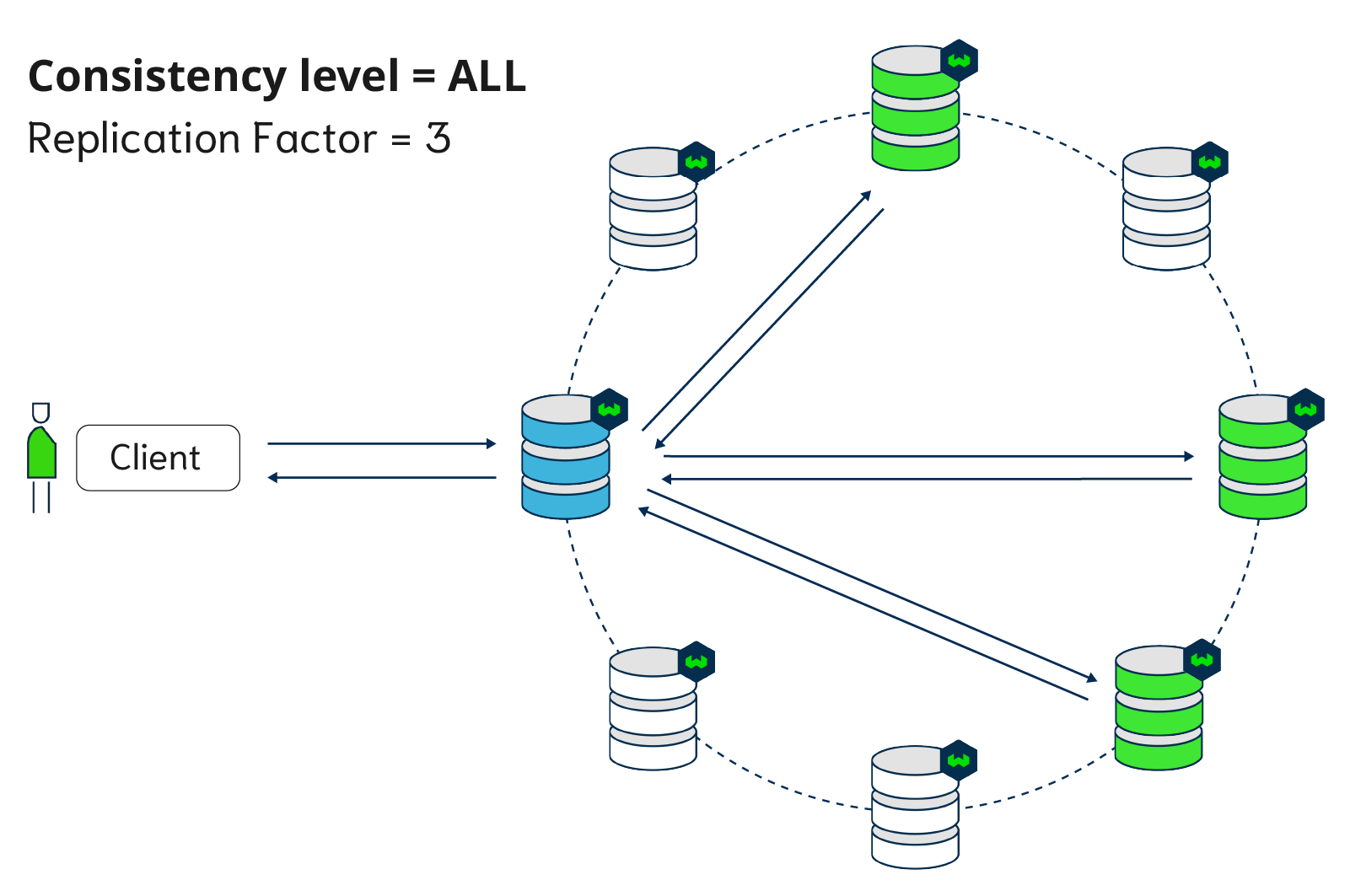
Figure below: a replicated Weaviate setup with Write Consistency of ALL. There are 8 nodes in total, out of which 3 replicas.
Tunable read consistency
Read operations are GET requests to data objects in Weaviate. Like write, read consistency is tunable, to ONE, QUORUM (default) or ALL.
Prior to v1.18, read consistency was tunable only for requests that obtained an object by id, and all other read requests had a consistency of ALL.
The following consistency levels are applicable to most read operations:
- Starting with
v1.18, consistency levels are applicable to REST endpoint operations. - Starting with
v1.19, consistency levels are applicable to GraphQLGetrequests. - All gRPC based read and write operations support tunable consistency levels.
- ONE - a read response must be returned by at least one replica. This is the fastest (most available), but least consistent option.
- QUORUM - a response must be returned by
QUORUMamount of replica nodes.QUORUMis calculated as n / 2 + 1, where n is the number of replicas (replication factor). For example, using a replication factor of 6, the quorum is 4, which means the cluster can tolerate 2 replicas down. - ALL - a read response must be returned by all replicas. The read operation will fail if at least one replica fails to respond. This is the most consistent, but 'slowest' (least available) option.
Examples:
ONE
In a single datacenter with a replication factor of 3 and a read consistency level of ONE, the coordinator node will wait for a response from one replica node.QUORUM
In a single datacenter with a replication factor of 3 and a read consistency level ofQUORUM, the coordinator node will wait for n / 2 + 1 = 3 / 2 + 1 = 2 replicas nodes to return a response.ALL
In a single datacenter with a replication factor of 3 and a read consistency level ofALL, the coordinator node will wait for all 3 replicas nodes to return a response.
Tunable consistency strategies
Depending on the desired tradeoff between consistency and speed, below are three common consistency level pairings for write / read operations. These are minimum requirements that guarantee eventually consistent data:
QUORUM/QUORUM=> balanced write and read latencyONE/ALL=> fast write and slow read (optimized for write)ALL/ONE=> slow write and fast read (optimized for read)
Tunable consistency and queries
Note that tunable consistency levels for read operations do not affect consistency of the list of objects returned by a query. In other words, the list of object UUIDs returned by a query depends only on the coordinator node's (and any other required shards') local index, and is independent of the read consistency level.
This is due to the fact that each query is performed by the coordinator node and any other shards required to answer the query. Even if the read consistency level is set to ALL, it does not mean that multiple replicas will be queried and the results merged together.
Where the read consistency level is applied is in retrieving the identified objects from the replicas. For example, if the read consistency level is set to ALL, the coordinator node will wait for all replicas to return the identified objects. And if the read consistency level is set to ONE, the coordinator node may simply return the objects from itself.
In other words, the read consistency level only affects which versions of the objects are retrieved, but it does not lead to a more (or less) consistent query result.
By default, Weaviate writes to all nodes on an insert/update/delete. So, most of the time this won't matter as all shards will have identical local indexes to each other. This is a rare care which may only occur if there is a problem, such as a node being down, or there is a network problem.
Tenant states and data objects
Each tenant in a multi-tenant collection has a configurable tenant state, which determines the availability and location of the tenant's data. The tenant state can be set to active, inactive, or offloaded.
An active tenant's data should be available for queries and updates, while inactive or offloaded tenants are not.
However, there can be a delay between the time a tenant state is set, and when the tenant's data reflects the (declarative) tenant state.
As a result, a tenant's data may be available for queries for a period of time even if the tenant state is set to inactive or offloaded. Conversely, a tenant's data may not be available for queries and updates for a period of time even if the tenant state is set to active.
For speed, data operations on a tenant occur independently of any tenant activity status operations. As a result, tenant states are not updated by repair-on-read operations.
Repairs
In distributed systems like Weaviate, object replicas can become inconsistent due to any number of reasons - network issues, node failures, or timing conflicts. When Weaviate detects inconsistent data across replicas, it attempts to repair the out of sync data.
Weaviate uses async replication, deletion resolution and repair-on-read strategies to maintain consistency across replicas.
Async replication
v1.26Async replication is a background synchronization process in Weaviate that ensures eventual consistency across nodes storing the same data. When each shard is replicated across multiple nodes, async replication guarantees that all nodes holding copies of the same data remain in sync by periodically comparing and propagating data.
It uses a Merkle tree (hash tree) algorithm to monitor and compare the state of nodes within a cluster. If the algorithm identifies an inconsistency, it resyncs the data on the inconsistent node.
Repair-on-read works well with one or two isolated repairs. Async replication is effective in situations where there are many inconsistencies. For example, if an offline node misses a series of updates, async replication quickly restores consistency when the node returns to service.
Async replication supplements the repair-on-read mechanism. If a node becomes inconsistent between sync checks, the repair-on-read mechanism catches the problem at read time.
To activate async replication, set asyncEnabled to true in the replicationConfig section of your collection definition. Visit the How-to: Replication page to learn more about the available async replication settings.
Memory and performance considerations for async replication
v1.29Async replication uses a hash tree to compare and synchronize data between the database cluster nodes, based on objects' latest update time. The additional memory required for this process is determined by the height of the hash tree (H). A higher hash tree uses more memory but allows faster hashing, reducing the time required to detect and repair inconsistencies.
The trade-offs can be summarized like this:
- Higher
H: Higher memory usage, faster replication. - Lower
H: Lower memory usage, slower replication.
Each tenant is backed by a shard. Therefore, when there is a high number of tenants, the memory consumption of async replication can be significant. (e.g. 1,000 tenants with a hash tree height of 16 will require an extra ~2 GB of memory per node, while a height of 20 will require ~34 GB per node).
To reduce memory consumption, reduce the hash tree height. Keep in mind that this will result in slower hashing and potentially slower replication.
Use the following formulas and examples as a quick reference:
Memory calculation
Total number of nodes in the hash tree: For a hash tree with height
H, the total number of nodes is:Number of hash tree nodes = 2^(H+1) - 1 ≈ 2^(H+1)Total memory required (per shard/tenant on each node): Each hash tree node uses approximately 16 bytes of memory.
Memory Required ≈ 2^(H+1) * 16 bytes
Examples
Hash tree with height
16:Total hash tree nodes ≈ 2^(16+1) = 131,072Memory required ≈ 131072 * 16 bytes ≈ 2,097,152 bytes (~2 MB)
Hash tree with height
20:Total hash tree nodes ≈ 2^(20+1) = 2,097,152Memory required ≈ 2,097,152 * 16 bytes ≈ 33,554,432 bytes (~33 MB)
Performance Consideration: Number of Leaves
The objects in a shard (e.g. tenant) are distributed among the leaves of the hash tree. A larger hash tree means less data for each leaf to hash, leading to faster comparisons and faster replication.
- Number of Leaves in the hash tree:
Number of leaves = 2^H
Examples
Hash tree with height
16:Number of Leaves = 2^16 = 65,536
Hash tree with height
20:Number of Leaves = 2^20 = 1,048,576
The default hash tree height of 16 is chosen to balance memory consumption with replication performance. Adjust this value based on your cluster node’s available resources and performance requirements.
Deletion resolution strategies
v1.28When an object is present on some replicas but not others, this can be because a creation has not yet been propagated to all replicas, or because a deletion has not yet been propagated to all replicas. It is important to distinguish between these two cases.
Deletion resolution works alongside async replication and repair-on-read to ensure consistent handling of deleted objects across the cluster. For each collection, you can set one of the following deletion resolution strategies:
NoAutomatedResolutionDeleteOnConflictTimeBasedResolution
Deletion resolution strategies are mutable. Read more about how to update collection definitions.
NoAutomatedResolution
This is the default setting, and the only setting available in Weaviate versions prior to v1.28. In this mode, Weaviate does not treat deletion conflicts as a special case. If an object is present on some replicas but not others, Weaviate may potentially restore the object on the replicas where it is missing.
DeleteOnConflict
A deletion conflict in deleteOnConflict is always resolved by deleting the object on all replicas.
To do so, Weaviate updates an object as a deleted object on a replica upon receiving a deletion request, rather than removing all traces of the object.
TimeBasedResolution
A deletion conflict in timeBasedResolution is resolved based on the timestamp of the deletion request, in comparison to any subsequent updates to the object such as a creation or an update.
If the deletion request has a timestamp that is later than the timestamp of any subsequent updates, the object is deleted on all replicas. If the deletion request has a timestamp that is earlier than the timestamp of any subsequent updates, the later updates are applied to all replicas.
For example:
- If an object is deleted at timestamp 100 and then recreated at timestamp 90, the recreation wins
- If an object is deleted at timestamp 100 and then recreated at timestamp 110, the deletion wins
Choosing a strategy
- Use
NoAutomatedResolutionwhen you want maximum control and handle conflicts manually - Use
DeleteOnConflictwhen you want to ensure deletions are always honored - Use
TimeBasedResolutionwhen you want the most recent operation to take precedence
Repair-on-read
v1.18If your read consistency is set to All or Quorum, the read coordinator will receive responses from multiple replicas. If these responses differ, the coordinator can attempt to repair the inconsistency, as shown in the examples below. This process is called "repair-on-read", or "read repairs".
| Problem | Action |
|---|---|
| Object never existed on some replicas. | Propagate the object to the missing replicas. |
| Object is out of date. | Update the object on stale replicas. |
| Object was deleted on some replicas. | Returns an error. Deletion may have failed, or the object may have been partially recreated. |
The read repair process also depends on the read and write consistency levels used.
| Write consistency level | Read consistency level |
|---|---|
ONE | ALL |
QUORUM | QUORUM or ALL |
ALL | - |
Repairs only happen on read, so they do not create a lot of background overhead. While nodes are in an inconsistent state, read operations with consistency level of ONE may return stale data.
Related pages
Questions and feedback
If you have any questions or feedback, let us know in the user forum.