
Replication Architecture
v1.17Weaviate allows data replication across a multi-node cluster by setting a replication factor > 1. This enables a variety of benefits such as high availability. Database replication improves reliability, scalability, and/or performance.
Weaviate utilizes multiple replication architectures:
- Cluster metadata replication is managed by the Raft consensus algorithm.
- Data replication is tunable and leaderless.
What is the cluster metadata?
Weaviate cluster metadata includes collection definitions and tenant activity statuses.
All cluster metadata is always replicated across all nodes, regardless of the replication factor.
Note that this is different to object metadata, such as the object creation time. Object metadata is stored alongside the object data according to the specified replication factor.
In this Replication Architecture section, you will find information about:
- General Concepts, on this page
- What is replication?
- CAP Theorem
- Why replication for Weaviate?
- Replication vs. Sharding
- How does replication work in Weaviate?
- Roadmap
- Use Cases
- Motivation
- High Availability
- Increased (Read) Throughput
- Zero Downtime Upgrades
- Regional Proximity
- Philosophy
- Typical Weaviate use cases
- Reasons for a leaderless architecture
- Gradual rollout
- Large-scale testing
- Cluster Architecture
- Leaderless design
- Replication Factor
- Write and Read operations
- Consistency
- Cluster metadata
- Data objects
- Repairs
- Multi-DataCenter
- Regional Proximity
What is replication?
Database replication refers to keeping a copy of the same data point on multiple nodes of a cluster.
The resulting system is a distributed database. A distributed database consists of multiple nodes, all of which can contain a copy of the data. So if one node (server) goes down, users can still access data from another node. In addition, query throughput can be improved with replication.
CAP Theorem
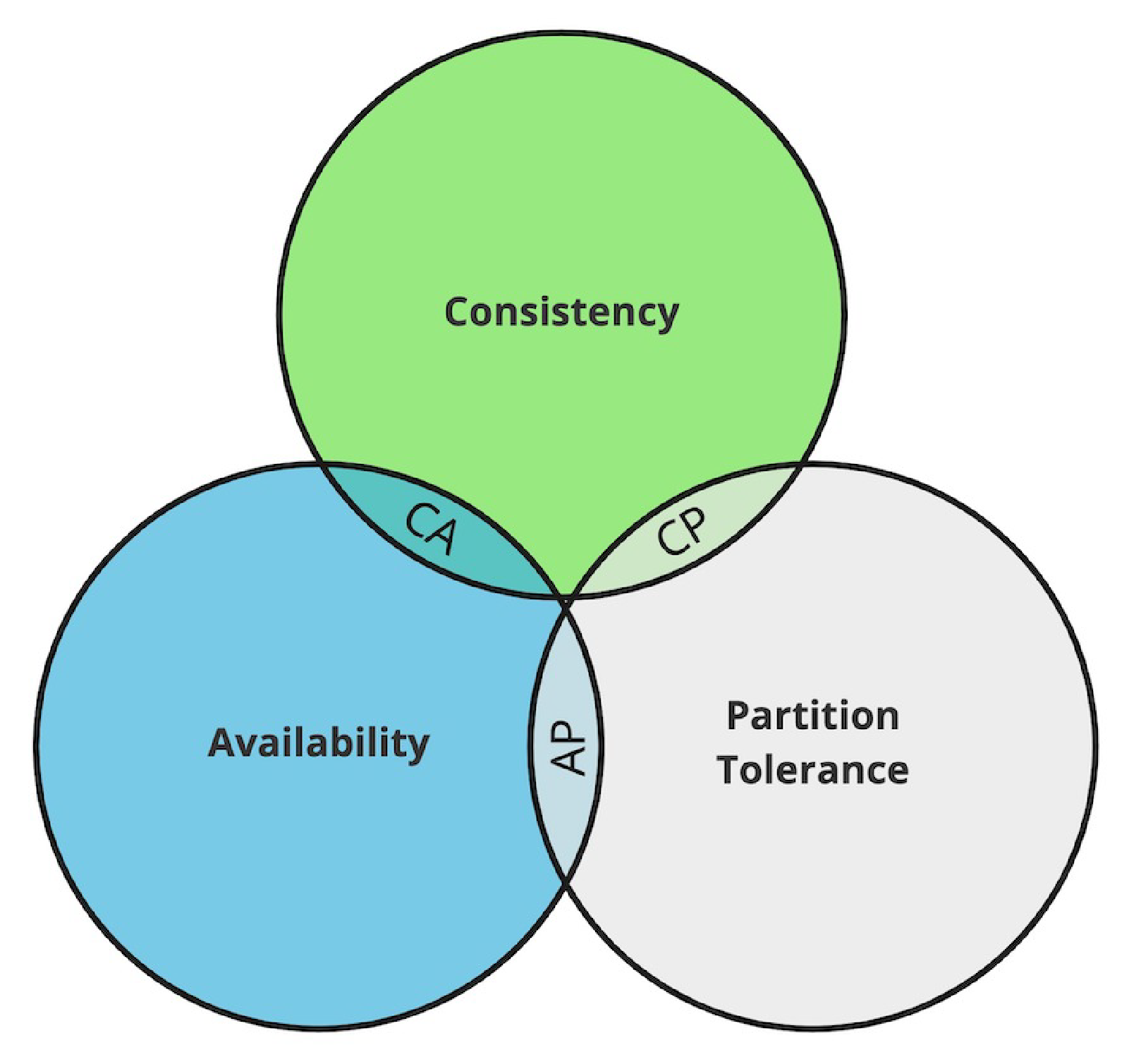
The primary goal of introducing replication is to improve reliability. Eric Brewer states that there are some limits on reliability for distributed databases, described by the CAP theorem. The CAP theorem states that a distributed database can only provide two of the following three guarantees:
- Consistency (C) - Every read receives the most recent write or an error, ensuring all nodes see the same data at the same time.
- Availability (A) - Every request receives a non-error response all the time, without the guarantee that it contains the most recent write.
- Partition tolerance (P) - The system continues to operate despite an arbitrary number of messages being dropped (or delayed) by the network between nodes.
Ideally, you want a database, like Weaviate, to have the highest reliability as possible, but this is limited by the tradeoff between consistency, availability and partition tolerance.
Consistency vs Availability
Only two out of Consistency (C), Availability (A), and Partition tolerance (P) can be guaranteed simultaneously
Given that partition tolerance is required, consider which of the other two are more important for your system.
Only two out of consistency, availability, and partition tolerance can be guaranteed. Since by definition a cluster is a distributed system in which network partitions are present, only two options are left for designing the system: consistency (C) or availability (A).
When you prioritize consistency over availability, the database will return an error or timeout when it cannot be guaranteed that the data is up to date due to network partitioning. When prioritizing availability over consistency, the database will always process the query and try to return the most recent version of data even if it cannot guarantee it is up to date due to network partitioning.
C over A is preferred when the database contains critical data, such as transactional bank account data. For transactional data, you want the data to always be consistent (otherwise your bank balance is not guaranteed to be correct if you make transactions while some nodes (e.g. ATMs) are down).
When a database involves less-critical data, A over C can be preferred. An example can be a messaging service, where you can tolerate showing some old data but the application should be highly available and handle large amounts of writes with minimal latency.
Weaviate generally follows this latter design, since Weaviate typically deals with less critical data and is used for approximate search as a secondary database in use cases with more critical data. More about this design decision in Philosophy. However, you can use Weaviate's tunable consistency options according to your needs.
Why replication for Weaviate?
Weaviate, as a database, must provide reliable answers to users' requests. As discussed above, database reliability consists of various parts. Below are Weaviate use cases in which replication is desired. For detailed information, visit the Replication Use Cases (Motivation) page.
- High availability (redundancy)
With a distributed (replicated) database structure, service will not be interrupted if one server node goes down. The database can still be available, read queries will just be (unnoticeably) redirected to an available node. - Increased (read) throughput
Adding extra server nodes to your database setup means that the throughput scales with it. The more server nodes, the more users (read operations) the system will be able to handle. When reading with consistency level ofONE, then scaling the replication factor (i.e. how many database server nodes) increases the throughput linearly. - Zero downtime upgrades
Without replication, there is a window of downtime when you update a Weaviate instance. This is because the single node needs to stop, update and restart before it's ready to serve again. With replication, upgrades are done using a rolling update, in which at most one node is unavailable at any point in time while the other nodes can still serve traffic. - Regional proximity
When users are located in different regional areas (e.g. Iceland and Australia as extreme examples), you cannot ensure low latency for all users due to the physical distance between the database server and the users. With a distributed database, you can place nodes in different local regions to decrease this latency. This depends on the Multi-Datacenter feature of replication.
Replication vs. Sharding
Replication is not the same as sharding. Sharding refers to horizontal scaling, and was introduced to Weaviate in v1.8.
- Replication copies the data to different server nodes. For Weaviate, this increases data availability and provides redundancy in case a single node fails. Query throughput can be improved with replication.
- Sharding handles horizontal scaling across servers by dividing the data and sending the pieces of data (shards) to multiple replica sets. The data is thus divided, and all shards together form the entire set of data. You can use sharding with Weaviate to run larger datasets and speed up imports.
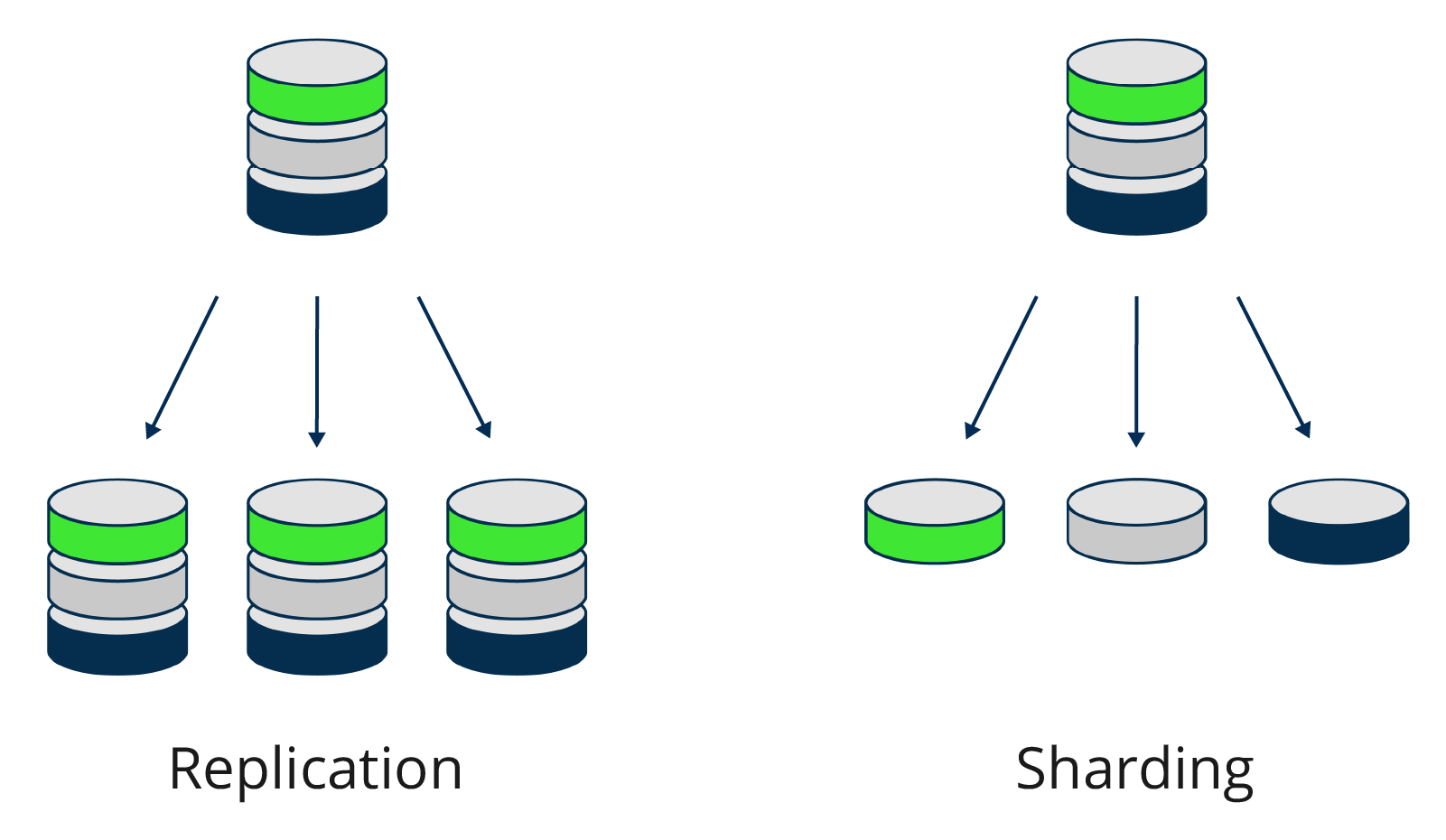
Replication and sharding can be combined in a setup, to improve throughput and availability as well as import speed and support for large datasets. For example, you can have 3 replicas of the database and shards set to 3, which means you have 9 shards in total, where each server node holds 3 different shards.
How does replication work in Weaviate?
Cluster metadata replication
Weaviate’s cluster metadata changes are managed through Raft to provide consistency across the cluster. (This includes collection definitions and tenant activity statuses.)
From Weaviate v1.25, cluster metadata changes are committed using the Raft consensus algorithm. Raft is a leader-based consensus algorithm. A leader node is responsible for cluster metadata changes. Raft ensures that these changes are consistent across the cluster, even in the event of (a minority of) node failures.
Metadata replication pre-v1.25
Prior to Weaviate v1.25, each cluster metadata change was recorded via a distributed transaction with a two-phase commit.
This is a synchronous process, which means that the cluster metadata change is only committed when all nodes have acknowledged the change. In this architecture, any node downtime would temporarily prevent metadata operations. Additionally, only one such operation could be processed at a time.
If you are using Weaviate v1.24 or earlier, you can upgrade to v1.25 to benefit from the Raft consensus algorithm for cluster metadata changes.
Data replication
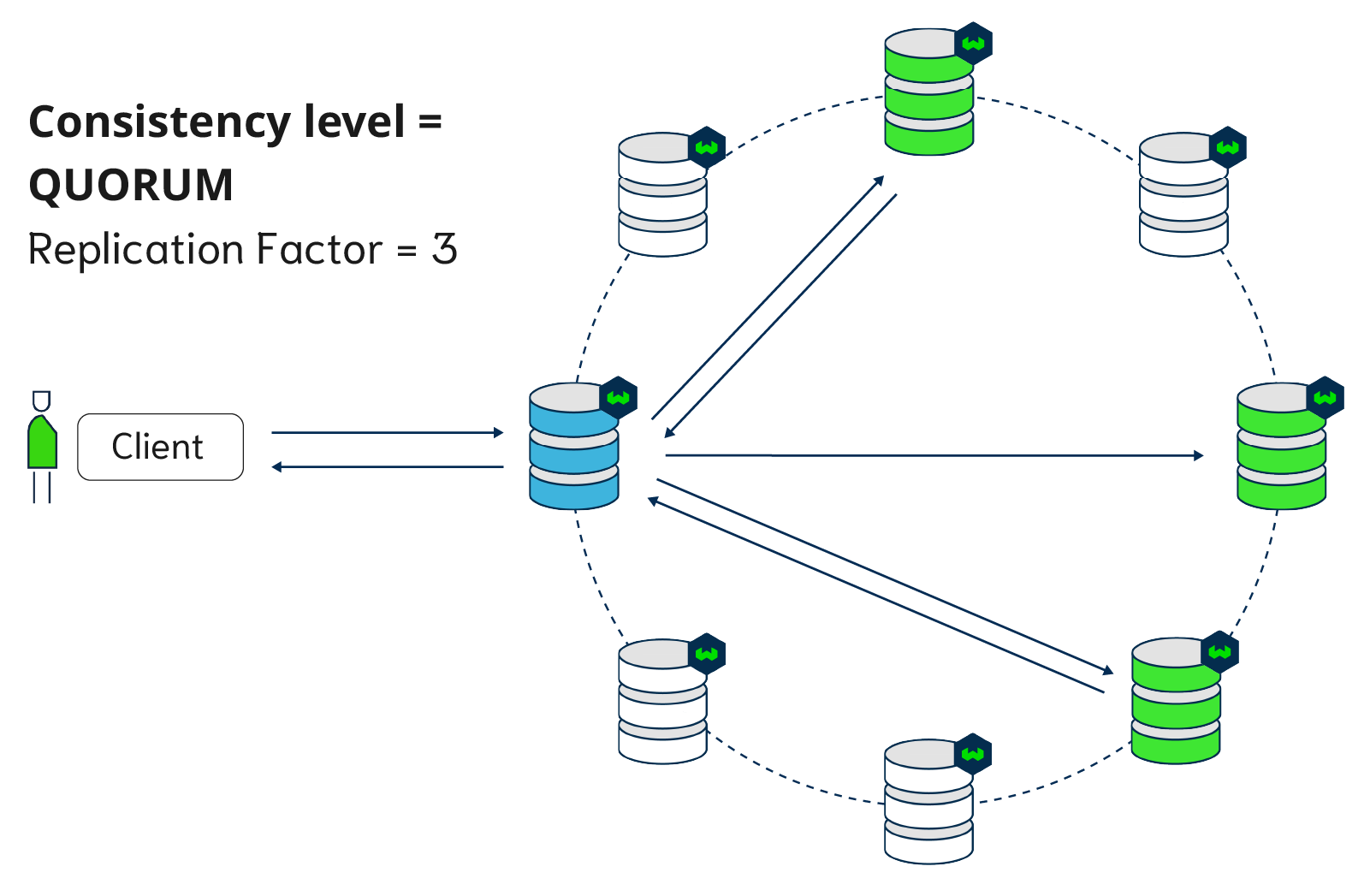
In Weaviate, availability is generally favored over consistency. Weaviate's data replication uses a leaderless design, which means there are no primary and secondary nodes. When writing and reading data, the client contacts one or more nodes. A load balancer exists between the user and the nodes, so the user doesn't know which node they are talking to (Weaviate will forward internally if a user is requesting a wrong node).
The number of nodes that need to acknowledge the read or write (from v1.18) operation is tunable, to ONE, QUORUM (n/2+1) or ALL. When write operations are carried out with consistency level ALL, the database works synchronously. If write is not set to ALL (possible from v1.18), writing data is asynchronous from the user's perspective.
The number of replicas doesn't have to match the number of nodes (cluster size). It is possible to split data in Weaviate based on collections. Note that this is different from Sharding.
Read more about how replication works in Weaviate in Philosophy, Cluster Architecture and Consistency.
How do I use replication in Weaviate?
See how to configure replication. You can enable replication in the collection definition. In queries, you can specify the desired consistency level.
Roadmap
- Not scheduled yet
- Multi-Datacenter replication (you can upvote this feature here)
Related pages
Questions and feedback
If you have any questions or feedback, let us know in the user forum.