
Locally Hosted Transformers Reranker Models with Weaviate
Weaviate's integration with the Hugging Face Transformers library allows you to access their models' capabilities directly from Weaviate.
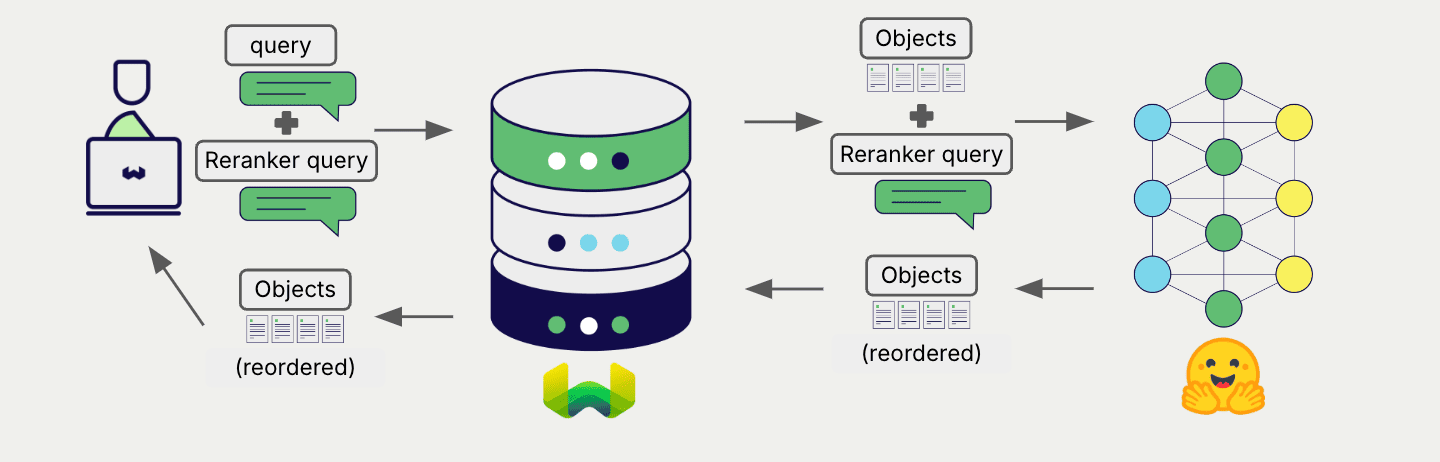
Configure a Weaviate collection to use Transformers integration, and configure the Weaviate instance with a model image, and Weaviate will use the specified model in the Transformers inference container to rerank search results.
This two-step process involves Weaviate first performing a search and then reranking the results using the specified model.
Requirements
Weaviate configuration
Your Weaviate instance must be configured with the Transformers reranker integration (reranker-transformers) module.
For Weaviate Cloud (WCD) users
This integration is not available for Weaviate Cloud (WCD) serverless instances, as it requires spinning up a container with the Hugging Face model.
Enable the integration module
- Check the cluster metadata to verify if the module is enabled.
- Follow the how-to configure modules guide to enable the module in Weaviate.
Configure the integration
To use this integration, configure the container image of the Hugging Face Transformers model and the inference endpoint of the containerized model.
The following example shows how to configure the Hugging Face Transformers integration in Weaviate:
- Docker
- Kubernetes
Docker Option 1: Use a pre-configured docker-compose.yml file
Follow the instructions on the Weaviate Docker installation configurator to download a pre-configured docker-compose.yml file with a selected model
Docker Option 2: Add the configuration manually
Alternatively, add the configuration to the docker-compose.yml file manually as in the example below.
services:
weaviate:
# Other Weaviate configuration
environment:
RERANKER_INFERENCE_API: http://reranker-transformers:8080 # Set the inference API endpoint
reranker-transformers: # Set the name of the inference container
image: cr.weaviate.io/semitechnologies/reranker-transformers:cross-encoder-ms-marco-MiniLM-L-6-v2
environment:
ENABLE_CUDA: 0 # Set to 1 to enable
RERANKER_INFERENCE_APIenvironment variable sets the inference API endpointreranker-transformersis the name of the inference containerimageis the container imageENABLE_CUDAenvironment variable enables GPU usage
Set image from a list of available models to specify a particular model to be used.
Configure the Hugging Face Transformers integration in Weaviate by adding or updating the reranker-transformers module in the modules section of the Weaviate Helm chart values file. For example, modify the values.yaml file as follows:
modules:
reranker-transformers:
enabled: true
tag: cross-encoder-ms-marco-MiniLM-L-6-v2
repo: semitechnologies/reranker-transformers
registry: cr.weaviate.io
envconfig:
enable_cuda: true
See the Weaviate Helm chart for an example of the values.yaml file including more configuration options.
Set tag from a list of available models to specify a particular model to be used.
Credentials
As this integration runs a local container with the transformers model, no additional credentials (e.g. API key) are required. Connect to Weaviate as usual, such as in the examples below.
- Python API v4
- JS/TS API v3
import weaviate
from weaviate.classes.init import Auth
import os
headers = {
}
client = weaviate.connect_to_weaviate_cloud(
cluster_url=weaviate_url, # `weaviate_url`: your Weaviate URL
auth_credentials=Auth.api_key(weaviate_key), # `weaviate_key`: your Weaviate API key
headers=headers
)
# Work with Weaviate
client.close()
import weaviate from 'weaviate-client'
const client = await weaviate.connectToWeaviateCloud(
'WEAVIATE_INSTANCE_URL', // Replace with your instance URL
{
authCredentials: new weaviate.ApiKey('WEAVIATE_INSTANCE_APIKEY'),
headers: {
}
}
)
// Work with Weaviate
client.close()
Configure the reranker
v1.25.23, v1.26.8 and v1.27.1A collection's reranker model integration configuration is mutable from v1.25.23, v1.26.8 and v1.27.1. See this section for details on how to update the collection configuration.
Configure a Weaviate collection to use a Transformer reranker model as follows:
- Python API v4
- JS/TS API v3
from weaviate.classes.config import Configure
client.collections.create(
"DemoCollection",
reranker_config=Configure.Reranker.transformers()
# Additional parameters not shown
)
await client.collections.create({
name: 'DemoCollection',
reranker: weaviate.configure.reranker.transformers(),
});
To chose a model, select the container image that hosts it.
Reranking query
Once the reranker is configured, Weaviate performs reranking operations using the specified reranker model.
More specifically, Weaviate performs an initial search, then reranks the results using the specified model.
Any search in Weaviate can be combined with a reranker to perform reranking operations.
- Python API v4
- JS/TS API v3
from weaviate.classes.query import Rerank
collection = client.collections.get("DemoCollection")
response = collection.query.near_text(
query="A holiday film", # The model provider integration will automatically vectorize the query
limit=2,
rerank=Rerank(
prop="title", # The property to rerank on
query="A melodic holiday film" # If not provided, the original query will be used
)
)
for obj in response.objects:
print(obj.properties["title"])
let myCollection = client.collections.get('DemoCollection');
const results = await myCollection.query.nearText(
['A holiday film'],
{
limit: 2,
rerank: {
property: 'title', // The property to rerank on
query: 'A melodic holiday film' // If not provided, the original query will be used
}
}
);
for (const obj of results.objects) {
console.log(obj.properties['title']);
}
References
Available models
cross-encoder/ms-marco-MiniLM-L-6-v2cross-encoder/ms-marco-MiniLM-L-2-v2cross-encoder/ms-marco-TinyBERT-L-2-v2
These pre-trained models are open-sourced on Hugging Face. The cross-encoder/ms-marco-MiniLM-L-6-v2 model, for example, provides approximately the same benchmark performance as the largest model (L-12) when evaluated on MS-MARCO (39.01 vs. 39.02).
We add new model support over time. For a complete list of available models, see the Docker Hub tags for the reranker-transformers container.
Further resources
Other integrations
Code examples
Once the integrations are configured at the collection, the data management and search operations in Weaviate work identically to any other collection. See the following model-agnostic examples:
- The how-to: manage data guides show how to perform data operations (i.e. create, update, delete).
- The how-to: search guides show how to perform search operations (i.e. vector, keyword, hybrid) as well as retrieval augmented generation.
Questions and feedback
If you have any questions or feedback, let us know in the user forum.